Manipulação de objetos em R
Manipulação de objetos
Leitura/Importação
Você pode importar um data.frame para o R de duas formas. A primeira delas, é carregando através do Environment no canto direito superior do RStudio. Clique em Import Dataset e selecione ‘From Text File’
O RStudio solicitará que você selecione o arquivo que deseja importar e, em seguida, abrirá um assistente para ajudá-lo a importar os dados. Use o assistente para informar ao RStudio qual nome dar ao conjunto de dados. Você também pode usar o assistente para informar ao RStudio qual caractere o conjunto de dados usa como separador, qual caractere ele usa para representar decimais (geralmente um ponto nos Estados Unidos e uma vírgula na Europa/Brasil) e se o conjunto de dados vem ou não com uma linha de nomes de coluna (conhecida como cabeçalho). Para ajudá-lo, o assistente mostra a aparência do arquivo bruto, bem como a aparência dos dados carregados com base nas configurações de entrada.
Você também pode desmarcar a caixa “Strings como fatores” no assistente. Eu recomendo fazer isso. Se você fizer isso, o R carregará todas as suas cadeias de caracteres como cadeias de caracteres. Caso contrário, R os converterá em fatores.
A outra forma de importar um arquivo no R, é usando direto no script a função ‘read.csv’. Vamos trabalhar com os dados da pnad, no arquivo amostra_pnad.csv. Ele é um arquivo de valores separados por vírgula ou CSV para abreviar. CSVs são arquivos de texto simples, o que significa que você pode abri-los em um editor de texto (assim como em muitos outros programas). Se você abrir amostra_pnad.csv, verá que ele contém uma tabela de dados semelhante à seguinte. Cada linha da tabela é salva em sua própria linha e uma vírgula é usada para separar as células dentro de cada linha. Cada arquivo CSV compartilha este formato básico:
“Ano”,“Trimestre”,“UF”,“V1022”,“V2007”,“V2009”,“V2010”,“VD2003”,“VD3005”,“VD4016” “2021”,“1”,“Ceará”,“Urbana”,“Homem”,80,“Branca”,2,“16 anos ou mais de estudo”,NA “2021”,“1”,“Distrito Federal”,“Urbana”,“Mulher”,19,“Parda”,4,“11 anos de estudo”,NA …e assim por diante
Vamos carregar novamente os dados da pnad que foram mostrados na aula passada:
url <- "https://raw.githubusercontent.com/laddem/site/master/amostra_pnad.csv"
df <- read.csv(url)
head(df)
## Ano Trimestre UF V1022 V2007 V2009 V2010 VD2003
## 1 2021 1 Ceará Urbana Homem 80 Branca 2
## 2 2021 1 Distrito Federal Urbana Mulher 19 Parda 4
## 3 2021 1 Pernambuco Urbana Mulher 36 Preta 2
## 4 2021 1 Santa Catarina Urbana Homem 50 Parda 2
## 5 2021 1 São Paulo Urbana Mulher 43 Parda 3
## 6 2021 1 Goiás Urbana Homem 35 Parda 3
## VD3005 VD4016
## 1 16 anos ou mais de estudo NA
## 2 11 anos de estudo NA
## 3 12 anos de estudo 1045
## 4 5 anos de estudo 1500
## 5 9 anos de estudo 1600
## 6 14 anos de estudo 3000
Se a importação ocorrer corretamente, o data.frame irá aparecer no ambiente Environment mostrando o número de observações e o número de variáveis (colunas).
Quando você importa um conjunto de dados, o RStudio salva os dados em um data frame e, em seguida, exibe o data frame em uma guia Exibir. Você pode abrir qualquer data frame em uma guia Exibir a qualquer momento com a função View().
Exercícios
Visualize os dados que você acabou de importar em formato de planilha através do Environment e usando a função View(). É possível também visualizar as 6 primeiras linhas do data.frame ou as 6 últimas linhas. Para isso, use as funções head() e tail().
Obs: se você quiser ver mais que 6 linhas, coloque o segundo argumento na função head(df, 10). Quantas linhas vão ser mostradas neste caso?
Escrita/Salvar
Você pode salvar e exportar um novo arquivo .csv para o seu computador. Assim, você pode enviá-lo por e-mail a um colega, armazená-lo em um pen drive ou abri-lo em um programa diferente. Você pode salvar quaisquer dados executados e alterados no R em um arquivo .csv com o comando write.csv.
write.csv(df, file = "df_pnad.csv", row.names = FALSE)
R transformará seu data frame em um arquivo de texto simples com o formato de valores separados por vírgula e salvará o arquivo em seu diretório de trabalho. Para ver onde está seu diretório de trabalho, execute getwd(). Para alterar a localização do seu diretório de trabalho, visite Sessão > Definir Diretório de Trabalho > Escolher Diretório na barra de menus do RStudio.
Você pode personalizar o processo de salvamento com o grande conjunto de argumentos opcionais de write.csv (consulte ?write.csv para obter detalhes). No entanto, existem três argumentos que você deve usar sempre que executar write.csv.
Primeiro, você deve fornecer a função write.csv o nome do data frame que deseja salvar. Em seguida, você deve fornecer um nome de arquivo para dar ao seu arquivo. R entenderá esse nome literalmente, portanto, certifique-se de fornecer uma extensão.
Finalmente, você deve adicionar o argumento row.names = FALSE. Isso impedirá R de adicionar uma coluna de números no início do seu data frame. Esses números identificarão suas linhas de 1 a 1000, mas é improvável que qualquer programa em que você abrir df_pnad.csv compreenderá o sistema de nomes de linhas. Muito provavelmente, o programa assumirá que os nomes das linhas são a primeira coluna de dados em seu data frame. Na verdade, isso é exatamente o que R assumirá se você reabrir df_pnad.csv. Se você salvar e abrir df_pnad.csv várias vezes em R, notará colunas duplicadas de números de linha se formando no início de seu data frame. Não posso explicar por que R faz isso, mas posso explicar como evitá-lo: use row.names = FALSE sempre que salvar dados com write.csv.
Notação
Para que você consiga trabalhar com valores individuais dentro do seu data frame, tarefa necessária em análise de dados, você pode selecionar valores dentro de um objeto R através do seu sistema de notação.
Selecionando valores
O R tem um sistema de notação que permite extrair valores de objetos R. Para extrair um valor ou conjunto de valores de um data frame, escreva o nome do data frame seguido por um par de colchetes:
df[ , ]
## Ano Trimestre UF V1022 V2007 V2009 V2010 VD2003
## 1 2021 1 Ceará Urbana Homem 80 Branca 2
## 2 2021 1 Distrito Federal Urbana Mulher 19 Parda 4
## 3 2021 1 Pernambuco Urbana Mulher 36 Preta 2
## 4 2021 1 Santa Catarina Urbana Homem 50 Parda 2
## 5 2021 1 São Paulo Urbana Mulher 43 Parda 3
## 6 2021 1 Goiás Urbana Homem 35 Parda 3
## 7 2021 1 Amapá Urbana Homem 72 Parda 3
## 8 2021 1 São Paulo Urbana Mulher 23 Amarela 8
## 9 2021 1 Distrito Federal Urbana Homem 23 Parda 5
....
Saída truncada para visualização
Entre os colchetes estarão dois índices separados por uma vírgula. Os índices dizem ao R quais valores retornar. O R usará o primeiro índice para o subconjunto das linhas do dataframe e o segundo índice para o subconjunto das colunas. Ou seja, df[linhas, colunas].
Você pode pensar em um índice como um CEP ou o endereço de um valor ou um conjunto de valores, e a indexação como o processo que você utilizaria para encontrar um desses valores numa lista telefônica, no Google ou no Maps.
Você tem uma escolha quando se trata de escrever índices. Existem seis maneiras diferentes de escrever um índice para o R e cada uma faz algo ligeiramente diferente. Eles são todos muito simples e muito úteis, então vamos dar uma olhada em cada um deles. Você pode criar índices com:
- Inteiros positivos
- Inteiros negativos
- Zero
- Espaços em branco
- Valores lógicos
- Nomes
O mais simples de usar são os inteiros positivos.
Por exemplo, caso você queira extrair um valor que está na primeira linha e na quarta coluna do seu data frame, no caso, estamos usando o df, que é uma pequena amostra da pnad, lembra? Como podemos fazer isso?
df[1, 4]
## [1] "Urbana"
Para extrair mais de um valor, use um vetor com inteiros positivos. Por exemplo, se você quer retornar a primeira linha de df com df[1, c(1,2,3)] ou df[1, 1:3]
df[1,1:3]
## Ano Trimestre UF
## 1 2021 1 Ceará
df[1, c(1,2,3)]
## Ano Trimestre UF
## 1 2021 1 Ceará
Essa notação não é limitada somente a objetos do tipo data frame. Você pode usar a mesma sintaxe para selecionar valores em qualquer objeto R, desde que você forneça um índice para cada dimensão do objeto. Então, por exemplo, você pode definir um subconjunto de um vetor (que tem uma dimensão) com um único índice:
vec <- c(10, 15, 31, 60, 10, 2)
vec[1:3]
## [1] 10 15 31
Bom, isso é a notação usando usando inteiros positivos. Como seria com inteiros negativos? Quais as diferenças?
Vamos lá!
Os inteiros negativos fazem exatamente o oposto dos inteiros positivos durante a indexação. O R retornará todos os elementos, exceto os elementos em um índice negativo. Por exemplo, df[-1, 1:10] retornará tudo, exceto a primeira linha do data frame. df[-(2:999), 1:10] retornará a primeira linha e a última linha (e excluirá todo o resto):
df[-(2:999), 1:10]
## Ano Trimestre UF V1022 V2007 V2009 V2010 VD2003
## 1 2021 1 Ceará Urbana Homem 80 Branca 2
## 1000 2021 1 Santa Catarina Rural Homem 66 Branca 2
## VD3005 VD4016
## 1 16 anos ou mais de estudo NA
## 1000 5 anos de estudo 1000
df[-1, 9]
## [1] "11 anos de estudo"
## [2] "12 anos de estudo"
## [3] "5 anos de estudo"
## [4] "9 anos de estudo"
## [5] "14 anos de estudo"
## [6] "16 anos ou mais de estudo"
## [7] "12 anos de estudo"
## [8] "14 anos de estudo"
## [9] "5 anos de estudo"
## [10] "9 anos de estudo"
....
Saída truncada para visualização
A vantagem de usar inteiros negativos ao invés de inteiros positivos na indexação, é que os inteiros negativos são uma maneira mais eficiente de criar um subconjunto do que os inteiros positivos, se você quiser incluir a maioria das linhas ou colunas de um data frame.
Na notação df[-2,2] o que irá ser mostrado pelo R?
O que acontecerá se você usar o zero como um índice? Zero não é um inteiro positivo nem um inteiro negativo, mas ele ainda usará para fazer um tipo de subconjunto. O R, neste caso, não retornará nada de uma dimensão quando você usa zero como um índice:
df[0, 0]
## data frame with 0 columns and 0 rows
Pra ser sincera, indexar com 0 não ajuda em muita coisa.
Além dos inteiros positivos, inteiros negativos, e zero, você pode também usar espaços em branco na indexação. O espaço em branco no R vai extrair todos os valores em uma dimensão. Isso permite subdividir um objeto em uma dimensão, mas não nas outras, o que é útil para extrair linhas ou colunas inteiras de um data frame:
df[1, ]
## Ano Trimestre UF V1022 V2007 V2009 V2010 VD2003
## 1 2021 1 Ceará Urbana Homem 80 Branca 2
## VD3005 VD4016
## 1 16 anos ou mais de estudo NA
df[, 5]
## [1] "Homem" "Mulher" "Mulher" "Homem" "Mulher" "Homem" "Homem" "Mulher"
## [9] "Homem" "Homem" "Homem" "Homem" "Homem" "Mulher" "Mulher" "Mulher"
## [17] "Mulher" "Mulher" "Mulher" "Mulher" "Mulher" "Mulher" "Homem" "Mulher"
## [25] "Homem" "Mulher" "Mulher" "Homem" "Mulher" "Mulher" "Homem" "Homem"
## [33] "Mulher" "Homem" "Mulher" "Homem" "Homem" "Homem" "Mulher" "Mulher"
## [41] "Mulher" "Mulher" "Mulher" "Homem" "Homem" "Mulher" "Homem" "Homem"
## [49] "Mulher" "Mulher" "Homem" "Homem" "Mulher" "Homem" "Mulher" "Mulher"
## [57] "Mulher" "Homem" "Homem" "Homem" "Homem" "Homem" "Homem" "Mulher"
## [65] "Mulher" "Homem" "Mulher" "Homem" "Homem" "Homem" "Mulher" "Mulher"
## [73] "Homem" "Homem" "Mulher" "Mulher" "Homem" "Homem" "Mulher" "Mulher"
....
Saída truncada para visualização
Estamos quase chegando no final dos tipos de indexação que são possíveis de serem feitas no R.
No caso de valores lógicos, se você fornecer um vetor de TRUEs e FALSEs como seu índice, o R combinará cada TRUE e FALSE com uma linha do data frame (ou uma coluna, dependendo de onde você colocar o índice). O R então retornará cada linha que corresponde a um TRUE.
Pode ser útil imaginar R lendo o data frame e perguntando: “Devo retornar a enésima linha da estrutura de dados?” e depois consultar o enésimo valor do índice para obter sua resposta. Para que este sistema funcione, seu vetor deve ser tão longo quanto a dimensão que você está tentando subdividir:
df[1, c(TRUE, TRUE, FALSE)]
## Ano Trimestre V1022 V2007 V2010 VD2003 VD4016
## 1 2021 1 Urbana Homem Branca 2 NA
rows <- c(F, TRUE, TRUE, F, F, F, F, F, F, F, F, F, F, F, F, F,
F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F,
F, F, F, F, F, F, F, F, F, F, F, F, F, F)
df[rows, ]
## Ano Trimestre UF V1022 V2007 V2009 V2010 VD2003
## 2 2021 1 Distrito Federal Urbana Mulher 19 Parda 4
## 3 2021 1 Pernambuco Urbana Mulher 36 Preta 2
## 54 2021 1 Rondônia Urbana Homem 44 Branca 2
## 55 2021 1 Espírito Santo Urbana Mulher 45 Branca 4
## 106 2021 1 Minas Gerais Rural Homem 31 Parda 3
## 107 2021 1 São Paulo Urbana Homem 14 Branca 4
## 158 2021 1 Alagoas Urbana Homem 38 Parda 1
## 159 2021 1 Amapá Urbana Mulher 20 Parda 3
## 210 2021 1 Roraima Urbana Homem 55 Parda 6
....
Saída truncada para visualização
Esse sistema será de grande ajuda na parte de modificação de valores que veremos daqui a pouco.
Finalmente, você pode pedir os elementos que deseja pelo nome - se o seu objeto tiver nomes (consulte Nomes). Essa é uma maneira comum de extrair as colunas de um data frame, já que as colunas quase sempre têm um nome:
names(df)
## [1] "Ano" "Trimestre" "UF" "V1022" "V2007" "V2009"
## [7] "V2010" "VD2003" "VD3005" "VD4016"
df[3, c("UF", "V2007", "V2010")]
## UF V2007 V2010
## 3 Pernambuco Mulher Preta
df[ , "VD3005"]
## [1] "16 anos ou mais de estudo"
## [2] "11 anos de estudo"
## [3] "12 anos de estudo"
## [4] "5 anos de estudo"
## [5] "9 anos de estudo"
## [6] "14 anos de estudo"
## [7] "16 anos ou mais de estudo"
## [8] "12 anos de estudo"
## [9] "14 anos de estudo"
## [10] "5 anos de estudo"
....
Saída truncada para visualização
Exercícios
Retorne a informação da observação 800, e as colunas Ano, VD3005, V2009, V2010 do nosso data frame da amostra da pnad. O que o R retornará? Faça a mesma indexação usando inteiros positivos ou inteiros negativos.
Diferentes seleções: [[ e $
Dois tipos de objeto em R obedecem a um segundo sistema opcional de notação. Você pode extrair valores de data frames e listas com a sintaxe $. Você encontrará a sintaxe $ repetidamente no R, então vamos examinar como ela funciona.
Para selecionar uma coluna de um data frame, escreva o nome do data frame, no caso df, e o nome da coluna separados por $. Observe que nenhuma aspa deve estar no nome da coluna:
df$V2009
## [1] 80 19 36 50 43 35 72 23 23 47 71 16 48 13 25 3 27 83
## [19] 55 79 14 80 20 21 22 69 57 27 63 35 28 41 39 71 7 45
## [37] 11 9 48 14 48 47 5 36 25 55 8 64 7 58 30 1 18 44
## [55] 45 17 9 24 11 11 71 75 49 20 55 31 60 2 7 81 68 15
## [73] 31 2 44 40 49 55 9 40 55 0 35 32 7 63 62 54 48 5
## [91] 46 49 20 90 16 0 41 15 67 26 22 18 58 63 0 31 14 39
## [109] 34 44 61 48 47 29 43 65 10 36 20 7 28 18 23 75 37 49
## [127] 45 3 61 54 38 50 41 47 39 44 32 27 66 55 70 69 41 31
## [145] 38 91 62 30 21 59 4 29 5 24 83 6 15 38 20 89 85 44
## [163] 73 7 49 22 33 5 18 4 27 22 0 21 74 26 58 52 77 36
....
Saída truncada para visualização
O R retornará todos os valores da coluna como um vetor. Esta notação $ é muito útil e muito usada porque você freqüentemente armazenará as variáveis de seus conjuntos de dados como colunas em um data frame. De vez em quando, você desejará executar uma função como mean() ou median() nos valores de uma variável. Em R, essas funções esperam um vetor de valores como entrada, e o df$V2009 entrega seus dados no formato certo:
mean(df$V2009)
## [1] 36.939
Você pode usar a mesma notação com $ com os elementos de uma lista, se eles tiverem nomes. Essa notação também tem uma vantagem com listas. Se você criar um subconjunto de uma lista da maneira usual, o R retornará uma nova lista que contém os elementos solicitados, mesmo se você solicitar apenas um único elemento.
lista <- list(numbers = c(1, 2), logical = TRUE, strings = c("a", "b", "c"))
lista
## $numbers
## [1] 1 2
##
## $logical
## [1] TRUE
##
## $strings
## [1] "a" "b" "c"
lista[1]
## $numbers
## [1] 1 2
O resultado é uma lista menor com um elemento. Esse elemento é o vetor c(1, 2). Isso pode ser irritante porque muitas funções R não funcionam com listas. Por exemplo, sum(lst[1]) retornará um erro. Para você conseguir fazer uma operação com lista, você precisará usar $:
sum(lista$numbers)
## [1] 3
Se os elementos em sua lista não tiverem nomes (ou você não quiser usar os nomes), você pode usar dois colchetes [[ ]], em vez de um, para criar um subconjunto da lista. Essa notação fará a mesma coisa que a notação $:
lista[[1]]
## [1] 1 2
Em outras palavras, se você subdividir uma lista com a notação de colchete único, o R retornará uma lista menor. Se você subdividir uma lista com a notação de colchetes duplos, o R retornará apenas os valores que estavam dentro de um elemento da lista. Você pode combinar esse recurso com qualquer um dos métodos de indexação de R:
lista["numbers"]
## $numbers
## [1] 1 2
lista[["numbers"]]
## [1] 1 2
Essa diferença é sutil, mas importante. Na comunidade R, há uma maneira popular e útil de pensar sobre isso. Imagine que cada lista é um trem e cada elemento é um vagão. Quando você usa colchetes simples, o R seleciona vagões de trem individuais e os retorna como um novo trem. Cada vagão mantém seu conteúdo, mas esse conteúdo ainda está dentro de um vagão de trem (ou seja, uma lista). Quando você usa colchetes duplos, o R realmente descarrega o carro e lhe devolve o conteúdo. Resumindo:
Use colchetes simples para selecionar vagões de trem e colchetes duplos para selecionar o conteúdo dentro de um vagão.
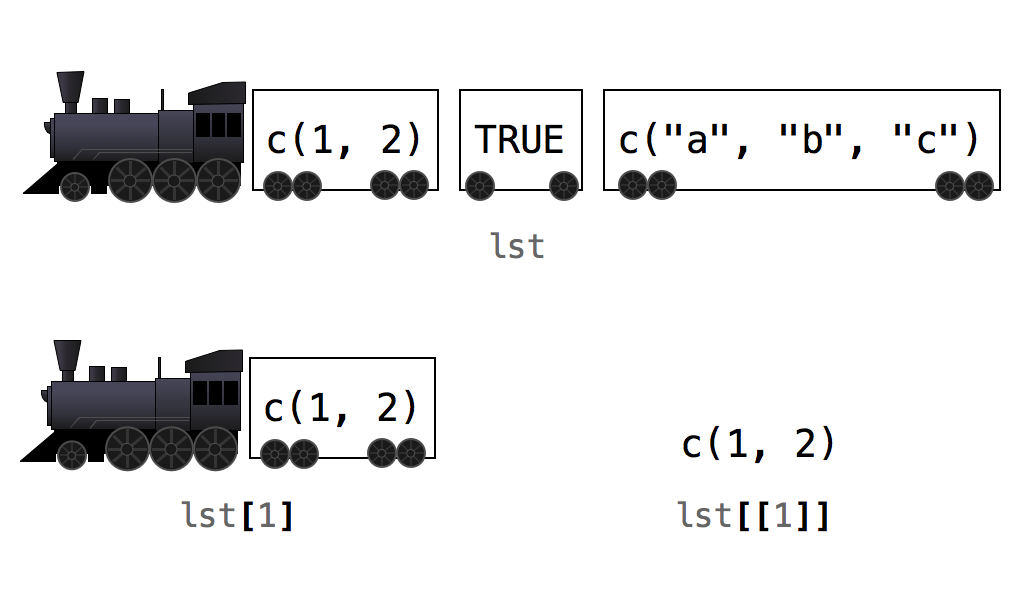
Exercícios
Assim como na lista, é possível usar os colchetes [[ ]] em data frame. Tente usá-los no data frame da pnad. Quais são as diferenças encontradas?
Modificando valores
Para manipular os valores dentro do seu data frame, faça primeiro uma cópia que você pode manipular. Isso garantirá que você sempre tenha uma cópia original do data frame para usar (caso as coisas dêem errado):
df2 <- df
Modificando os valores diretamente
Você pode usar o sistema de notação de R para modificar valores dentro de um objeto. Primeiro, descreva o valor (ou valores) que você deseja modificar. Em seguida, use o operador de atribuição <- para sobrescrever esses valores. O R irá atualizar os valores selecionados no objeto original. Em um exemplo real:
vetor <- c(0, 0, 0, 0, 0, 0)
vetor
## [1] 0 0 0 0 0 0
Você pode selecionar um valor dentro desse vetor· Neste caso selecionamos o primeiro:
vetor[1]
## [1] 0
E aqui, podemos modificar o valor:
vetor[1] <- 35
vetor
## [1] 35 0 0 0 0 0
Você pode substituir vários valores de uma vez, desde que o número de novos valores seja igual ao número de valores selecionados:
vetor[c(3, 4, 5)] <- c(1, 1, 1)
vetor
## [1] 35 0 1 1 1 0
vetor[4:6] <- vetor[4:6] + 1
vetor
## [1] 35 0 1 2 2 1
Você também pode criar valores que ainda não existem em seu objeto. O R irá expandir o objeto para acomodar os novos valores:
vetor[7] <- 20
vetor
## [1] 35 0 1 2 2 1 20
Isto é uma ótima maneira de adicionar novas variáveis ao data frame:
df2$nova_coluna <- 1:1000
head(df2)
## Ano Trimestre UF V1022 V2007 V2009 V2010 VD2003
## 1 2021 1 Ceará Urbana Homem 80 Branca 2
## 2 2021 1 Distrito Federal Urbana Mulher 19 Parda 4
## 3 2021 1 Pernambuco Urbana Mulher 36 Preta 2
## 4 2021 1 Santa Catarina Urbana Homem 50 Parda 2
## 5 2021 1 São Paulo Urbana Mulher 43 Parda 3
## 6 2021 1 Goiás Urbana Homem 35 Parda 3
## VD3005 VD4016 nova_coluna
## 1 16 anos ou mais de estudo NA 1
## 2 11 anos de estudo NA 2
## 3 12 anos de estudo 1045 3
## 4 5 anos de estudo 1500 4
## 5 9 anos de estudo 1600 5
## 6 14 anos de estudo 3000 6
Da mesma forma que você criou uma nova coluna, é possível removê-la atribuindo o valor NULL
df2$nova_coluna <- NULL
head(df2)
## Ano Trimestre UF V1022 V2007 V2009 V2010 VD2003
## 1 2021 1 Ceará Urbana Homem 80 Branca 2
## 2 2021 1 Distrito Federal Urbana Mulher 19 Parda 4
## 3 2021 1 Pernambuco Urbana Mulher 36 Preta 2
## 4 2021 1 Santa Catarina Urbana Homem 50 Parda 2
## 5 2021 1 São Paulo Urbana Mulher 43 Parda 3
## 6 2021 1 Goiás Urbana Homem 35 Parda 3
## VD3005 VD4016
## 1 16 anos ou mais de estudo NA
## 2 11 anos de estudo NA
## 3 12 anos de estudo 1045
## 4 5 anos de estudo 1500
## 5 9 anos de estudo 1600
## 6 14 anos de estudo 3000
Você pode selecionar um conjunto de linhas dentro de um data frame usando uma combinação dos sistemas de notação do R. Você pode destacar apenas os valores que você quer, definindo a dimensão das colunas do df2 com [. Ou, você pode definir um subconjunto da coluna df2$UF, misturando o $ com o [.
df2[c(5, 8, 39,44), ]
## Ano Trimestre UF V1022 V2007 V2009 V2010 VD2003
## 5 2021 1 São Paulo Urbana Mulher 43 Parda 3
## 8 2021 1 São Paulo Urbana Mulher 23 Amarela 8
## 39 2021 1 São Paulo Urbana Mulher 48 Branca 3
## 44 2021 1 São Paulo Urbana Homem 36 Branca 2
## VD3005 VD4016
## 5 9 anos de estudo 1600
## 8 12 anos de estudo 1200
## 39 12 anos de estudo 1200
## 44 16 anos ou mais de estudo NA
## selecionando linhas especificas e a coluna V2010
df2[c(5, 8, 39,44), 6]
## [1] 43 23 48 36
## podemos fazer o mesmo dessa forma
df2$V2009[c(5, 8, 39,44)]
## [1] 43 23 48 36
Suponha que você sabe que os valores dessas linhas na coluna V2009 estão errados e você precisa arrumá-los atribuindo novos valores. O conjunto de novos valores terá que ser do mesmo tamanho que o conjunto de valores que você está substituindo.
df2$V2009[c(5, 8, 39,44)] <- c(23, 23, 23, 23)
# ou
df2$V2009[c(5, 8, 39,44)]<- 23
head(df2, 44)
## Ano Trimestre UF V1022 V2007 V2009 V2010 VD2003
## 1 2021 1 Ceará Urbana Homem 80 Branca 2
## 2 2021 1 Distrito Federal Urbana Mulher 19 Parda 4
## 3 2021 1 Pernambuco Urbana Mulher 36 Preta 2
## 4 2021 1 Santa Catarina Urbana Homem 50 Parda 2
## 5 2021 1 São Paulo Urbana Mulher 23 Parda 3
## 6 2021 1 Goiás Urbana Homem 35 Parda 3
## 7 2021 1 Amapá Urbana Homem 72 Parda 3
## 8 2021 1 São Paulo Urbana Mulher 23 Amarela 8
## 9 2021 1 Distrito Federal Urbana Homem 23 Parda 5
....
Saída truncada para visualização
Observe que você está mudando os valores dos objetos salvos em df2, nos livros em inglês, isso é chamado de modify in place. Você não acaba com uma cópia modificada do df2; os novos valores aparecerão dentro do df2. É preciso fazer isso de forma consciente e segura, para não sobrescrever informações, por isso, recomendamos trabalhar com cópias do objeto original (df2 ao invés de df).
A mesma técnica funcionará se você armazenar seus dados em um vetor, matriz, array, lista ou data frame. Basta descrever os valores que você deseja alterar com o sistema de notação de R e, em seguida, atribuir esses valores com o operador de atribuição de R <-.
Exercícios
Considere o vetor abaixo. Atribua um novo valor na posição 3 deste vetor. É possível atribuir uma string no lugar de um número?
vetor_x<- c(10,30,50,10)
Modificando com testes lógicos
E se você precisa saber um valor específico e precise que o R te retorne a linha em que este valor está? Por que no caso anterior você sabia as linhas que você queria mudar, mas e quando o seu objeto é grande e você não sabe exatamente onde a informação se encontra? Como fazer?
Lembra do sistema de notação do R que permitia valores lógicos? Você pode deixar um teste lógico criar um vetor de TRUEs e FALSEs para você.
Um teste lógico é uma comparação como “um é menor que dois?”, 1 < 2 ou “três é maior que quatro?”, 3 > 4. O R fornece sete operadores lógicos que você pode usar para fazer comparações, e eles podem ser vistos na tabela abaixo.
Cada operador retorna TRUE ou FALSE. Se você usar um operador para comparar vetores, o R fará comparações entre elementos - assim como faz com os operadores aritméticos:
Table: Table 1: Operadores lógicos
| Operador | Sintaxe | Teste |
|---|---|---|
| > | a > b | a é maior que b? |
| >= | a >= b | a é maior ou igual a b? |
| < | a < b | a é menor que b? |
| <= | a <= b | a é menor ou igual a b? |
| == | a == b | a é igual a b? |
| != | a != b | a é diferente de b? |
| %in% | a %in% c(a, b, c) | a está contido em algum dos elementos de b? |
1 > 2
## [1] FALSE
1 > c(0, 1, 2)
## [1] TRUE FALSE FALSE
c(1, 2, 3) == c(3, 2, 1)
## [1] FALSE TRUE FALSE
O operador %in% é o único que não executa normalmente o elemento inteiro. %in% testa se os valores do lado esquerdo estão no vetor do lado direito. Se você fornecer um vetor no lado esquerdo, este operador não irá emparelhar os valores à esquerda com os valores à direita e, em seguida, fará testes de elementos. Em vez disso, ele testará independentemente se cada valor à esquerda está em algum lugar do vetor à direita:
1 %in% c(3, 4, 5)
## [1] FALSE
c(1, 2) %in% c(3, 4, 5)
## [1] FALSE FALSE
c(1, 2, 3) %in% c(3, 4, 5)
## [1] FALSE FALSE TRUE
c(1, 2, 3, 4) %in% c(3, 4, 5)
## [1] FALSE FALSE TRUE TRUE
Observe que você testa a igualdade com um sinal de igual duplo, ==, e não um único sinal de igual, =, que é outra maneira de escrever <-. É fácil esquecer e usar a = b para testar se a é igual a b. Infelizmente, você terá uma surpresa desagradável. O R não retornará TRUE ou FALSE, porque não terá que: a será igual a b, porque você acabou de executar o equivalente a a <- b.
Você pode comparar quaisquer dois objetos no R com um operador lógico; no entanto, os operadores lógicos fazem mais sentido se você comparar dois objetos do mesmo tipo de dados. Se você comparar objetos de diferentes tipos de dados, o R usará suas regras de coerção para forçar os objetos ao mesmo tipo antes de fazer a comparação.
Exercícios
Extraia a coluna V2010 do df2 e teste os valores igual a ‘Branca’. Além disso conte quantas linhas são iguais a ‘Branca’. Dica: use a função sum() para fazer a contagem.
Para resumir, você pode usar um teste lógico para selecionar valores dentro de um objeto.
O subconjunto lógico é uma técnica poderosa porque permite identificar, extrair e modificar rapidamente valores individuais em seu conjunto de dados. Ao trabalhar com subconjuntos lógicos, você não precisa saber onde existe um valor em seu conjunto de dados. Você só precisa saber como descrever o valor com um teste lógico.
Além dos operadores lógicos, também temos os operadores booleanos, os operadores booleanos são como & ou |. Eles reduzem os resultados de vários testes lógicos em um único TRUE ou FALSE. Os operadores e seus testes podem ser vistos na tabela abaixo.
Table: Table 2: Operadores booleanos
| Operador | Sintaxe | Teste |
|---|---|---|
| & | cond1 & cond2 | cond1 e cond2 são simultâneamente verdadeiros? |
| | | cond1 | cond2 | cond1 ou cond2 é verdadeiro? |
| xor | xor(cond1, cond2) | Apenas cond1 ou apenas cond2 é verdadeiro? |
| ! | !cond1 | Inverta o resultado de cond1 |
| any | any(cond1, cond2, cond3, …) | Algum resultado em c(cond1, cond2, cond3, …) é verdadeiro? |
| all | all(cond1, cond2, cond3, …) | Todos os resultados em c(cond1, cond2, cond3, …) são verdadeiros? |
Para usar um operador booleano, coloque-o entre dois testes lógicos completos. O R irá executar cada teste lógico e, em seguida, usar o operador booleano para combinar os resultados em um único TRUE ou FALSE.
Quando usados com vetores, os operadores booleanos seguirão a mesma execução elementar que os operadores aritméticos e lógicos:
a <- c(1, 2, 3)
b <- c(1, 2, 3)
c <- c(1, 2, 4)
a == b
## [1] TRUE TRUE TRUE
b == c
## [1] TRUE TRUE FALSE
a == b & b == c
## [1] TRUE TRUE FALSE
Você pode usar um operador booleano para localizar as pessoas de 40 anos e de escolaridade 9 anos de estudo no df2.
df2$V2009 == 40 & df2$VD3005 == "8 anos de estudo"
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [25] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [37] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [49] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [61] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [73] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [85] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [97] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [109] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
....
Saída truncada para visualização
Valores desconhecidos
Problemas com informações desconhecidas acontecem com frequência na análise de dados. Normalmente, eles são mais simples: você não sabe um valor porque a medição foi perdida, corrompida ou nunca feita para começar. O R tem uma maneira de ajudá-lo a gerenciar esses valores ausentes.
O caractere NA é um símbolo especial em R. Ele significa “não disponível” e pode ser usado como um espaço reservado para informações ausentes. O R tratará NA exatamente como você deseja que as informações ausentes sejam tratadas. Por exemplo, qual resultado você esperaria se adicionar 1 a uma informação ausente?
1 + NA
## [1] NA
O R retornará uma segunda informação faltante. Não seria correto dizer que 1 + NA = 1 porque há uma boa chance de que o valor ausente não seja zero. Você não tem informações suficientes para determinar o resultado.
NA == 1
## [1] NA
Valores ausentes podem ajudá-lo a contornar lacunas em seus conjuntos de dados, mas também podem criar alguns problemas frustrantes. Suponha, por exemplo, que você coletou 1.000 observações e deseja tirar sua média com a função mean(). Se um dos valores for NA, seu resultado será NA:
c(NA, 1:50)
## [1] NA 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
## [26] 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
## [51] 50
mean(c(NA, 1:50))
## [1] NA
A maioria das funções R vem com o argumento opcional, na.rm, que significa NA remove. o R irá ignorar NAs quando avaliar uma função se você adicionar o argumento na.rm = TRUE:
mean(c(NA, 1:50), na.rm = TRUE)
## [1] 25.5
Ocasionalmente, você pode querer identificar os NAs em seu conjunto de dados com um teste lógico, mas isso também cria um problema. Como você faria isso? Se algo for um valor ausente, qualquer teste lógico que o use retornará um valor ausente, até mesmo este teste:
NA == NA
## [1] NA
O que significa que testes como este não ajudarão você a encontrar valores ausentes:
c(1, 2, 3, NA) == NA
## [1] NA NA NA NA
O R fornece uma função especial que pode testar se um valor é um NA. A função é is.na:
is.na(NA)
## [1] TRUE
vet <- c(1, 2, 3, NA)
is.na(vet)
## [1] FALSE FALSE FALSE TRUE
Exercícios
Conte o número de NAs na coluna VD4016 do data frame df2.
Revisão
Na aula de hoje falamos sobre como importar dados, exportar dados, manipulação e diferentes notações para identificação de informações e modificação.
Para selecionar os valores em um data frame, ou em outro objeto R, aprendemos a usar a notação data.frame[ , ] e a partir dessa notação, selecionar diferentes linhas e colunas, usando números inteiros, números negativos, espaços em branco, valores lógicos e nomes.
Aprendemos com listas e dataframes a seleção pela notação de colchetes duplos [[ e $.
Em relação a modificação de valores, aprendemos a modificar os valores no local dentro de um objeto R ao combinar a sintaxe da notação de R com o operador de atribuição, <-. Isso permite que você atualize seus dados e limpe seus conjuntos de dados.
Aprendemos diferentes operadores lógicos: >; >=; <; <=; ==; !=; %in% e operadores booleanos: &; |; xor; !; any; all.
Quando você trabalha com grandes conjuntos de dados, modificar e recuperar valores cria um problema logístico próprio. Como você pode pesquisar os dados para encontrar os valores que deseja modificar ou recuperar? Como um usuário R, você pode fazer isso com subconjuntos lógicos. Crie um teste lógico com operadores lógicos e booleanos e, em seguida, use o teste como um índice na notação de colchetes de R. O R retornará os valores que você está procurando, mesmo se você não souber onde eles estão.
Exercícios
Para os próximos exercícios considere o data frame da pnad que estamos usando nas aulas.
-
Como você selecionaria o mesmo valor abaixo, mas usando inteiros negativos na seleção?
df2[1,5]## [1] "Homem" -
Qual a diferença em usar em selecionar determinada informação em um data frame usando colchetes duplos
[[]]e usando colchetes simples? Observe o exemplo abaixo para responder:df2[['Ano']]## [1] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ## [15] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ## [29] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ## [43] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ## [57] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ## [71] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ## [85] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ## [99] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ## [113] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 ## [127] 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 2021 .... Saída truncada para visualizaçãodf['Ano']## Ano ## 1 2021 ## 2 2021 ## 3 2021 ## 4 2021 ## 5 2021 ## 6 2021 ## 7 2021 ## 8 2021 ## 9 2021 .... Saída truncada para visualização -
Considere o data frame abaixo:
sala <- data.frame( id = c(1, 2, 3, 4, 5, 6), idade = c(20, 25, 30, 35, 40, 45), nome = c("Fulano", "Cicrano", "Beltrano", "Herculano", "Mariano", "Carrano"), sexo = "Masculino", origem = c("Campinas", "Barueri", "Monte Verde", "Rio de Janeiro", "Natal", "Belo Horizonte") )Modifique o nome de ‘Mariano’ por ‘Mariana’. E altere a variável sexo para que seja um vetor que altere o valor para ‘Feminino’ na posição em que o nome foi trocado para Mariana.
-
Considere o mesmo data frame sala construído no exercício anterior. Usando testes lógicos e operadores Booleanos. Verifique:
a. se existe algum aluno que seja do sexo Masculino e seja de São Paulo.
b. se existe algum aluno que tem idade maior ou igual a 20 anos ou que seja de Campinas. c. se existe alguém com o nome Beltrano. -
Agora considere o seguinte data frame e, usando as funções apropriadas ensinadas na aula de hoje, responda:
cadastro <- data.frame( id = c(10, 105, 299, 645, 7907, 8660, 4992, 630), idade = c(20, 25, 30, 35, 40, 45, 60, 53), nome = c("Thais", NA, "Guilherme", "Betânia", "Ana Lucia", NA, NA, "Pâmela"), sexo = c("Feminino", "Masculino","Masculino", NA ,NA, "Feminino", "Masculino", "Feminino"), origem = c("Campinas", NA, "Monte Verde", "Rio de Janeiro", NA, "Belo Horizonte","São Paulo", "Rio de Janeiro") )- Quantos NAs existe na coluna nome?
- Quantos NAs existe na coluna sexo?
- Quantos NAs existe na coluna origem?
- Substitua os NAs na coluna sexo pelo valor ‘Feminino’
-
Salve o data frame ‘cadastro’ do exercicio anterior em um arquivo
.csv. Como você faria isso? Quais os argumentos que devem ser usados?