stringr, forcats e dplyr
Operações em variáveis e bancos de dados
Hoje vamos apresentar dois pacotes com finalidades mais específicas para trabalhar com variáveis de tipo caractere e fator e um pacote super importante para as operações com bancos de dados.
O pacote stringr é uma série de adaptações da biblioteca stringi e serve para a manipulação de variáveis texto, incluindo funções para detecção, modificação, substituição, remoção de texto em variáveis caractere. Para dominar esse assunto, é necessário compreender o conceito de “regex,” ou “expressão regular,” que foge um pouco do escopo do curso, mas que será introduzido brevemente.
O pacote forcats contém uma série de funções para trabalhar com o tipo factor. São funções que facilitam operações envolvendo esse tipo de variável, como contagens, troca dos nomes das categorias, agrupamento de categorias, recodificação, plotagem, etc.
O pacote dplyr é um dos pilares do tidyverse e ele tem dois papéis principais: operações de manipulação de banco de dados simples e operações de bancos de dados relacionais. No primeiro tipo são incluídas as operações de criação e modificação de variáveis, medidas resumo globais e por grupos, seleção de variáveis, mudança da ordem das linhas e colunas, etc. No segundo tipo, são as operações de tipo _join, em que uma variável chave é utilizada para combinar registros de dois bancos de dados distintos.
Os pacotes stringr e forcats são mais diretos, mas o dplyr pode representar um certo nível de abstração que pode incomodar usuários de longa data do R, portanto, vamos nos esforçar para demonstrar as vantagens de mudar seu workflow para incluir as funções desse pacote através de comparações com o R base.
dplyr
dplyr para manipulação de dados
Talvez o pacote mais utilizado de todo o tidyverse, dplyr é um pacote de manipulação de bancos de dados inspirado pela linguagem SQL. A ideia é concatenar operações de seleção de variáveis, filtragem de observação, arranjo e ordenamento, derivação de variáveis, computação de medidas resumo para o banco todo ou para grupos. As funções básicas e mais utilizadas são, portanto:
selectfilterarrangemutatesummarizegroup_by
Para praticar, vamos usar o dataset flights, que contém informações sobre os vôos saídos de Nova Iorque em 2013.
library(nycflights13)
library(dplyr)
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
flights
## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 533 529 4 850 830
## 3 2013 1 1 542 540 2 923 850
## 4 2013 1 1 544 545 -1 1004 1022
## 5 2013 1 1 554 600 -6 812 837
## 6 2013 1 1 554 558 -4 740 728
## 7 2013 1 1 555 600 -5 913 854
## 8 2013 1 1 557 600 -3 709 723
## 9 2013 1 1 557 600 -3 838 846
## 10 2013 1 1 558 600 -2 753 745
## # ... with 336,766 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
glimpse(flights)
## Rows: 336,776
## Columns: 19
## $ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2~
## $ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1~
## $ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1~
## $ dep_time <int> 517, 533, 542, 544, 554, 554, 555, 557, 557, 558, 558, ~
## $ sched_dep_time <int> 515, 529, 540, 545, 600, 558, 600, 600, 600, 600, 600, ~
## $ dep_delay <dbl> 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, -2, -2, -1~
## $ arr_time <int> 830, 850, 923, 1004, 812, 740, 913, 709, 838, 753, 849,~
## $ sched_arr_time <int> 819, 830, 850, 1022, 837, 728, 854, 723, 846, 745, 851,~
## $ arr_delay <dbl> 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2, -3, 7, -1~
## $ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", "B6", "~
## $ flight <int> 1545, 1714, 1141, 725, 461, 1696, 507, 5708, 79, 301, 4~
## $ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN", "N394~
## $ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR", "LGA",~
## $ dest <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL", "IAD",~
## $ air_time <dbl> 227, 227, 160, 183, 116, 150, 158, 53, 140, 138, 149, 1~
## $ distance <dbl> 1400, 1416, 1089, 1576, 762, 719, 1065, 229, 944, 733, ~
## $ hour <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, 6, 6, 6~
## $ minute <dbl> 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0, 0, 59, 0~
## $ time_hour <dttm> 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2013-01-01 0~
Podemos filtrar nossas linhas: filter
# Voos de primeiro de janeiro
flights %>% filter(month == 1, day == 1)
## # A tibble: 842 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 533 529 4 850 830
## 3 2013 1 1 542 540 2 923 850
## 4 2013 1 1 544 545 -1 1004 1022
## 5 2013 1 1 554 600 -6 812 837
## 6 2013 1 1 554 558 -4 740 728
## 7 2013 1 1 555 600 -5 913 854
## 8 2013 1 1 557 600 -3 709 723
## 9 2013 1 1 557 600 -3 838 846
## 10 2013 1 1 558 600 -2 753 745
## # ... with 832 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos a partir de junho
flights %>% filter(month > 6)
## # A tibble: 170,618 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 10 1 447 500 -13 614 648
## 2 2013 10 1 522 517 5 735 757
## 3 2013 10 1 536 545 -9 809 855
## 4 2013 10 1 539 545 -6 801 827
## 5 2013 10 1 539 545 -6 917 933
## 6 2013 10 1 544 550 -6 912 932
## 7 2013 10 1 549 600 -11 653 716
## 8 2013 10 1 550 600 -10 648 700
## 9 2013 10 1 550 600 -10 649 659
## 10 2013 10 1 551 600 -9 727 730
## # ... with 170,608 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos saídos do aeroporto JFK
flights %>% filter(origin == "JFK")
## # A tibble: 111,279 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 542 540 2 923 850
## 2 2013 1 1 544 545 -1 1004 1022
## 3 2013 1 1 557 600 -3 838 846
## 4 2013 1 1 558 600 -2 849 851
## 5 2013 1 1 558 600 -2 853 856
## 6 2013 1 1 558 600 -2 924 917
## 7 2013 1 1 559 559 0 702 706
## 8 2013 1 1 606 610 -4 837 845
## 9 2013 1 1 611 600 11 945 931
## 10 2013 1 1 613 610 3 925 921
## # ... with 111,269 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos com destino ao aeroporto de Albuquerque
flights %>% filter(dest == "ABQ")
## # A tibble: 254 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 10 1 1955 2001 -6 2213 2248
## 2 2013 10 2 2010 2001 9 2230 2248
## 3 2013 10 3 1955 2001 -6 2232 2248
## 4 2013 10 4 2017 2001 16 2304 2248
## 5 2013 10 5 1959 1959 0 2226 2246
## 6 2013 10 6 1959 2001 -2 2234 2248
## 7 2013 10 7 2002 2001 1 2233 2248
## 8 2013 10 8 1957 2001 -4 2216 2248
## 9 2013 10 9 1957 2001 -4 2220 2248
## 10 2013 10 10 2011 2001 10 2235 2248
## # ... with 244 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos com atraso de até 10 minutos
flights %>% filter(dep_delay <= 10)
## # A tibble: 245,687 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 533 529 4 850 830
## 3 2013 1 1 542 540 2 923 850
## 4 2013 1 1 544 545 -1 1004 1022
## 5 2013 1 1 554 600 -6 812 837
## 6 2013 1 1 554 558 -4 740 728
## 7 2013 1 1 555 600 -5 913 854
## 8 2013 1 1 557 600 -3 709 723
## 9 2013 1 1 557 600 -3 838 846
## 10 2013 1 1 558 600 -2 753 745
## # ... with 245,677 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos com atraso de cerca de 10 minutos
flights %>% filter(near(dep_delay, 10, tol = 2))
## # A tibble: 8,677 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 611 600 11 945 931
## 2 2013 1 1 709 700 9 852 832
## 3 2013 1 1 826 817 9 1145 1158
## 4 2013 1 1 851 840 11 1215 1206
## 5 2013 1 1 1011 1001 10 1133 1128
## 6 2013 1 1 1208 1158 10 1540 1502
## 7 2013 1 1 1240 1229 11 1451 1428
## 8 2013 1 1 1310 1300 10 1559 1554
## 9 2013 1 1 1330 1321 9 1613 1536
## 10 2013 1 1 1511 1500 11 1753 1742
## # ... with 8,667 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos que ocorreram entre abril e maio
flights %>% filter(between(month, 4, 5))
## # A tibble: 57,126 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 4 1 454 500 -6 636 640
## 2 2013 4 1 509 515 -6 743 814
## 3 2013 4 1 526 530 -4 812 827
## 4 2013 4 1 534 540 -6 833 850
## 5 2013 4 1 542 545 -3 914 920
## 6 2013 4 1 543 545 -2 921 927
## 7 2013 4 1 551 600 -9 748 659
## 8 2013 4 1 552 600 -8 641 701
## 9 2013 4 1 553 600 -7 725 735
## 10 2013 4 1 554 600 -6 752 805
## # ... with 57,116 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
Podemos combinar várias condições usando operadores lógicos
# Voos até 15 de abril ou até 15 de maio
flights %>% filter(
between(month, 4, 5), # mesmo que usar &
between(day, 1, 15)
)
## # A tibble: 28,176 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 4 1 454 500 -6 636 640
## 2 2013 4 1 509 515 -6 743 814
## 3 2013 4 1 526 530 -4 812 827
## 4 2013 4 1 534 540 -6 833 850
## 5 2013 4 1 542 545 -3 914 920
## 6 2013 4 1 543 545 -2 921 927
## 7 2013 4 1 551 600 -9 748 659
## 8 2013 4 1 552 600 -8 641 701
## 9 2013 4 1 553 600 -7 725 735
## 10 2013 4 1 554 600 -6 752 805
## # ... with 28,166 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos entre 15 de abril e 15 de maio
flights %>% filter(
month == 4 & between(day, 15, 30) | # OU
month == 5 & between(day, 1, 15)
)
## # A tibble: 29,101 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 4 15 2 2359 3 341 339
## 2 2013 4 15 453 500 -7 639 640
## 3 2013 4 15 511 515 -4 741 802
## 4 2013 4 15 527 530 -3 806 813
## 5 2013 4 15 527 529 -2 750 743
## 6 2013 4 15 537 540 -3 846 840
## 7 2013 4 15 542 545 -3 931 927
## 8 2013 4 15 551 600 -9 728 758
## 9 2013 4 15 552 600 -8 835 850
## 10 2013 4 15 552 600 -8 648 701
## # ... with 29,091 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos em todas os primeiros 7 dias de cada mês, exceto em janeiro e dezembro
flights %>% filter(
between(day, 1, 7),
!month %in% c(1, 12)
)
## # A tibble: 64,365 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 10 1 447 500 -13 614 648
## 2 2013 10 1 522 517 5 735 757
## 3 2013 10 1 536 545 -9 809 855
## 4 2013 10 1 539 545 -6 801 827
## 5 2013 10 1 539 545 -6 917 933
## 6 2013 10 1 544 550 -6 912 932
## 7 2013 10 1 549 600 -11 653 716
## 8 2013 10 1 550 600 -10 648 700
## 9 2013 10 1 550 600 -10 649 659
## 10 2013 10 1 551 600 -9 727 730
## # ... with 64,355 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos saidos de JFK, excluindo aqueles para os quais não tem informações de horário de saída
flights %>% filter(
origin == "JFK", !is.na(dep_time)
)
## # A tibble: 109,416 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 542 540 2 923 850
## 2 2013 1 1 544 545 -1 1004 1022
## 3 2013 1 1 557 600 -3 838 846
## 4 2013 1 1 558 600 -2 849 851
## 5 2013 1 1 558 600 -2 853 856
## 6 2013 1 1 558 600 -2 924 917
## 7 2013 1 1 559 559 0 702 706
## 8 2013 1 1 606 610 -4 837 845
## 9 2013 1 1 611 600 11 945 931
## 10 2013 1 1 613 610 3 925 921
## # ... with 109,406 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Voos com mais de 30 minutos de atraso em janeiro ou dezembro
flights %>% filter(
dep_delay > 30, xor(month == 1, month == 12)
)
## # A tibble: 8,221 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 732 645 47 1011 941
## 2 2013 1 1 749 710 39 939 850
## 3 2013 1 1 811 630 101 1047 830
## 4 2013 1 1 826 715 71 1136 1045
## 5 2013 1 1 848 1835 853 1001 1950
## 6 2013 1 1 903 820 43 1045 955
## 7 2013 1 1 909 810 59 1331 1315
## 8 2013 1 1 953 921 32 1320 1241
## 9 2013 1 1 957 733 144 1056 853
## 10 2013 1 1 1025 951 34 1258 1302
## # ... with 8,211 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
E assim sucessivamente.
Da mesma forma, temos select para selecionar as variáveis do banco. As duas grandes novidades são que você não precisa utilizar aspas na seleção de variáveis e que select introduz várias helper functions para facilitar a seleção de variáveis parecidas.
# Selecionar as colunas ano, mes, dia, horario de saida e horario de chegada
flights %>% select(year, month, day, dep_time, arr_time)
## # A tibble: 336,776 x 5
## year month day dep_time arr_time
## <int> <int> <int> <int> <int>
## 1 2013 1 1 517 830
## 2 2013 1 1 533 850
## 3 2013 1 1 542 923
## 4 2013 1 1 544 1004
## 5 2013 1 1 554 812
## 6 2013 1 1 554 740
## 7 2013 1 1 555 913
## 8 2013 1 1 557 709
## 9 2013 1 1 557 838
## 10 2013 1 1 558 753
## # ... with 336,766 more rows
# Utilizando helpers
flights %>% select(year:dep_time, arr_time)
## # A tibble: 336,776 x 5
## year month day dep_time arr_time
## <int> <int> <int> <int> <int>
## 1 2013 1 1 517 830
## 2 2013 1 1 533 850
## 3 2013 1 1 542 923
## 4 2013 1 1 544 1004
## 5 2013 1 1 554 812
## 6 2013 1 1 554 740
## 7 2013 1 1 555 913
## 8 2013 1 1 557 709
## 9 2013 1 1 557 838
## 10 2013 1 1 558 753
## # ... with 336,766 more rows
# Mais helpers
flights %>% select(year:day, starts_with("dep"), starts_with("arr"))
## # A tibble: 336,776 x 7
## year month day dep_time dep_delay arr_time arr_delay
## <int> <int> <int> <int> <dbl> <int> <dbl>
## 1 2013 1 1 517 2 830 11
## 2 2013 1 1 533 4 850 20
## 3 2013 1 1 542 2 923 33
## 4 2013 1 1 544 -1 1004 -18
## 5 2013 1 1 554 -6 812 -25
## 6 2013 1 1 554 -4 740 12
## 7 2013 1 1 555 -5 913 19
## 8 2013 1 1 557 -3 709 -14
## 9 2013 1 1 557 -3 838 -8
## 10 2013 1 1 558 -2 753 8
## # ... with 336,766 more rows
flights %>% select(year:day, ends_with("time"))
## # A tibble: 336,776 x 8
## year month day dep_time sched_dep_time arr_time sched_arr_time air_time
## <int> <int> <int> <int> <int> <int> <int> <dbl>
## 1 2013 1 1 517 515 830 819 227
## 2 2013 1 1 533 529 850 830 227
## 3 2013 1 1 542 540 923 850 160
## 4 2013 1 1 544 545 1004 1022 183
## 5 2013 1 1 554 600 812 837 116
## 6 2013 1 1 554 558 740 728 150
## 7 2013 1 1 555 600 913 854 158
## 8 2013 1 1 557 600 709 723 53
## 9 2013 1 1 557 600 838 846 140
## 10 2013 1 1 558 600 753 745 138
## # ... with 336,766 more rows
flights %>% select(year:day, c(ends_with("time")) & !contains("sched"))
## # A tibble: 336,776 x 6
## year month day dep_time arr_time air_time
## <int> <int> <int> <int> <int> <dbl>
## 1 2013 1 1 517 830 227
## 2 2013 1 1 533 850 227
## 3 2013 1 1 542 923 160
## 4 2013 1 1 544 1004 183
## 5 2013 1 1 554 812 116
## 6 2013 1 1 554 740 150
## 7 2013 1 1 555 913 158
## 8 2013 1 1 557 709 53
## 9 2013 1 1 557 838 140
## 10 2013 1 1 558 753 138
## # ... with 336,766 more rows
# Você pode mudar o nome das colunas durante um call para select
flights %>% select(ano = year, mes = month, dia = day)
## # A tibble: 336,776 x 3
## ano mes dia
## <int> <int> <int>
## 1 2013 1 1
## 2 2013 1 1
## 3 2013 1 1
## 4 2013 1 1
## 5 2013 1 1
## 6 2013 1 1
## 7 2013 1 1
## 8 2013 1 1
## 9 2013 1 1
## 10 2013 1 1
## # ... with 336,766 more rows
# Ou você pode usar rename para mudar os nomes sem selecionar variáveis
flights %>% rename(ano = year, mes = month, dia = day)
## # A tibble: 336,776 x 19
## ano mes dia dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 533 529 4 850 830
## 3 2013 1 1 542 540 2 923 850
## 4 2013 1 1 544 545 -1 1004 1022
## 5 2013 1 1 554 600 -6 812 837
## 6 2013 1 1 554 558 -4 740 728
## 7 2013 1 1 555 600 -5 913 854
## 8 2013 1 1 557 600 -3 709 723
## 9 2013 1 1 557 600 -3 838 846
## 10 2013 1 1 558 600 -2 753 745
## # ... with 336,766 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
São realmente muitas possibilidades, vejam a documentação e os exemplos em ?select.
Utilizando arrange podemos facilmente organizar nosso banco a partir de variáveis de interesse:
# Selecionar algumas variáveis e ver organizar de acordar com os mais adiantados
flights %>%
select(year:day,matches("^dep|^arr")) %>%
arrange(dep_delay, arr_delay)
## # A tibble: 336,776 x 7
## year month day dep_time dep_delay arr_time arr_delay
## <int> <int> <int> <int> <dbl> <int> <dbl>
## 1 2013 12 7 2040 -43 40 48
## 2 2013 2 3 2022 -33 2240 -58
## 3 2013 11 10 1408 -32 1549 -10
## 4 2013 1 11 1900 -30 2233 -10
## 5 2013 1 29 1703 -27 1947 -10
## 6 2013 8 9 729 -26 1002 7
## 7 2013 3 30 2030 -25 2213 -37
## 8 2013 10 23 1907 -25 2143 0
## 9 2013 5 5 934 -24 1225 -44
## 10 2013 9 18 1631 -24 1812 -33
## # ... with 336,766 more rows
# Ou os mais atrasados
flights %>%
select(year:day,matches("^dep|^arr")) %>%
arrange(-dep_delay, -arr_delay)
## # A tibble: 336,776 x 7
## year month day dep_time dep_delay arr_time arr_delay
## <int> <int> <int> <int> <dbl> <int> <dbl>
## 1 2013 1 9 641 1301 1242 1272
## 2 2013 6 15 1432 1137 1607 1127
## 3 2013 1 10 1121 1126 1239 1109
## 4 2013 9 20 1139 1014 1457 1007
## 5 2013 7 22 845 1005 1044 989
## 6 2013 4 10 1100 960 1342 931
## 7 2013 3 17 2321 911 135 915
## 8 2013 6 27 959 899 1236 850
## 9 2013 7 22 2257 898 121 895
## 10 2013 12 5 756 896 1058 878
## # ... with 336,766 more rows
É basicamente isso, você pode especificar uma ou muitas colunas para organizar, decidir se a ordem é ascendente ou descendente e pronto.
Utilizando mutate, você cria variáveis derivadas das originais. Como tibble, essa função avalia seus argumentos de maneira preguiçosa e sequencial, o que permite você criar variáveis derivadas umas das outras muito facilmente.
flights %>%
select(sched_dep_time, dep_time, sched_arr_time, arr_time) %>%
mutate(atraso_decolagem = dep_time - sched_dep_time,
atraso_pouso = arr_time - sched_arr_time,
atraso_dec_horas = atraso_decolagem / 60,
atraso_pouso_horas = atraso_pouso / 60)
## # A tibble: 336,776 x 8
## sched_dep_time dep_time sched_arr_time arr_time atraso_decolagem atraso_pouso
## <int> <int> <int> <int> <int> <int>
## 1 515 517 819 830 2 11
## 2 529 533 830 850 4 20
## 3 540 542 850 923 2 73
## 4 545 544 1022 1004 -1 -18
## 5 600 554 837 812 -46 -25
## 6 558 554 728 740 -4 12
## 7 600 555 854 913 -45 59
## 8 600 557 723 709 -43 -14
## 9 600 557 846 838 -43 -8
## 10 600 558 745 753 -42 8
## # ... with 336,766 more rows, and 2 more variables: atraso_dec_horas <dbl>,
## # atraso_pouso_horas <dbl>
# Transmute é um atalho para quando você quer apenas as variáveis resultado e não está interessado nas intermediárias.
flights %>%
transmute(atraso_decolagem = dep_time - sched_dep_time,
atraso_pouso = arr_time - sched_arr_time,
atraso_dec_horas = atraso_decolagem / 60,
atraso_pouso_horas = atraso_pouso / 60)
## # A tibble: 336,776 x 4
## atraso_decolagem atraso_pouso atraso_dec_horas atraso_pouso_horas
## <int> <int> <dbl> <dbl>
## 1 2 11 0.0333 0.183
## 2 4 20 0.0667 0.333
## 3 2 73 0.0333 1.22
## 4 -1 -18 -0.0167 -0.3
## 5 -46 -25 -0.767 -0.417
## 6 -4 12 -0.0667 0.2
## 7 -45 59 -0.75 0.983
## 8 -43 -14 -0.717 -0.233
## 9 -43 -8 -0.717 -0.133
## 10 -42 8 -0.7 0.133
## # ... with 336,766 more rows
Usando o pipe, é fazer diversas operações de transformação de variáveis simultâneamente em um único call sem a necessidade de repetir o nome do objeto e $ a cada referência. mutate é uma função extremamente flexível, você pode chamar qualquer função que retorne um vetor de tamanho 1 ou de tamanho do número de linhas do banco lá dentro para criar uma variável.
desabafo <- function(x) {
y <- floor(x / 60)
dplyr::case_when(
# Condições ~ Resultados
y < 0 ~ "Opa, vou chegar cedo!",
y < 1 ~ "Atraso de menos de 1 hora é tolerável",
y >= 1 ~ paste0("Atraso de mais de ", y, " horas é f***."),
TRUE ~ "Ahn?" # Condição guarda-chuva
)
}
flights %>%
select(dep_delay) %>%
mutate(desabafo = desabafo(dep_delay)) %>%
sample_n(10)
## # A tibble: 10 x 2
## dep_delay desabafo
## <dbl> <chr>
## 1 -5 Opa, vou chegar cedo!
## 2 23 Atraso de menos de 1 hora é tolerável
## 3 -4 Opa, vou chegar cedo!
## 4 -3 Opa, vou chegar cedo!
## 5 -8 Opa, vou chegar cedo!
## 6 -3 Opa, vou chegar cedo!
## 7 -5 Opa, vou chegar cedo!
## 8 22 Atraso de menos de 1 hora é tolerável
## 9 23 Atraso de menos de 1 hora é tolerável
## 10 -2 Opa, vou chegar cedo!
Utilizando summarize você tira medidas resumo das suas colunas de interesse:
flights %>%
summarize(atraso_decolagem_medio = mean(dep_delay, na.rm = T),
atraso_decolagem_desvpad = sd(dep_delay, na.rm = T),
atraso_pouso_medio = mean(arr_delay, na.rm = T),
atraso_pouso_desvpad = sd(arr_delay, na.rm = T),
n_voos = n())
## # A tibble: 1 x 5
## atraso_decolagem_~ atraso_decolagem_~ atraso_pouso_me~ atraso_pouso_de~ n_voos
## <dbl> <dbl> <dbl> <dbl> <int>
## 1 12.6 40.2 6.90 44.6 336776
Parece uma bobagem, mas quando você junta isso com a última função, group_by, é possível obter diversas estatísticas de interesse muito rapidamente e para vários domínios:
# Por mês
flights %>%
group_by(month) %>%
summarize(atraso_decolagem_medio = mean(dep_delay, na.rm = T),
atraso_decolagem_desvpad = sd(dep_delay, na.rm = T),
atraso_pouso_medio = mean(arr_delay, na.rm = T),
atraso_pouso_desvpad = sd(arr_delay, na.rm = T),
n_voos = n())
## # A tibble: 12 x 6
## month atraso_decolagem_~ atraso_decolagem_~ atraso_pouso_me~ atraso_pouso_de~
## <int> <dbl> <dbl> <dbl> <dbl>
## 1 1 10.0 36.4 6.13 40.4
## 2 2 10.8 36.3 5.61 39.5
## 3 3 13.2 40.1 5.81 44.1
## 4 4 13.9 43.0 11.2 47.5
## 5 5 13.0 39.4 3.52 44.2
## 6 6 20.8 51.5 16.5 56.1
## 7 7 21.7 51.6 16.7 57.1
## 8 8 12.6 37.7 6.04 42.6
## 9 9 6.72 35.6 -4.02 39.7
## 10 10 6.24 29.7 -0.167 32.6
## 11 11 5.44 27.6 0.461 31.4
## 12 12 16.6 41.9 14.9 46.1
## # ... with 1 more variable: n_voos <int>
# Por mês e aeroporto de origem
flights %>%
group_by(month, origin) %>%
summarize(atraso_decolagem_medio = mean(dep_delay, na.rm = T),
atraso_decolagem_desvpad = sd(dep_delay, na.rm = T),
atraso_pouso_medio = mean(arr_delay, na.rm = T),
atraso_pouso_desvpad = sd(arr_delay, na.rm = T),
n_voos = n())
## `summarise()` has grouped output by 'month'. You can override using the `.groups` argument.
## # A tibble: 36 x 7
## # Groups: month [12]
## month origin atraso_decolagem_medio atraso_decolagem_desvp~ atraso_pouso_med~
## <int> <chr> <dbl> <dbl> <dbl>
## 1 1 EWR 14.9 40.8 12.8
## 2 1 JFK 8.62 36.0 1.37
## 3 1 LGA 5.64 29.7 3.38
## 4 2 EWR 13.1 37.2 8.78
## 5 2 JFK 11.8 37.4 4.39
## 6 2 LGA 6.96 33.4 3.15
## 7 3 EWR 18.1 44.1 10.6
## 8 3 JFK 10.7 35.3 2.58
## 9 3 LGA 10.2 39.7 3.74
## 10 4 EWR 17.4 43.9 14.1
## # ... with 26 more rows, and 2 more variables: atraso_pouso_desvpad <dbl>,
## # n_voos <int>
Uma vez que você se familiariza com a gramática do dplyr, o processo de análise exploratória se torna bastante trivial e até certo ponto, prazeiroso. Mas o que eu realmente gosto é que ele também se torna visualmente óbvio para o leitor, com cada chamado podendo ser lido como uma declaração:
Utilizando o banco de dados flights, agrupe as observações por mês e aeroporto de origem, então, calcule as médias e desvios padrão dos atrasos no pouso e na decolagem e o número de vôos para cada grupo.
Você também pode rapidamente introduzir ou retirar passos em cada chamado deste utilizando o pipe, por exemplo:
flights %>%
group_by(month, origin) %>%
summarize(atraso_decolagem_medio = mean(dep_delay, na.rm = T),
atraso_decolagem_desvpad = sd(dep_delay, na.rm = T),
atraso_pouso_medio = mean(arr_delay, na.rm = T),
atraso_pouso_desvpad = sd(arr_delay, na.rm = T),
n_voos = n()) %>%
arrange(-atraso_decolagem_medio)
## `summarise()` has grouped output by 'month'. You can override using the `.groups` argument.
## # A tibble: 36 x 7
## # Groups: month [12]
## month origin atraso_decolagem_medio atraso_decolagem_desvp~ atraso_pouso_med~
## <int> <chr> <dbl> <dbl> <dbl>
## 1 7 JFK 23.8 53.3 20.2
## 2 6 EWR 22.5 50.8 16.9
## 3 7 EWR 22.0 49.5 15.5
## 4 12 EWR 21.0 45.7 19.6
## 5 6 JFK 20.5 50.2 17.6
## 6 6 LGA 19.3 53.6 14.8
## 7 7 LGA 19.0 52.0 14.2
## 8 3 EWR 18.1 44.1 10.6
## 9 4 EWR 17.4 43.9 14.1
## 10 5 EWR 15.4 39.0 5.38
## # ... with 26 more rows, and 2 more variables: atraso_pouso_desvpad <dbl>,
## # n_voos <int>
E a leitura fica:
Utilizando o banco de dados flights, agrupe as observações por mês e aeroporto de origem, então, calcule as médias e desvios padrão dos atrasos no pouso e na decolagem e o número de vôos para cada grupo, então, ordene os resultados pelo maior atraso.
De quebra, você ainda leva para casa um dado no formato “tabela,” fácil de exportar para outros softwares para embelezamento e publicação. Veja:
resumo <-
flights %>%
group_by(month, origin) %>%
summarize(atraso_decolagem_medio = mean(dep_delay, na.rm = T),
atraso_decolagem_desvpad = sd(dep_delay, na.rm = T),
atraso_pouso_medio = mean(arr_delay, na.rm = T),
atraso_pouso_desvpad = sd(arr_delay, na.rm = T),
n_voos = n()) %>%
arrange(-atraso_decolagem_medio)
## `summarise()` has grouped output by 'month'. You can override using the `.groups` argument.
print(resumo, n = Inf)
## # A tibble: 36 x 7
## # Groups: month [12]
## month origin atraso_decolagem_medio atraso_decolagem_desvp~ atraso_pouso_med~
## <int> <chr> <dbl> <dbl> <dbl>
## 1 7 JFK 23.8 53.3 20.2
## 2 6 EWR 22.5 50.8 16.9
## 3 7 EWR 22.0 49.5 15.5
## 4 12 EWR 21.0 45.7 19.6
## 5 6 JFK 20.5 50.2 17.6
## 6 6 LGA 19.3 53.6 14.8
## 7 7 LGA 19.0 52.0 14.2
## 8 3 EWR 18.1 44.1 10.6
## 9 4 EWR 17.4 43.9 14.1
## 10 5 EWR 15.4 39.0 5.38
## 11 1 EWR 14.9 40.8 12.8
## 12 12 JFK 14.8 39.1 12.7
## 13 12 LGA 13.6 39.8 12.0
## 14 8 EWR 13.5 37.6 6.71
## 15 2 EWR 13.1 37.2 8.78
## 16 8 JFK 12.9 36.3 5.91
## 17 5 JFK 12.5 38.5 2.12
## 18 4 JFK 12.2 41.2 7.01
## 19 2 JFK 11.8 37.4 4.39
## 20 4 LGA 11.5 43.4 12.0
## 21 8 LGA 11.2 39.2 5.41
## 22 3 JFK 10.7 35.3 2.58
## 23 5 LGA 10.6 40.6 2.80
## 24 3 LGA 10.2 39.7 3.74
## 25 10 EWR 8.64 32.7 2.60
## 26 1 JFK 8.62 36.0 1.37
## 27 9 EWR 7.29 35.0 -4.73
## 28 2 LGA 6.96 33.4 3.15
## 29 11 EWR 6.72 28.8 0.672
## 30 9 JFK 6.64 32.5 -4.46
## 31 9 LGA 6.21 39.0 -2.83
## 32 1 LGA 5.64 29.7 3.38
## 33 10 LGA 5.31 30.1 0.186
## 34 11 LGA 4.77 26.6 1.55
## 35 11 JFK 4.68 27.1 -0.873
## 36 10 JFK 4.59 25.2 -3.59
## # ... with 2 more variables: atraso_pouso_desvpad <dbl>, n_voos <int>
Lembrem-se que é necessário atribuir <- os resultados das operações para que elas sejam salvas. Em geral, meu workflow é assim:
# Começo com o banco
flights
## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 533 529 4 850 830
## 3 2013 1 1 542 540 2 923 850
## 4 2013 1 1 544 545 -1 1004 1022
## 5 2013 1 1 554 600 -6 812 837
## 6 2013 1 1 554 558 -4 740 728
## 7 2013 1 1 555 600 -5 913 854
## 8 2013 1 1 557 600 -3 709 723
## 9 2013 1 1 557 600 -3 838 846
## 10 2013 1 1 558 600 -2 753 745
## # ... with 336,766 more rows, and 11 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
# Seleciono algumas variáveis
flights %>%
select(month, dep_delay, arr_delay)
## # A tibble: 336,776 x 3
## month dep_delay arr_delay
## <int> <dbl> <dbl>
## 1 1 2 11
## 2 1 4 20
## 3 1 2 33
## 4 1 -1 -18
## 5 1 -6 -25
## 6 1 -4 12
## 7 1 -5 19
## 8 1 -3 -14
## 9 1 -3 -8
## 10 1 -2 8
## # ... with 336,766 more rows
# Recorto algumas observações
flights %>%
select(month, dep_delay, arr_delay) %>%
filter(between(month, 1, 6))
## # A tibble: 166,158 x 3
## month dep_delay arr_delay
## <int> <dbl> <dbl>
## 1 1 2 11
## 2 1 4 20
## 3 1 2 33
## 4 1 -1 -18
## 5 1 -6 -25
## 6 1 -4 12
## 7 1 -5 19
## 8 1 -3 -14
## 9 1 -3 -8
## 10 1 -2 8
## # ... with 166,148 more rows
# Escolho os dominios e calculo as medidas resumo
flights %>%
select(month, dep_delay, arr_delay) %>%
filter(between(month, 1, 6)) %>%
group_by(month) %>%
summarise(atraso_dec_medio = mean(dep_delay, na.rm = T),
atraso_pou_medio = mean(arr_delay, na.rm = T))
## # A tibble: 6 x 3
## month atraso_dec_medio atraso_pou_medio
## <int> <dbl> <dbl>
## 1 1 10.0 6.13
## 2 2 10.8 5.61
## 3 3 13.2 5.81
## 4 4 13.9 11.2
## 5 5 13.0 3.52
## 6 6 20.8 16.5
# Acho bom organizar pelos atrasos maiores
flights %>%
select(month, dep_delay, arr_delay) %>%
filter(between(month, 1, 6)) %>%
group_by(month) %>%
summarise(atraso_dec_medio = mean(dep_delay, na.rm = T),
atraso_pou_medio = mean(arr_delay, na.rm = T)) %>%
arrange(-atraso_dec_medio, -atraso_pou_medio)
## # A tibble: 6 x 3
## month atraso_dec_medio atraso_pou_medio
## <int> <dbl> <dbl>
## 1 6 20.8 16.5
## 2 4 13.9 11.2
## 3 3 13.2 5.81
## 4 5 13.0 3.52
## 5 2 10.8 5.61
## 6 1 10.0 6.13
# Estou satisfeito, salvo meu resultado em outro objeto
atrasos <-
flights %>%
select(month, dep_delay, arr_delay) %>%
filter(between(month, 1, 6)) %>%
group_by(month) %>%
summarise(atraso_dec_medio = mean(dep_delay, na.rm = T),
atraso_pou_medio = mean(arr_delay, na.rm = T)) %>%
arrange(-atraso_dec_medio, -atraso_pou_medio)
atrasos
## # A tibble: 6 x 3
## month atraso_dec_medio atraso_pou_medio
## <int> <dbl> <dbl>
## 1 6 20.8 16.5
## 2 4 13.9 11.2
## 3 3 13.2 5.81
## 4 5 13.0 3.52
## 5 2 10.8 5.61
## 6 1 10.0 6.13
Desta forma, consigo construir interativamente meus cálculos, verificando a cada passo se estou obtendo o resultado esperado. Visto de outra perspectiva, se encontro um código programado desta forma que não funciona, posso ir apagando cada %>% para identificar onde o problema ocorreu.
Espero que tenha ficado claro que o assunto não se encerra por aqui. Existem diversas outras funções úteis no pacote, como count, if_else, case_when, top_n, bind_rows, bind_cols, as novas funções across e c_across e muitas, muitas outras. Nos livros vocês encontram vários outros exemplos e funções para facilitar o processo de análise de dados, mas nossa expectativa é que essa apresentação seja um ponto de partida para vocês se aprofundarem no seu próprio ritmo.
dplyr para bancos de dados relacionais
Nesta seção, o nosso problema não é mais a análise de dados presentes em um banco, mas o problema de relacionar informações sobre uma mesma unidade de análise que estão presentes em vários bancos de dados distintos.
O banco nycflights13 contém várias tabelas que se relacionam, e elas funcionam como um excelente exemplo de banco de dados relacionais.
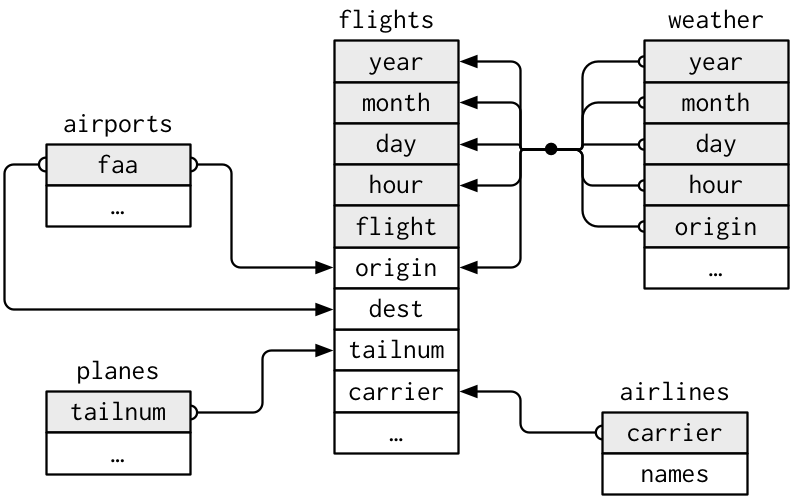
Note que além do banco de dados dos vôos, temos informações sobre clima, aviões e companhias aéreas. Para nós, pode ser relevante reunir informações de diferentes fontes em um mesmo banco de dados, algo que é possível através de joins. Por uma questão de tempo, não vamos entrar muito a fundo no assunto, mas vamos introduzir dois conceitos chave e partir pros exemplos.
-
chavessão as variáveis que identificam cada observação em um banco de dados de forma única. Uma chave é dita “primária” quando identifica uma observação na sua própria tabela e “externa” quando ela identifica uma observação em outra tabela. Assim, qualquer operação de join é uma forma de relacionar uma chave primária e uma chave externa. Essa junção de chaves é uma relação, e as relações podem ser 1 para 1, 1 para muitos ou muitos para 1. -
joinssão tipos de operação no qual se opta por priorizar um grupo de observações em detrimento de outras. Podemos vê-los didaticamente a partir de duas figuras:
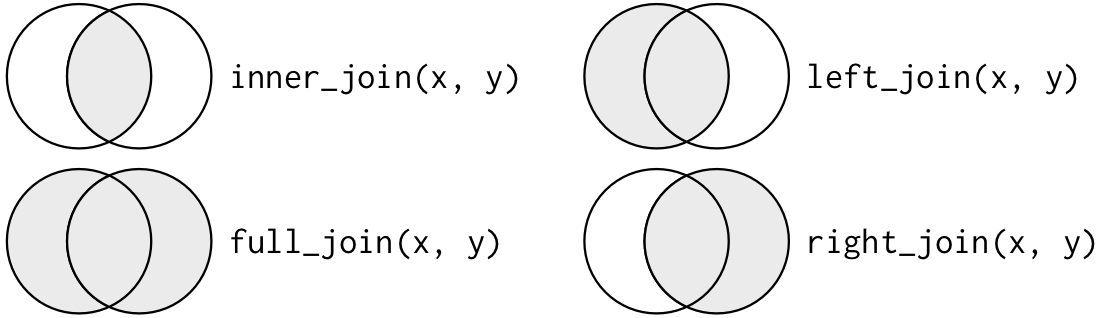
A primeira figura é interessante porque nos dá uma ideia de quais observações serão mantidas e quais serão descartadas, podemos imaginá-la como uma abstração da nossa escolha.
Quero todas as informações sobre os vôos e os aeroportos, e as duas são igualmente importantes (inner_join, x = flights, y = airports).
Quero todas as observações do banco vôos e as informações disponíveis sobre a aeronave (left_join, x = flights, y = planes).
Quero todas as informações tanto sobre os vôos quanto sobre o clima em cada dia (full_join, x = flights, y = weather).
Quero as informações dos vôos realizados pelas companhias aéreas - minha prioridade são as cias. áreas (right_join, x = flights, y = carriers).
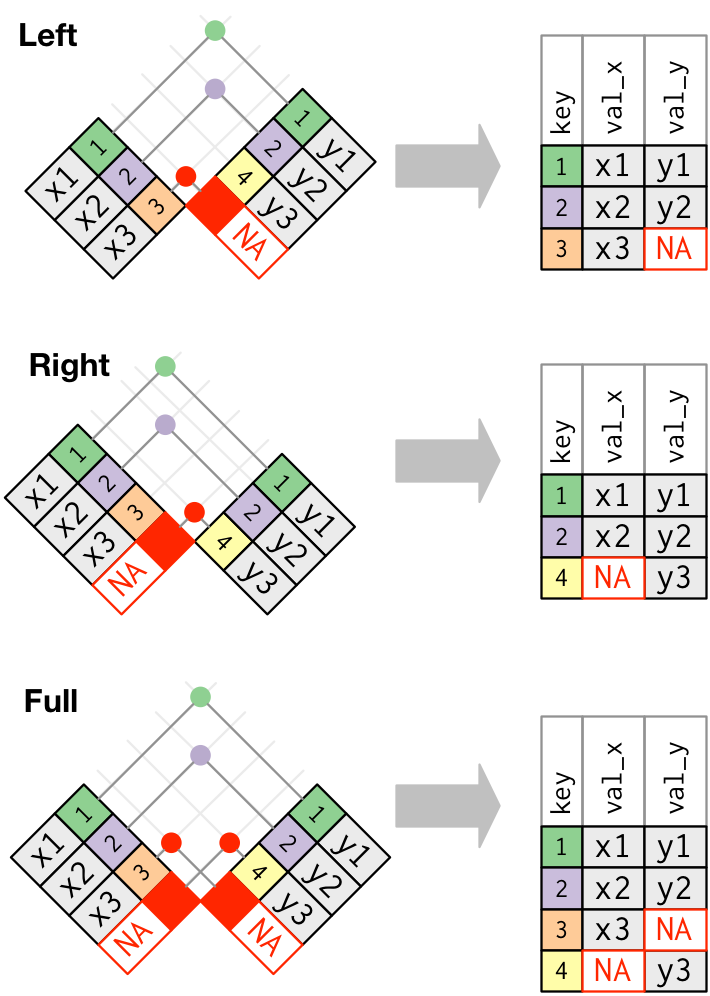
A segunda figura é interessante porque elas mostra a mecânica de um join: cada observação tem a sua chave marcada com a observação correspondente no outro banco. Se as chaves são iguais, a operação é realizada, se as chaves não são iguais, a operação não é realizada. Dependendo do tipo de join, uma, as duas ou nenhuma das observações é descartada do banco resultante.
Antes de começar a trabalhar com bancos relacionais, é uma boa ideia dar uma explorada nas chaves, vendo suas contagens, se há erros de digitação, etc. Por uma questão de tempo, vamos pular essa fase.
Se as nossas chaves forem perfeitinhas, e inclusive tiverem o mesmo nome nas duas tabelas, basta invocar o tipo de join desejado.
# Vamos dar uma enxugada no flights para poder ver o efeito dos joins com maior facilidade.
flights2 <- flights %>%
select(year:day, hour, origin, dest, tailnum, carrier)
flights2
## # A tibble: 336,776 x 8
## year month day hour origin dest tailnum carrier
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr>
## 1 2013 1 1 5 EWR IAH N14228 UA
## 2 2013 1 1 5 LGA IAH N24211 UA
## 3 2013 1 1 5 JFK MIA N619AA AA
## 4 2013 1 1 5 JFK BQN N804JB B6
## 5 2013 1 1 6 LGA ATL N668DN DL
## 6 2013 1 1 5 EWR ORD N39463 UA
## 7 2013 1 1 6 EWR FLL N516JB B6
## 8 2013 1 1 6 LGA IAD N829AS EV
## 9 2013 1 1 6 JFK MCO N593JB B6
## 10 2013 1 1 6 LGA ORD N3ALAA AA
## # ... with 336,766 more rows
# Chaves perfeitas, mesmo nome nos dois bancos = natural join
flights2 %>% left_join(weather) # Moleza
## Joining, by = c("year", "month", "day", "hour", "origin")
## # A tibble: 336,776 x 18
## year month day hour origin dest tailnum carrier temp dewp humid
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 2013 1 1 5 EWR IAH N14228 UA 39.0 28.0 64.4
## 2 2013 1 1 5 LGA IAH N24211 UA 39.9 25.0 54.8
## 3 2013 1 1 5 JFK MIA N619AA AA 39.0 27.0 61.6
## 4 2013 1 1 5 JFK BQN N804JB B6 39.0 27.0 61.6
## 5 2013 1 1 6 LGA ATL N668DN DL 39.9 25.0 54.8
## 6 2013 1 1 5 EWR ORD N39463 UA 39.0 28.0 64.4
## 7 2013 1 1 6 EWR FLL N516JB B6 37.9 28.0 67.2
## 8 2013 1 1 6 LGA IAD N829AS EV 39.9 25.0 54.8
## 9 2013 1 1 6 JFK MCO N593JB B6 37.9 27.0 64.3
## 10 2013 1 1 6 LGA ORD N3ALAA AA 39.9 25.0 54.8
## # ... with 336,766 more rows, and 7 more variables: wind_dir <dbl>,
## # wind_speed <dbl>, wind_gust <dbl>, precip <dbl>, pressure <dbl>,
## # visib <dbl>, time_hour <dttm>
flights2 %>% left_join(airlines) # Moleza
## Joining, by = "carrier"
## # A tibble: 336,776 x 9
## year month day hour origin dest tailnum carrier name
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr>
## 1 2013 1 1 5 EWR IAH N14228 UA United Air Lines Inc.
## 2 2013 1 1 5 LGA IAH N24211 UA United Air Lines Inc.
## 3 2013 1 1 5 JFK MIA N619AA AA American Airlines Inc.
## 4 2013 1 1 5 JFK BQN N804JB B6 JetBlue Airways
## 5 2013 1 1 6 LGA ATL N668DN DL Delta Air Lines Inc.
## 6 2013 1 1 5 EWR ORD N39463 UA United Air Lines Inc.
## 7 2013 1 1 6 EWR FLL N516JB B6 JetBlue Airways
## 8 2013 1 1 6 LGA IAD N829AS EV ExpressJet Airlines Inc.
## 9 2013 1 1 6 JFK MCO N593JB B6 JetBlue Airways
## 10 2013 1 1 6 LGA ORD N3ALAA AA American Airlines Inc.
## # ... with 336,766 more rows
# Chaves perfeitas, mas há variáveis nos dois bancos com o mesmo nome e que não são chaves
# É necessário especificar qual a chave
flights2 %>% left_join(planes, by = "tailnum")
## # A tibble: 336,776 x 16
## year.x month day hour origin dest tailnum carrier year.y type
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <int> <chr>
## 1 2013 1 1 5 EWR IAH N14228 UA 1999 Fixed wing mult~
## 2 2013 1 1 5 LGA IAH N24211 UA 1998 Fixed wing mult~
## 3 2013 1 1 5 JFK MIA N619AA AA 1990 Fixed wing mult~
## 4 2013 1 1 5 JFK BQN N804JB B6 2012 Fixed wing mult~
## 5 2013 1 1 6 LGA ATL N668DN DL 1991 Fixed wing mult~
## 6 2013 1 1 5 EWR ORD N39463 UA 2012 Fixed wing mult~
## 7 2013 1 1 6 EWR FLL N516JB B6 2000 Fixed wing mult~
## 8 2013 1 1 6 LGA IAD N829AS EV 1998 Fixed wing mult~
## 9 2013 1 1 6 JFK MCO N593JB B6 2004 Fixed wing mult~
## 10 2013 1 1 6 LGA ORD N3ALAA AA NA <NA>
## # ... with 336,766 more rows, and 6 more variables: manufacturer <chr>,
## # model <chr>, engines <int>, seats <int>, speed <int>, engine <chr>
Veja que tanto flights2 quanto planes tem uma variável chamada year, mas elas significados diferentes. Em flights2 é o ano do vôo, enquanto em planes é o ano em que a aeronave entra em serviço. Na hora que fazemos o join, uma recebe o sufixo “x” e a outra “y” para a indicar a diferença. Você pode especificar o sufixo desejado para evitar confusão:
flights2 %>% left_join(planes, by = "tailnum", suffix = c("_flight", "_entered_service"))
## # A tibble: 336,776 x 16
## year_flight month day hour origin dest tailnum carrier year_entered_serv~
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <int>
## 1 2013 1 1 5 EWR IAH N14228 UA 1999
## 2 2013 1 1 5 LGA IAH N24211 UA 1998
## 3 2013 1 1 5 JFK MIA N619AA AA 1990
## 4 2013 1 1 5 JFK BQN N804JB B6 2012
## 5 2013 1 1 6 LGA ATL N668DN DL 1991
## 6 2013 1 1 5 EWR ORD N39463 UA 2012
## 7 2013 1 1 6 EWR FLL N516JB B6 2000
## 8 2013 1 1 6 LGA IAD N829AS EV 1998
## 9 2013 1 1 6 JFK MCO N593JB B6 2004
## 10 2013 1 1 6 LGA ORD N3ALAA AA NA
## # ... with 336,766 more rows, and 7 more variables: type <chr>,
## # manufacturer <chr>, model <chr>, engines <int>, seats <int>, speed <int>,
## # engine <chr>
Um aviso: cuidado com os produtos cartesianos. Não há um bom exemplo aqui no caso do flights porque o banco já está limpinho, mas se você especificar chaves com uma relação “muitos para muitos,” ele vai registrar no banco novo uma linha para cada combinação possível de variáveis. Em bancos maiores, isso geralmente estoura sua memória e trava o R. Veja este pequeno exemplo de brinquedo.
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
2, "x3",
3, "x4"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
2, "y3",
3, "y4"
)
left_join(x, y, by = "key")
## # A tibble: 6 x 3
## key val_x val_y
## <dbl> <chr> <chr>
## 1 1 x1 y1
## 2 2 x2 y2
## 3 2 x2 y3
## 4 2 x3 y2
## 5 2 x3 y3
## 6 3 x4 y4
Veja que no resultado foi criada uma linha para cada combinação de val_x e val_y que tem a mesma chave repetida. Podem até existir situações em que isso seja o que você quer mesmo, mas na minha experiência até o momento isso é problema com as chaves duplicadas e é sinal de que há algo errado.
Mas peraí, se você falou que tem 4 tipos de join, porque só dá exemplo de left_join?
Na prática, operações relacionais são feitas de forma intencional: escolhemos bancos de dados de acordo com o valor que atribuímos a informação presente nele e pinçamos informações relacionadas de outros lugares para adicionar aquilo que é nosso foco. Por isso, na maioria dos casos, o left_join é o mais usual, porque preserva todas as informações do meu banco x e adiciona apenas as informações do banco y que combinaram com sucesso. Isso garante que eu não vou perder nenhuma informação do meu banco principal.
Pra encerrar essa parte, mais exemplos de joins.
# Minhas chaves tem nomes diferentes, então uso um vetor do tipo c("chave_x" = "chave_y")
flights2 %>%
left_join(airports, c("dest" = "faa"))
## # A tibble: 336,776 x 15
## year month day hour origin dest tailnum carrier name lat lon alt
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 2013 1 1 5 EWR IAH N14228 UA Georg~ 30.0 -95.3 97
## 2 2013 1 1 5 LGA IAH N24211 UA Georg~ 30.0 -95.3 97
## 3 2013 1 1 5 JFK MIA N619AA AA Miami~ 25.8 -80.3 8
## 4 2013 1 1 5 JFK BQN N804JB B6 <NA> NA NA NA
## 5 2013 1 1 6 LGA ATL N668DN DL Harts~ 33.6 -84.4 1026
## 6 2013 1 1 5 EWR ORD N39463 UA Chica~ 42.0 -87.9 668
## 7 2013 1 1 6 EWR FLL N516JB B6 Fort ~ 26.1 -80.2 9
## 8 2013 1 1 6 LGA IAD N829AS EV Washi~ 38.9 -77.5 313
## 9 2013 1 1 6 JFK MCO N593JB B6 Orlan~ 28.4 -81.3 96
## 10 2013 1 1 6 LGA ORD N3ALAA AA Chica~ 42.0 -87.9 668
## # ... with 336,766 more rows, and 3 more variables: tz <dbl>, dst <chr>,
## # tzone <chr>
# Mesma coisa, só que agora juntando as informações da origem ao invés do destino
flights2 %>%
left_join(airports, c("origin" = "faa"))
## # A tibble: 336,776 x 15
## year month day hour origin dest tailnum carrier name lat lon alt
## <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 2013 1 1 5 EWR IAH N14228 UA Newar~ 40.7 -74.2 18
## 2 2013 1 1 5 LGA IAH N24211 UA La Gu~ 40.8 -73.9 22
## 3 2013 1 1 5 JFK MIA N619AA AA John ~ 40.6 -73.8 13
## 4 2013 1 1 5 JFK BQN N804JB B6 John ~ 40.6 -73.8 13
## 5 2013 1 1 6 LGA ATL N668DN DL La Gu~ 40.8 -73.9 22
## 6 2013 1 1 5 EWR ORD N39463 UA Newar~ 40.7 -74.2 18
## 7 2013 1 1 6 EWR FLL N516JB B6 Newar~ 40.7 -74.2 18
## 8 2013 1 1 6 LGA IAD N829AS EV La Gu~ 40.8 -73.9 22
## 9 2013 1 1 6 JFK MCO N593JB B6 John ~ 40.6 -73.8 13
## 10 2013 1 1 6 LGA ORD N3ALAA AA La Gu~ 40.8 -73.9 22
## # ... with 336,766 more rows, and 3 more variables: tz <dbl>, dst <chr>,
## # tzone <chr>
O assunto, obviamente, não pára por aí. Nos livros vocês encontrarão mais exemplos e funções, como é o caso do semi_join e do anti_join e das operações “set,” intersect, union e setdiff, mas isso fica pra vocês explorarem por conta própria e virem tirar as dúvidas depois!
stringr
stringr contém uma família de funções, todas começadas em str_, cuja principal preocupação é a consistência. As funções do base para strings são muito úteis, porém, seus argumentos estão numa ordem um pouco estranha, algumas funções são vetorizadas e outras não. Quando você se acostuma, até que não é tão ruim, mas voltando para o assunto discutido ontem de tornar o seu código mais legível, é interessante ter a simplicidade oferecida.
Basicão da string
Como este curso já é pra praticantes de R, vou pular algumas coisas muito básicas de string, vamos ao que interessa.
Determinados caracteres tem um significado especial dentro das strings. Quem já tentou copiar e colar um caminho de arquivo do Windows pro R sabe disso. Então, nesses casos, é precisar “escapar” caracteres. Por exemplo, se você quiser escrever aspas, você usar a contrabarra \ para “escapar” um caractere.
aspa_simples <- '\'' # ou "'"
aspa_dupla <- "\"" # ou '"'
A regra do escape é simples, então se você quiser colocar uma contrabarra \
x <- c("\\", "\"")
x
## [1] "\\" "\""
writeLines(x)
## \
## "
Outros caracteres especiais úteis: "\n" para pular uma linha, \t para Tab. Você pode ver os outros na ajuda das aspas ", basta digitar no console ?"'" ou ?'"'.
Outra coisa que dá pra fazer, se você precisar incluir um caractere distinto, é usar unicode:
x <- "\u00b5"
x
## [1] "µ"
Ok, mas e o pacote stringr? Bem, ele tem o intuito de facilitar e dar consistência, então, todas as funções do pacote começam com as iniciais str_ justamente para serem utilizadas com o autocompletar do RStudio, que pode ser acessada com os atalhos Ctrl + Espaço ou Tab. Vamos ver agora alguns exemplos de funções do pacote.
Comprimento da string em caracteres:
library(stringr)
# No RStudio, basta digitar 'str_' e apertar Tab ou Ctrl + Espaço
x <- "Ministro Sinistro"
str_length(x)
## [1] 17
x <- c("Ministro Sinistro", "Abelha Gulosa", "p")
str_length(x)
## [1] 17 13 1
Concatenação de strings:
str_c("x", "y", "z")
## [1] "xyz"
Use o argumento sep para definir caracteres que aparecerão entre as strings originais:
str_c("x", "y", "z", sep = " + ")
## [1] "x + y + z"
Você pode trabalhar com strings que contém NAs:
x <- c("abc", NA)
str_c("|-", x, "-|")
## [1] "|-abc-|" NA
str_c("|-", str_replace_na(x), "-|")
## [1] "|-abc-|" "|-NA-|"
str_c é uma função vetorizada e automaticamente recicla seus argumentos pra ter o tamanho do maior:
# Eu na graduação
str_c("Profe, me dá mais ", c("1", "2", "3"), " semanas pra entregar, por favor!")
## [1] "Profe, me dá mais 1 semanas pra entregar, por favor!"
## [2] "Profe, me dá mais 2 semanas pra entregar, por favor!"
## [3] "Profe, me dá mais 3 semanas pra entregar, por favor!"
# Eu de manhã
str_c("Só mais ", c("5", "10", "20", "30"), " minutinhos e eu acordo!")
## [1] "Só mais 5 minutinhos e eu acordo!" "Só mais 10 minutinhos e eu acordo!"
## [3] "Só mais 20 minutinhos e eu acordo!" "Só mais 30 minutinhos e eu acordo!"
Se algum dos objetos passados para str_c tiver tamanho 0, ele é descartado. Útil para usar com testes lógicos.
nome <- "Vinicius"
sobrenome <- "Maia"
tem_nome_do_meio <- FALSE
str_c(
"Meu nome é ", nome, " ",
# isso aqui retorna um vetor tamanho 0
if (tem_nome_do_meio) " de Souza",
sobrenome,
"."
)
## [1] "Meu nome é Vinicius Maia."
Conhecedores de paste reconhecerão o argumento collapse, que serve para transformar vetores de strings em uma única string.
str_c(c("Natália", "Martins", "Arruda"), collapse = " ")
## [1] "Natália Martins Arruda"
De forma similar, conhecedores de substring deverão imediatamente reconhecer essa:
x <- c("Maçã", "Banana", "Abacaxi")
str_sub(x, 1, 3)
## [1] "Maç" "Ban" "Aba"
str_sub(x, -3, -1)
## [1] "açã" "ana" "axi"
str_sub não vai dar erro se a string for muito curta:
str_sub("a", 1, 5)
## [1] "a"
Dá pra usar a forma str_sub(x) <- para modificar partes de strings
str_sub(x, 1, 1) <- str_to_lower(str_sub(x, 1, 1))
x
## [1] "maçã" "banana" "abacaxi"
Note o uso de str_to_lower para mudar para minúsculas. O contrário é str_to_upper, também há uma para títulos, str_to_title, e para a primeira letra de uma frase, str_to_sentence.
x <- "Ministro Sinistro"
str_to_lower(x)
## [1] "ministro sinistro"
str_to_upper(x)
## [1] "MINISTRO SINISTRO"
str_to_sentence(x)
## [1] "Ministro sinistro"
str_to_title(x)
## [1] "Ministro Sinistro"
Como vimos no readr, algumas questões relacionadas a strings dependem da língua, ou, na linguagem do pacote, são “locale dependent.” Por isso nas funções onde isso é relevante, o argumento se chama locale. Isso não é super relevante para quem trabalha com o inglês ou as línguas do oeste europeu, considerando que a maioria das línguas tem raízes similares, mas pode ser muito importante para outros idiomas. Vejamos este exemplo com a mudança da ordem das strings.
x <- c("abacaxi", "escarola", "banana")
str_sort(x, locale = "en") # Inglês
## [1] "abacaxi" "banana" "escarola"
str_sort(x, locale = "haw") # Havaiano
## [1] "abacaxi" "escarola" "banana"
É justamente para esses casos que str_sort e str_order oferecem a alternativa de você especificar o locale.
Trabalhando com padrões e “expressões regulares”
Expressões regulares são quase uma linguagem de programação em si, aqui, vamos dar uma passada muito rápida e ver alguns exemplos simples. São uma ferramenta muito útil, mas talvez não do interesse de todos.
Basicamente, a ideia é fazer uma pesquisa na string, em busca de um padrão específico. Pode ser uma palavra, um espaço em branco, uma quebra de linha. Pode ficar muito complexo ou ser bem básico. O nosso objetivo aqui é que todos tenham a capacidade de trabalhar com padrões simples para corrigir inconsistências em bancos de dados, como no exemplo da aula anterior das colunas do dataset da OMS.
Para visualizar padrões, vamos usar duas helper functions, str_view e str_view_all.
x <- c("mamão", "banana", "ananas")
str_view(x, "an")
O resultado sai na aba “Viewer” do seu RStudio.
O primeiro padrão que podemos usar é o ., que identifica qualquer caractere. As vezes na documentação esse tipo de padrão genérico é chamado de “wildcard.”
str_view(x, ".a.")
A forma de ler essa operação é: “Identifique qualquer conjunto de caracteres que tenha uma letra a no meio deles.”
Se você quiser identificar um . numa string, você precisa usar o escape \. Porém, a barra também é um escape! Então, ao escrever expressões regulares, precisamos usar \\. Veja:
dot <- "."
cat(dot)
## .
# erro
dot <- "\."
## Error: '\.' é uma seqüência de escape não reconhecida na cadeia de caracteres começando com ""\."
# agora sim
dot <- "\\."
cat(dot)
## \.
Agora em um exemplo:
x <- c("Praia.", "Agora.", "Ou.", "Me.", "Rebelo.")
str_view(x, "a\\.")
str_view(x, "u\\.")
str_view(x, "o\\.")
Tá, mas se a contrabarra é utilizada para denotar uma expressão regular tipo o ., como eu faço para pesquisar uma contrabarra?
x <- "Jake Peralta é o melhor detetive\\gênio"
cat(x)
## Jake Peralta é o melhor detetive\gênio
A solução é escapar o escape do escape, sacou?
str_view(x, "\\\\")
É enrolado mesmo…
Para não estender muito o assunto, vamos ver vários exemplos de caracteres especiais a ser usados em expressões regulares.
^ encontra o início de uma string
x <- c("maçã", "banana", "mamão")
str_view(x, "^m")
$ encontra o final
str_view(x, "a$")
Para forçar a expressão a achar apenas a palavra completa, use os dois
x <- c("vitamina de banana", "sundae de banana", "banana")
str_view(x, "banana")
str_view(x, "^banana$")
Use classes de caracteres para encontrar genéricos
Qualquer digito:
x <- "15 de Maio de 2021."
str_view(x, "\\d")
Qualquer espaço em branco:
str_view(x, "\\s")
Qualquer caractere de um grupo: [abc]
str_view(x, "[M]")
str_view(x, "[eM]")
str_view(x, "[deM]")
Qualquer caractere menos esses: [^abc]
str_view(x, "[^15]")
str_view(x, "[^15 de]")
str_view(x, "[^15 de Maio de ]")
Usar uma classe pra evitar digitar 5 milhões de contrabarras
str_view(x, "[.]")
str_view("a*c", "[*]")
Você pode misturar strings com classes também
x <- c("15 de Maio de 2021.", "16 de Maio de 2021.")
str_view(x, "1[56] de Maio")
Infelizmente, alguns caracteres tem significado especial dentro das classes, e você tem que usar contrabarras para fugir deles: ] \ ^ e -.
Você pode lidar com repetições
x <- c("Mariele", "Marielle", "Mariellle", "Marie")
str_view(x, "Mariell?e") # l aparece 0 ou 1 vez
str_view(x, "Mariel+e") # l aparece 1 ou + vezes
str_view(x, "Mariel*") # l aparece 0 ou + vezes
str_view(x, "Mariel{0}") # l aparece exatamente 0 vezes
str_view(x, "Mariel{1}") # l aparece exatamente 1 vez
str_view(x, "Mariel{2}") # l aparece exatamente 2 vezes
str_view(x, "Mariel{3}") # l aparece exatamente 3 vezes
str_view(x, "Mariel{1,}") # l aparece exatamente 1 vez ou mais
str_view(x, "Mariel{2,}") # l aparece exatamente 2 vezes ou mais
str_view(x, "Mariel{1,2}") # l aparece de 1 a 2 vezes
str_view(x, "Mariel{2,3}") # l aparece de 2 a 3 vezes
Esse assunto é enorme, e ainda estamos só na superfície. Há grupos, lookarounds, e muitos outros detalhes envolvendo expressões regulares, e vocês podem consultar os livros de referência para mergulhar mais fundo. Mas vamos parar por aqui para nos concentrar no que interessa.
Em geral, temos um banco de dados com strings problemáticas, tipo erros de digitação, inconsistências etc. O primeiro passo, em geral, é detectar os problemas.
x <- c("São Paulo", "SAO PAULO", "Sao Paulo", "sp", "SP", "Sp")
str_detect(x, "ã")
## [1] TRUE FALSE FALSE FALSE FALSE FALSE
str_detect(x, "[Ss][Pp]")
## [1] FALSE FALSE FALSE TRUE TRUE TRUE
str_detect(x, "[Ss][Aa][Oo]")
## [1] FALSE TRUE TRUE FALSE FALSE FALSE
Você pode se utilizar do fato da resposta ser um vetor lógico para descobrir quantos problemas você tem
# Contagens
str_detect(x, "ã") %>% sum()
## [1] 1
str_detect(x, "[Ss][Pp]") %>% sum()
## [1] 3
str_detect(x, "[Ss][Aa][Oo]") %>% sum()
## [1] 2
# Proporções
str_detect(x, "ã") %>% mean()
## [1] 0.1666667
str_detect(x, "[Ss][Pp]") %>% mean()
## [1] 0.5
str_detect(x, "[Ss][Aa][Oo]") %>% mean()
## [1] 0.3333333
Depois de detectar seus problemas, você pode querer extrair uma parte dos seus casos: use str_subset
str_subset(x, "[Ss][Pp]")
## [1] "sp" "SP" "Sp"
Em geral, no entanto, você vai estar trabalhando num data frame. Então use dplyr::filter e str_detect.
df <- tibble::tibble(
nome = c("Marcos", "rogério", "cebolinha", "Beiçola", "nadir", "Monica"),
uf = x,
dtnsc = c("15 de Maio de 1980", "1 de Jan de 2001", "6 de Ago de 1993",
"20 de Abril de 1964", "24 de Nov de 1975", "14 de Dezembro de 1997")
)
df %>% dplyr::filter(str_detect(uf, "[Ss][Pp]"))
## # A tibble: 3 x 3
## nome uf dtnsc
## <chr> <chr> <chr>
## 1 Beiçola sp 20 de Abril de 1964
## 2 nadir SP 24 de Nov de 1975
## 3 Monica Sp 14 de Dezembro de 1997
Você pode contar quantos matches você tem str_count
str_count(x, "o")
## [1] 2 0 2 0 0 0
str_count(x, "[Oo]")
## [1] 2 2 2 0 0 0
# e usar num data frame
df %>% dplyr::mutate(vogais = str_count(uf, "[aeiou]"),
consoantes = str_count(uf, "[^aeiou]"))
## # A tibble: 6 x 5
## nome uf dtnsc vogais consoantes
## <chr> <chr> <chr> <int> <int>
## 1 Marcos São Paulo 15 de Maio de 1980 4 5
## 2 rogério SAO PAULO 1 de Jan de 2001 0 9
## 3 cebolinha Sao Paulo 6 de Ago de 1993 5 4
## 4 Beiçola sp 20 de Abril de 1964 0 2
## 5 nadir SP 24 de Nov de 1975 0 2
## 6 Monica Sp 14 de Dezembro de 1997 0 2
Você pode extrair str_extract as informações que você quer
str_extract(df$dtnsc, "\\d+")
## [1] "15" "1" "6" "20" "24" "14"
str_extract(df$dtnsc, "\\d+$")
## [1] "1980" "2001" "1993" "1964" "1975" "1997"
str_extract(df$dtnsc, "\\D+")
## [1] " de Maio de " " de Jan de " " de Ago de " " de Abril de "
## [5] " de Nov de " " de Dezembro de "
# Na tibble
df %>% dplyr::mutate(
dia = str_extract(dtnsc, "\\d+"),
mes = str_extract(df$dtnsc, "\\D+"),
ano = str_extract(dtnsc, "\\d+$"))
## # A tibble: 6 x 6
## nome uf dtnsc dia mes ano
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Marcos São Paulo 15 de Maio de 1980 15 " de Maio de " 1980
## 2 rogério SAO PAULO 1 de Jan de 2001 1 " de Jan de " 2001
## 3 cebolinha Sao Paulo 6 de Ago de 1993 6 " de Ago de " 1993
## 4 Beiçola sp 20 de Abril de 1964 20 " de Abril de " 1964
## 5 nadir SP 24 de Nov de 1975 24 " de Nov de " 1975
## 6 Monica Sp 14 de Dezembro de 1997 14 " de Dezembro de " 1997
# Melhor ainda
df %>% tidyr::extract(
dtnsc, c("dia", "mes", "ano"),
regex = "(\\d+) de (\\D+) de (\\d+$)"
)
## # A tibble: 6 x 5
## nome uf dia mes ano
## <chr> <chr> <chr> <chr> <chr>
## 1 Marcos São Paulo 15 Maio 1980
## 2 rogério SAO PAULO 1 Jan 2001
## 3 cebolinha Sao Paulo 6 Ago 1993
## 4 Beiçola sp 20 Abril 1964
## 5 nadir SP 24 Nov 1975
## 6 Monica Sp 14 Dezembro 1997
Similar a ideia de extração, podemos substituir com str_replace
str_replace(x, "[Ss][Pp]", "São Paulo")
## [1] "São Paulo" "SAO PAULO" "Sao Paulo" "São Paulo" "São Paulo" "São Paulo"
str_replace(x, "SAO PAULO", "São Paulo")
## [1] "São Paulo" "São Paulo" "Sao Paulo" "sp" "SP" "Sp"
str_replace(x, "a", "ã")
## [1] "São Pãulo" "SAO PAULO" "São Paulo" "sp" "SP" "Sp"
Tanto str_extract quanto str_replace substituem apenas a primeira marca, se você quiser substituir todas, utilize str_..._all
str_extract_all(x, "a", simplify = TRUE)
## [,1] [,2]
## [1,] "a" ""
## [2,] "" ""
## [3,] "a" "a"
## [4,] "" ""
## [5,] "" ""
## [6,] "" ""
str_replace_all(x, "a", "ã")
## [1] "São Pãulo" "SAO PAULO" "São Pãulo" "sp" "SP" "Sp"
O assunto não acaba, mas vamos parar por aqui. Novamente, recomendo consultarem os materiais para quem quiser ir mais a fundo nisso. É bem capaz de no andar da carruagem aparecerem outros exemplos nos quais a manipulação de strings pode ser importante.
forcats
Esse é um pacotinho muito que facilita bastante a vida de quem trabalha com variável categórica, ou, no R, os factors. Ele consiste em uma série de “helper functions” baseadas em funções do base e do stats que trabalham com os componentes de um factor, ou seja, seus levels e seus values.
Imagino que todos aqui estão familiarizados com fatores e com a sua criação, então vamos direto ao que interessa. Educação é um vetor de caracteres que vem com os níveis educacionais de um população.
educacao <- c("Superior", "Fundamental", "Médio", "Superior", "Fundamental", "Médio",
"Superior", "Fundamental", "Médio", "Superior", "Fundamental", "Médio")
x <- factor(educacao, levels = c("Fundamental", "Médio", "Superior"))
x
## [1] Superior Fundamental Médio Superior Fundamental Médio
## [7] Superior Fundamental Médio Superior Fundamental Médio
## Levels: Fundamental Médio Superior
levels(x)
## [1] "Fundamental" "Médio" "Superior"
relevel(x, "Superior")
## [1] Superior Fundamental Médio Superior Fundamental Médio
## [7] Superior Fundamental Médio Superior Fundamental Médio
## Levels: Superior Fundamental Médio
Em geral, diversas tarefas envolvendo fatores no base não são muito simples. Por exemplo, se eu quiser modificar os nomes dos níveis de um fator depois dele já estar criado, modificar a ordem dos níveis, ou agrupar diversos níveis em um só. forcats vem justamente oferecer soluções nesse sentido. Normalmente, estamos trabalhando com bancos de dados, e não com um vetor solitário, por isso, vamos usar o gss_cat, uma amostra do General Social Survey aplicado pelo NORC e pela Universidade de Chicago, que vem no pacote forcats.
library(forcats)
gss_cat
## # A tibble: 21,483 x 9
## year marital age race rincome partyid relig denom tvhours
## <int> <fct> <int> <fct> <fct> <fct> <fct> <fct> <int>
## 1 2000 Never ma~ 26 White $8000 to ~ Ind,near r~ Protesta~ Souther~ 12
## 2 2000 Divorced 48 White $8000 to ~ Not str re~ Protesta~ Baptist~ NA
## 3 2000 Widowed 67 White Not appli~ Independent Protesta~ No deno~ 2
## 4 2000 Never ma~ 39 White Not appli~ Ind,near r~ Orthodox~ Not app~ 4
## 5 2000 Divorced 25 White Not appli~ Not str de~ None Not app~ 1
## 6 2000 Married 25 White $20000 - ~ Strong dem~ Protesta~ Souther~ NA
## 7 2000 Never ma~ 36 White $25000 or~ Not str re~ Christian Not app~ 3
## 8 2000 Divorced 44 White $7000 to ~ Ind,near d~ Protesta~ Luthera~ NA
## 9 2000 Married 44 White $25000 or~ Not str de~ Protesta~ Other 0
## 10 2000 Married 47 White $25000 or~ Strong rep~ Protesta~ Souther~ 3
## # ... with 21,473 more rows
Contagens
Uma das primeiras coisas que interessa ao lidar com fatores, é obter suas contagens, o que é algo muito simples utilizando a gramática do dplyr.
# Função count
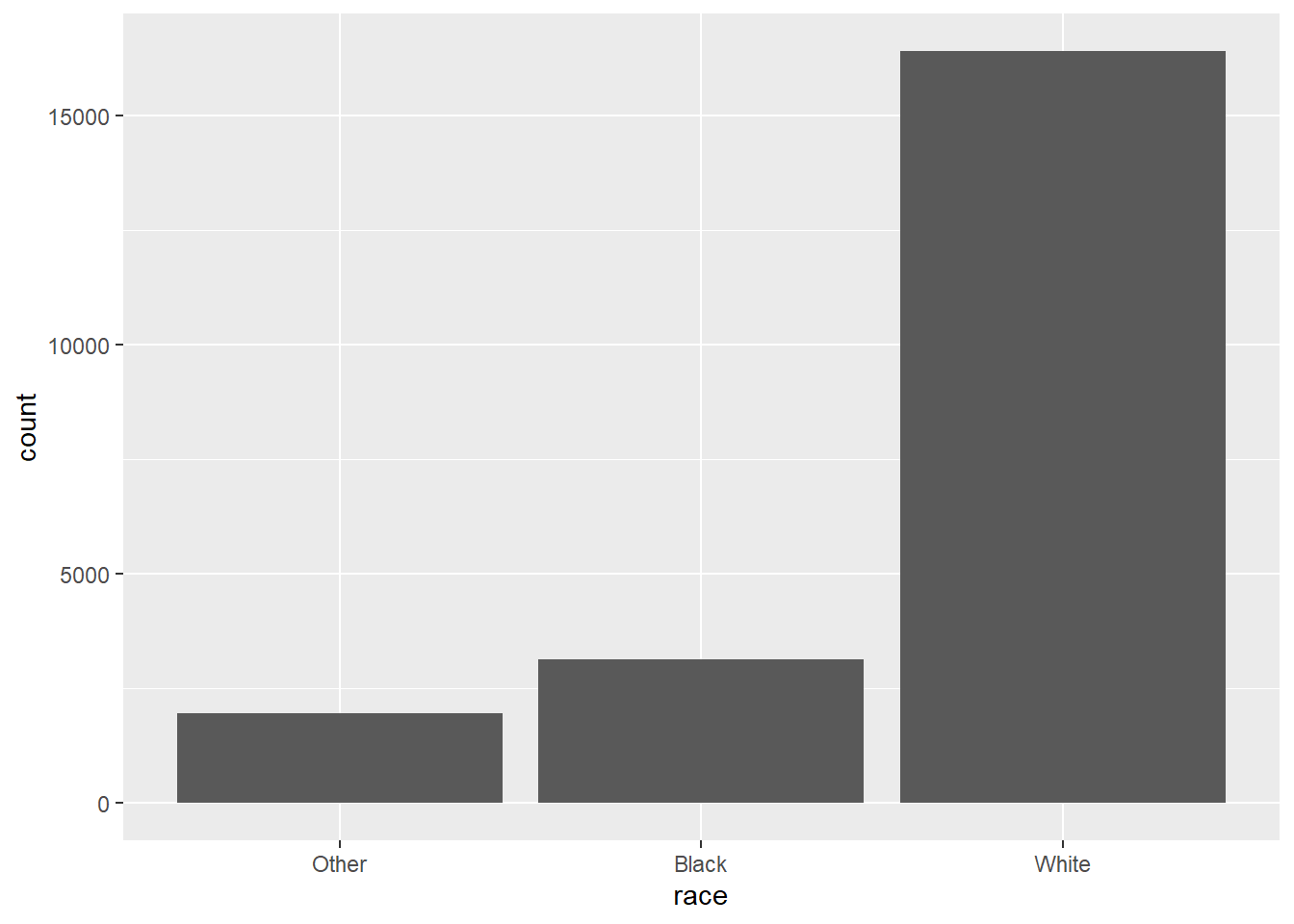
gss_cat %>%
count(race)
## # A tibble: 3 x 2
## race n
## <fct> <int>
## 1 Other 1959
## 2 Black 3129
## 3 White 16395
# Incluindo níveis com contagem = 0.
gss_cat %>%
count(race, .drop = FALSE)
## # A tibble: 4 x 2
## race n
## <fct> <int>
## 1 Other 1959
## 2 Black 3129
## 3 White 16395
## 4 Not applicable 0
# Visualização com ggplot
library(ggplot2)
gss_cat %>%
ggplot(aes(race)) + geom_bar()
# Incluindo níveis com contagem = 0.
gss_cat %>%
ggplot(aes(race)) + geom_bar() + scale_x_discrete(drop = FALSE)
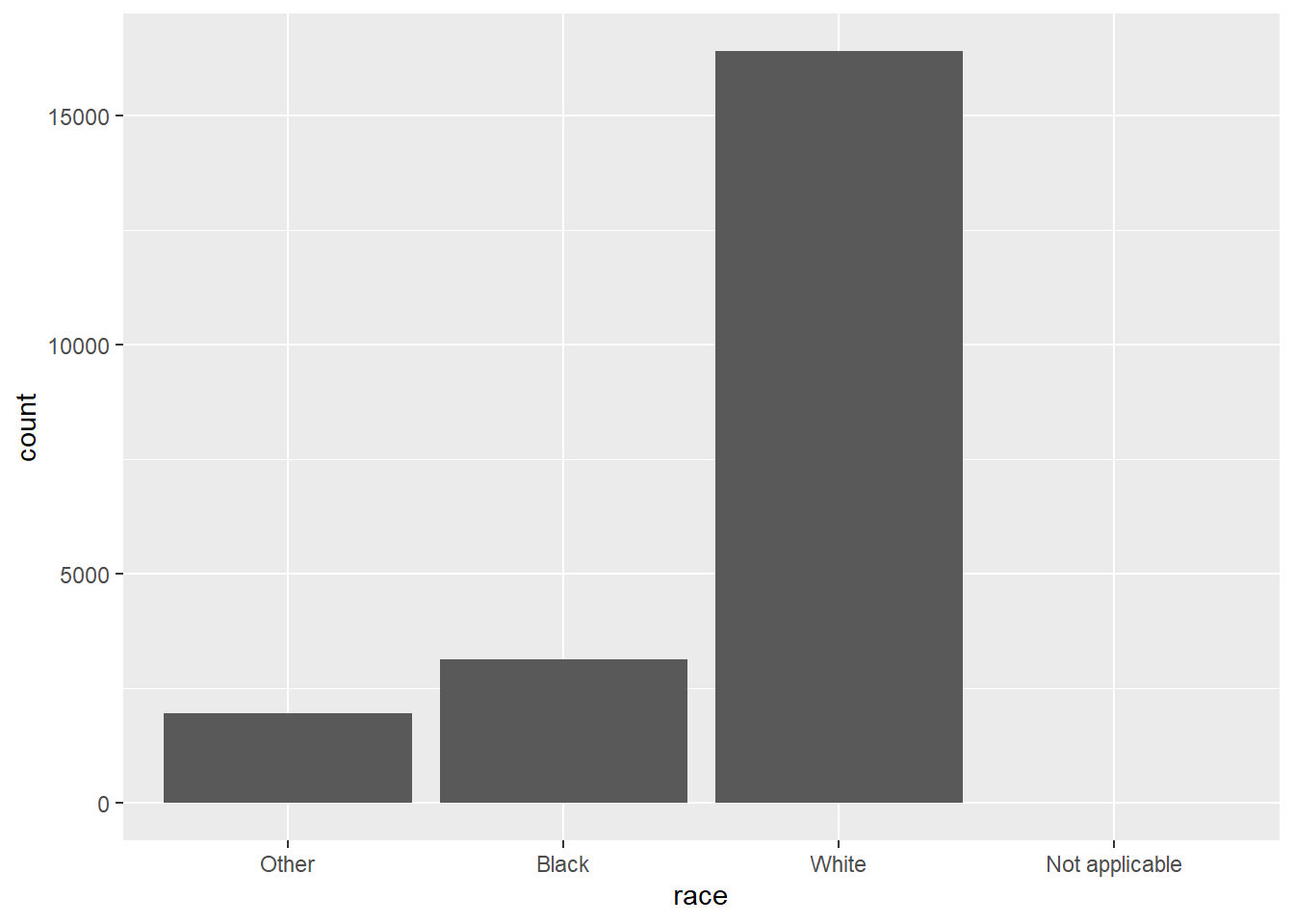
Note o uso do argumento drop nos dois casos, para indicar que casos com 0 observações não devem ser removidos do resultado.
Modificando a ordem
A segunda tarefa comum quando trabalhamos com fatores é modificar a ordem em que eles aparecem. Não é tanto o caso quando trabalhamos com fatores ordenados, mas diversos tipos de variáveis categóricas não possuem uma ordem lógica pre-definida e, mesmo assim, nos interessa apresentá-los de acordo com uma determinada hierarquia visual, seja porque eles são os mais frequentes ou porque queremos destacar algum elemento em particular. forcats implementa diversas estratégias de reordenamento de fatores. Vamos vê-las brevemente.
Digamos que eu queira saber o tempo médio de televisão assistida por membros das diversas religiões. Eu poderia produzir um sumário e depois plotar isso num gráfico.
relig_summary <- gss_cat %>%
group_by(relig) %>%
summarise(
age = mean(age, na.rm = TRUE),
tvhours = mean(tvhours, na.rm = TRUE),
n = n()
)
relig_summary %>%
ggplot(aes(tvhours, relig)) + geom_point()
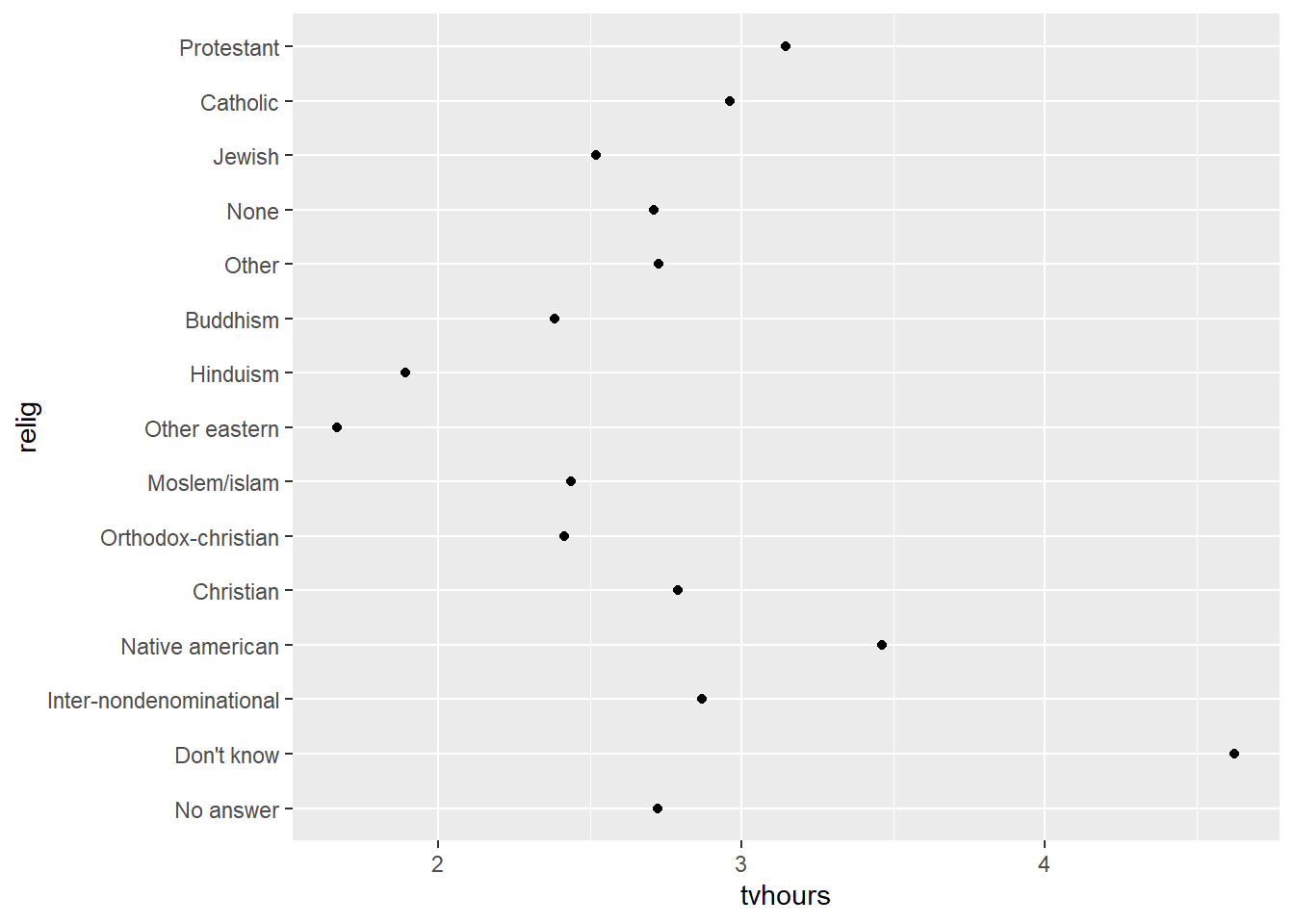
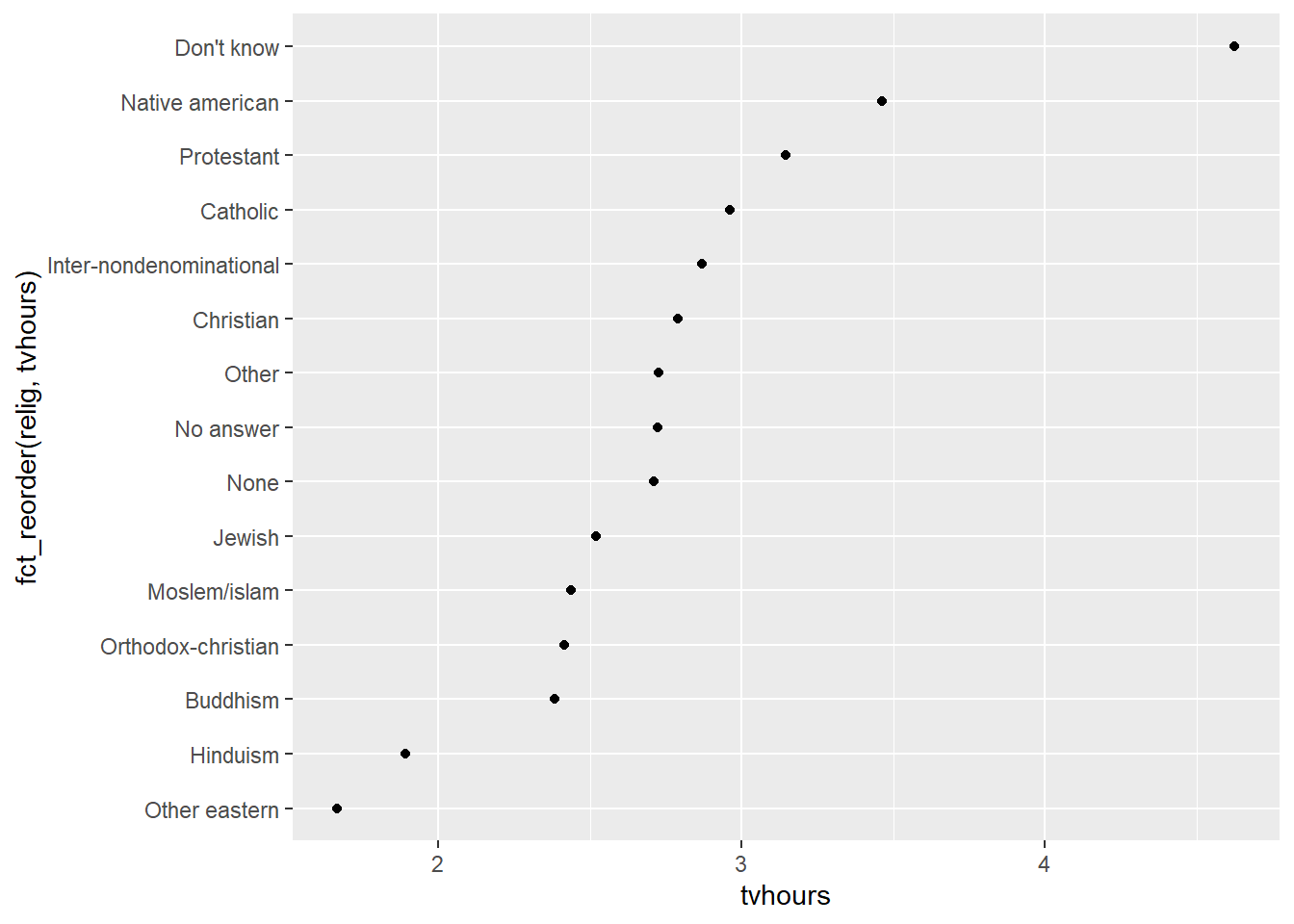
O display está técnicamente correto, mas a forma desorganizada dos níveis no eixo Y dificulta a nossa capacidade de fazer comparações. Talvez fosse mais interessante ordenar este resultado por ordem decrescente do número de horas de tv. Mas, como fazer isso de forma direta, sem precisar realizar diversas computações?
# Direto no plot
relig_summary %>%
ggplot(aes(tvhours, fct_reorder(relig, tvhours))) + geom_point()
# Antes de passar o data.frame para a plotagem
relig_summary %>%
mutate(relig = fct_reorder(relig, tvhours)) %>%
ggplot(aes(tvhours, relig)) + geom_point()
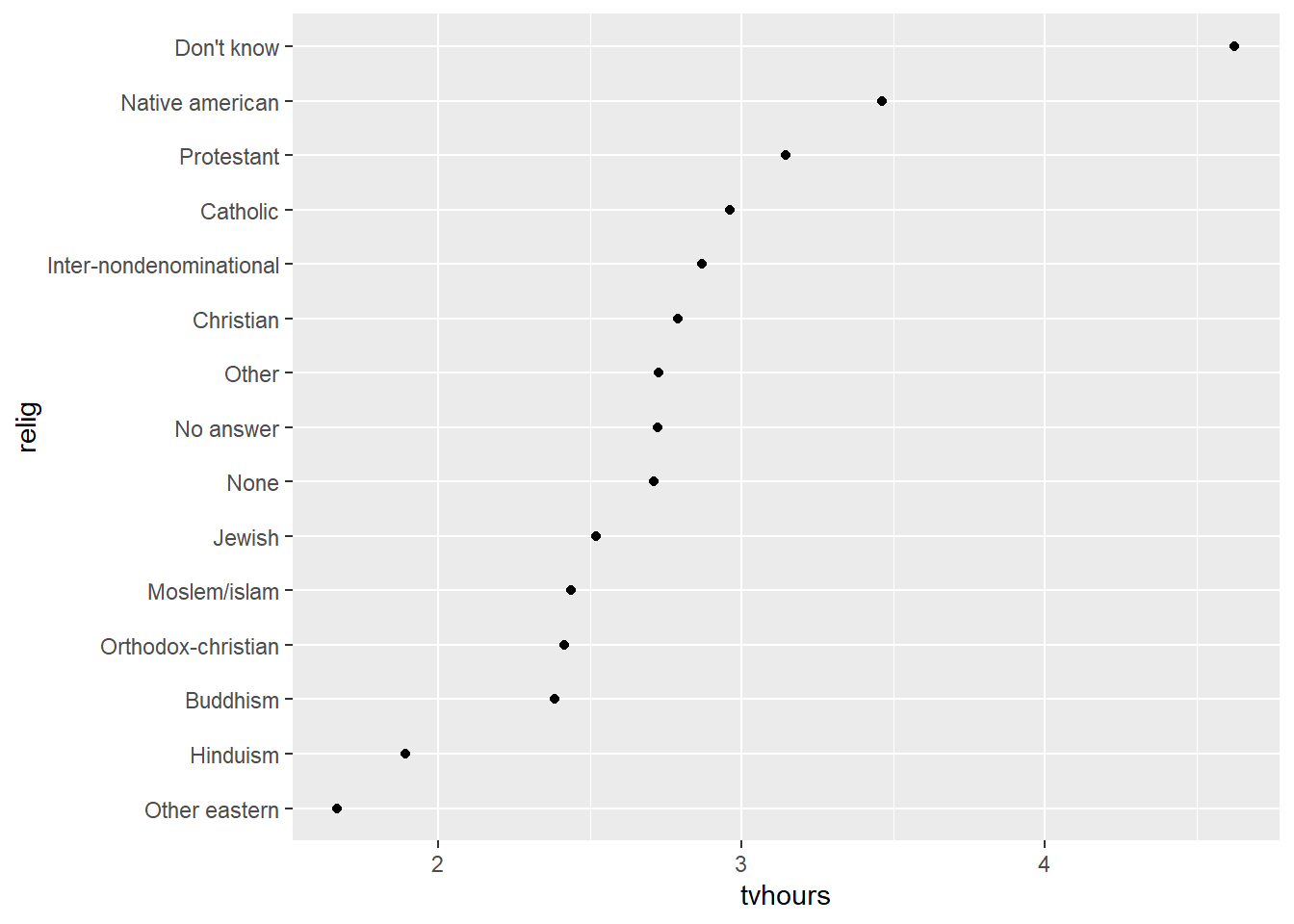
Note como posso aplicar a transformação diretamente na variável durante o processo de plotagem, ou antes, e uma invocação de mutate. Na minha opinião, o segundo jeito é o mais adequado, por duas razões: é mais fácil de digitar, inserir e retirar do código e é mais fácil para um leitor identificar que uma transformação foi feita na variável plotada.
Outro exemplo: que tal exarminarmos a relação entre a idade e a renda declarada? Primeiro, é preciso construir um sumário, parecido com o primeiro:
rincome_summary <- gss_cat %>%
group_by(rincome) %>%
summarise(
age = mean(age, na.rm = TRUE),
tvhours = mean(tvhours, na.rm = TRUE),
n = n()
)
rincome_summary %>%
mutate(rincome = fct_reorder(rincome, age)) %>%
ggplot(aes(age, rincome)) + geom_point()
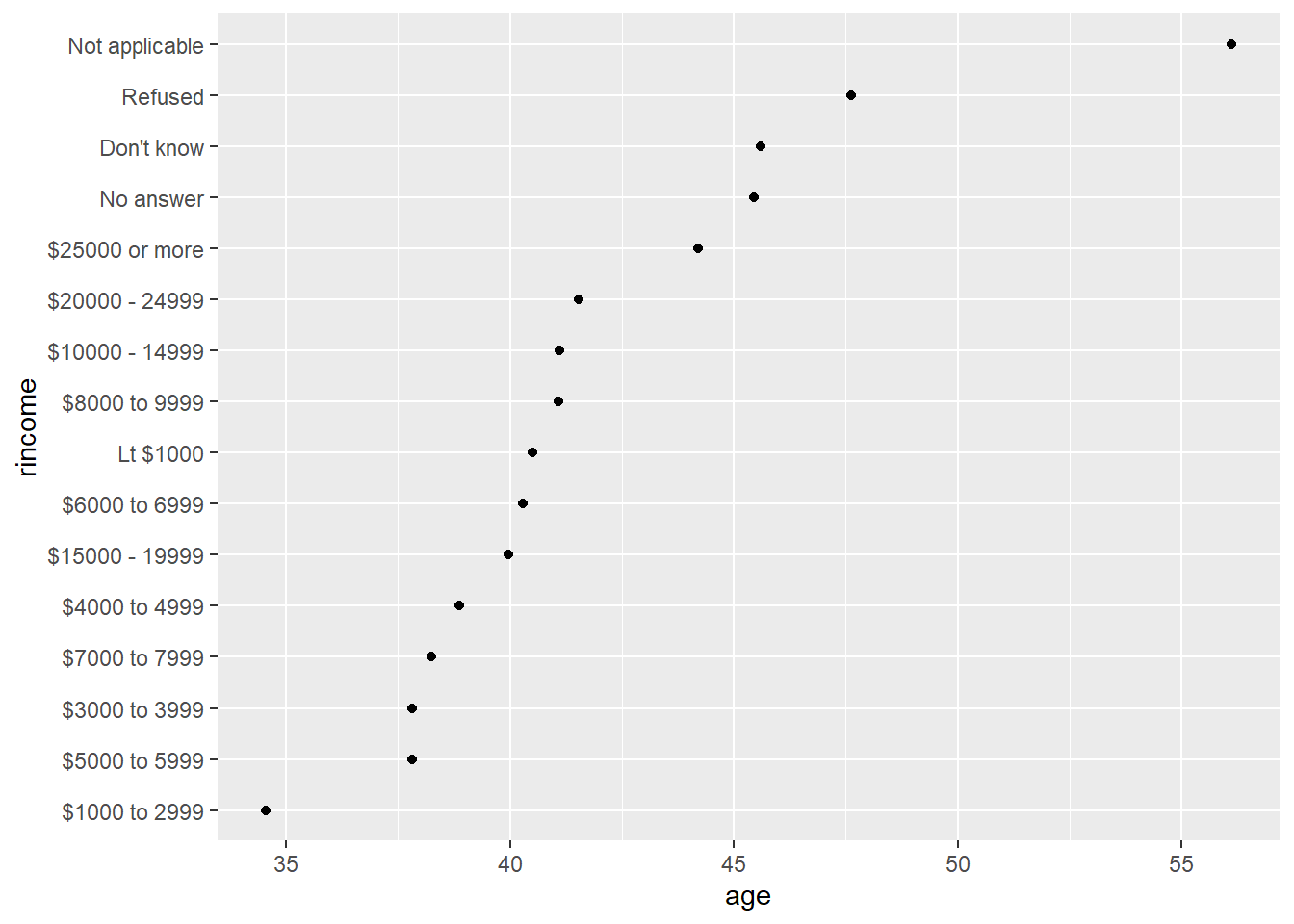
Aqui, o reordenamento das variáveis de acordo com a idade não faz muito sentido, porque os níveis de renda tem uma ordem própria. Nesse caso, não é recomendado utilizar fct_reorder.
rincome_summary %>%
ggplot(aes(age, rincome)) + geom_point()
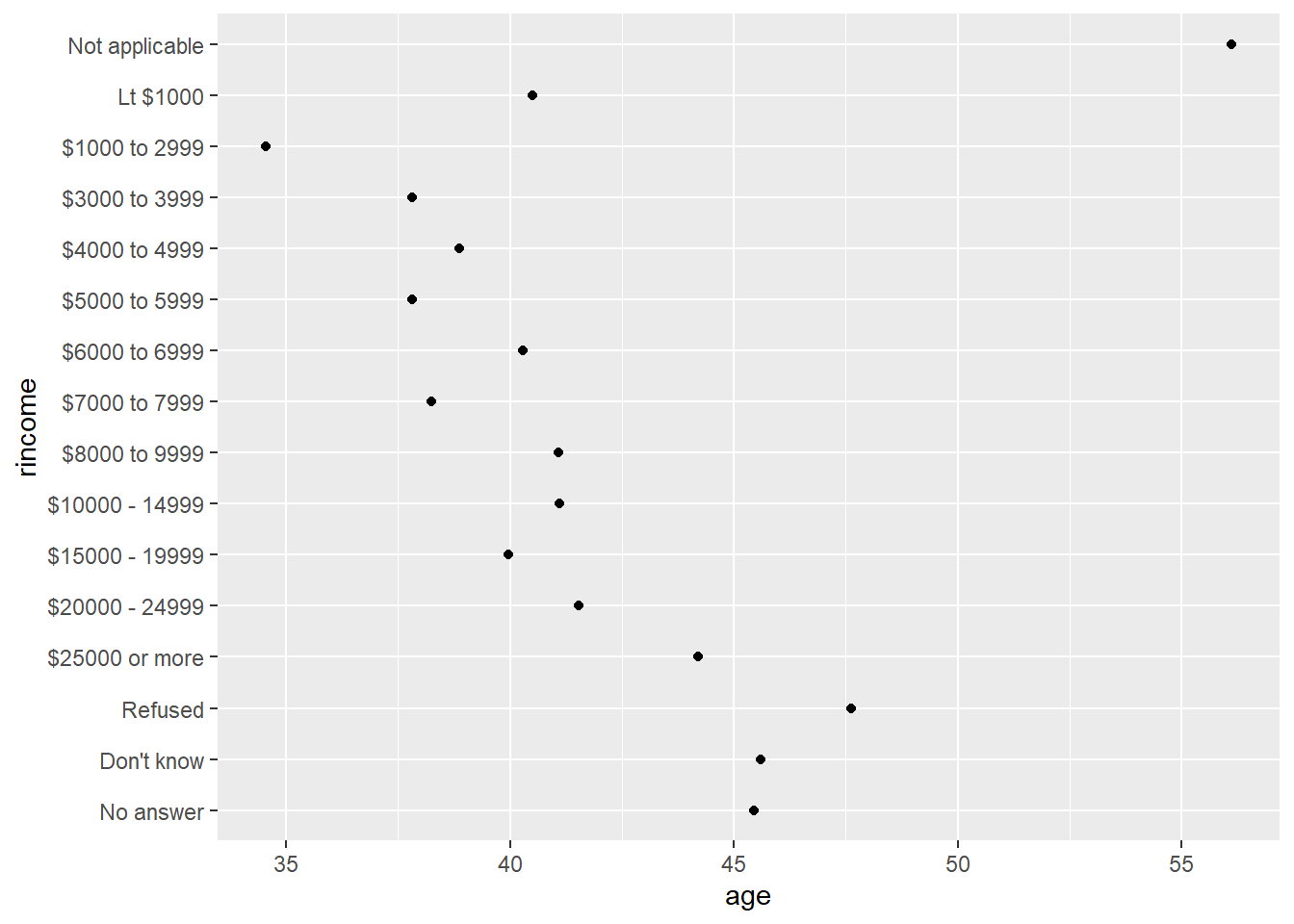
Só que ao plotar, notamos um problema: a categoria “Not applicable” ficou primeiro e isso desorganiza visualmente nosso gráfico. Sem problema! Utilizamos fct_relevel para modificar a ordem de uma variável arbitrariamente. O padrão é colocar pro começo (Parecido com o comportamento de stats::relevel), mas você pode especificar outra posição.
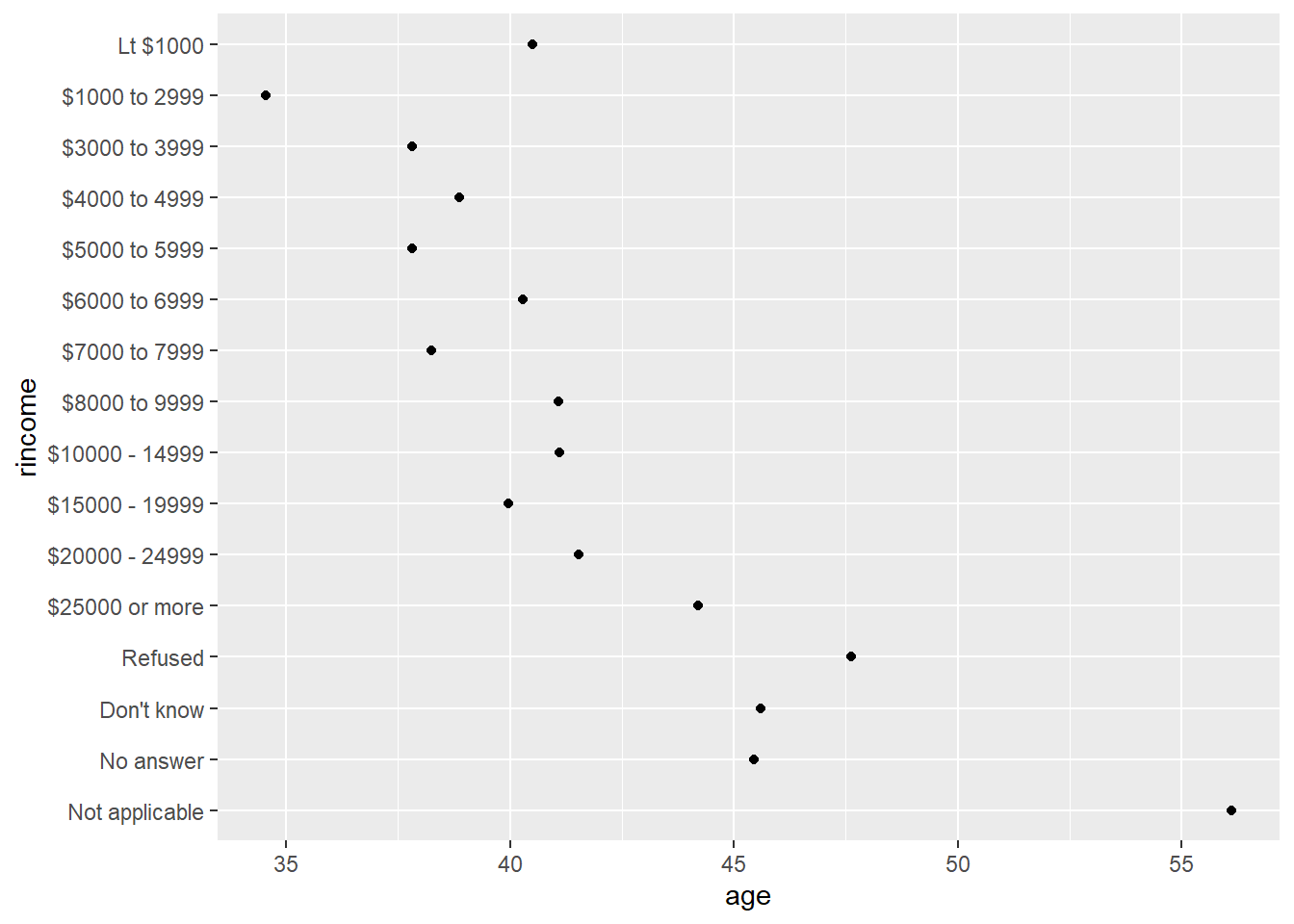
rincome_summary %>%
mutate(rincome = fct_relevel(rincome, "Not applicable")) %>%
ggplot(aes(age, rincome)) + geom_point()
Notem como nos exemplos acima, o uso do %>% nos permite alterar partes do nosso código de maneira interativa para chegar no resultado desejado.
Outro tipo de mudança de ordem interessante ocorre quando temos uma terceira “dimensão” no nosso gráfico. Em geral, utilizamos cores, formas ou linhas quebradas para diferenciar entre categorias e gostaríamos que a nossa legenda acompanhasse a tendência do gráfico. Compare:
by_age <- gss_cat %>%
filter(!is.na(age)) %>%
count(age, marital) %>%
group_by(age) %>%
mutate(prop = n / sum(n))
# Sem alteração na ordem
by_age %>%
ggplot(aes(age, prop, colour = marital)) +
geom_line(na.rm = TRUE)
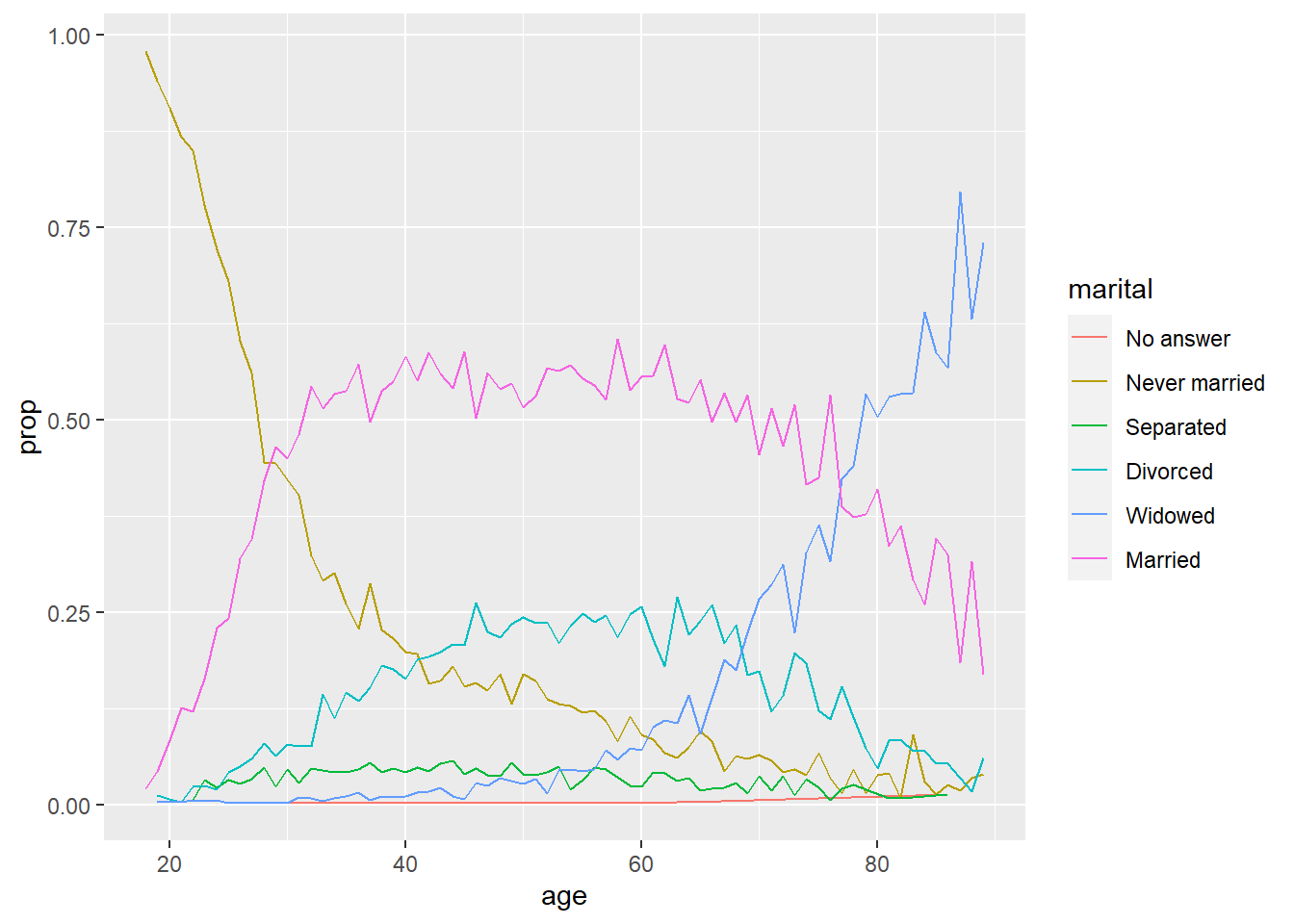
# Com alteração na ordem
ggplot(by_age, aes(age, prop, colour = fct_reorder2(marital, age, prop))) +
geom_line() +
labs(colour = "marital")
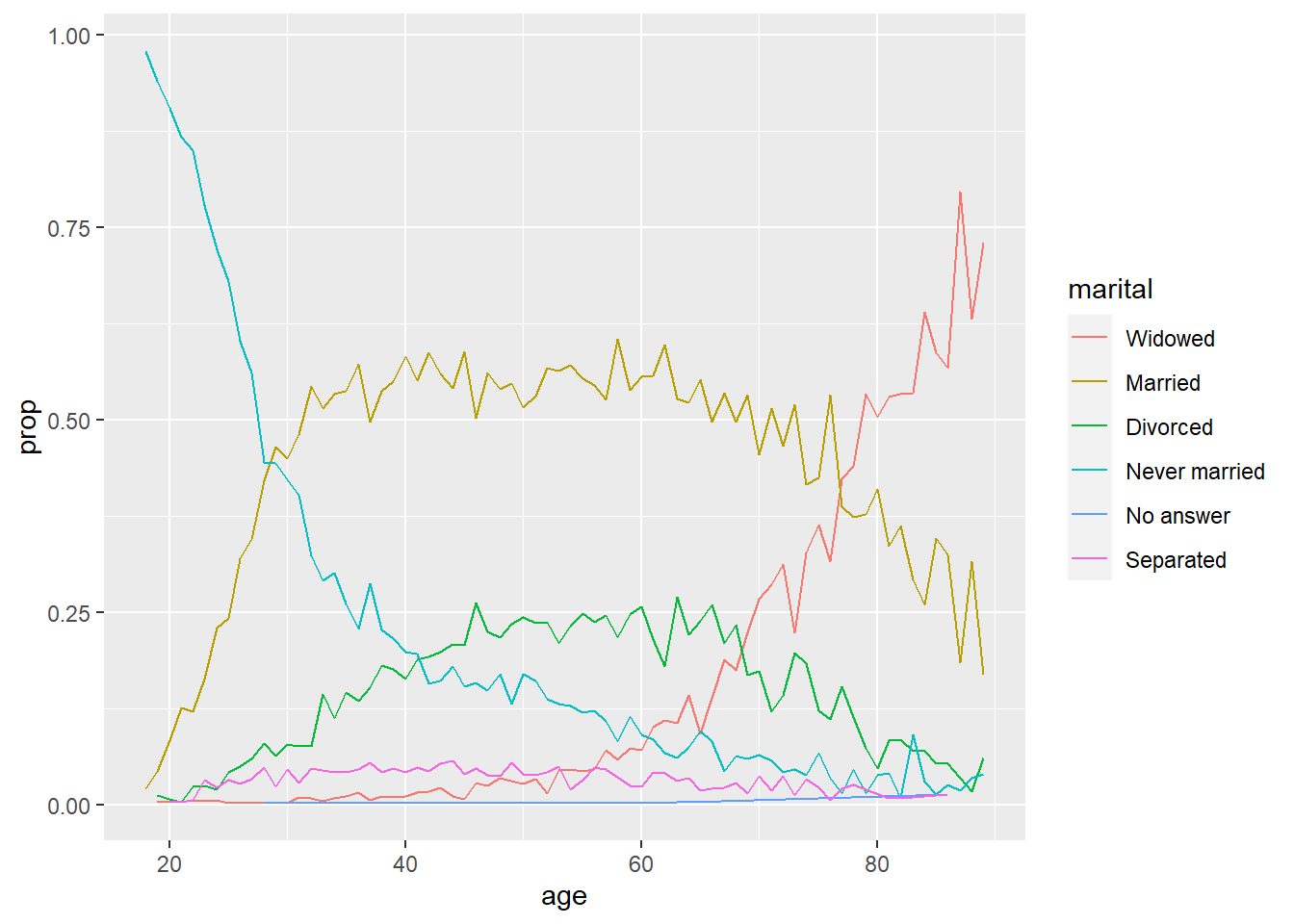
No caso de fct_reorder2, é melhor fazer a alteração de ordem dentro da função gráfica, pois dentro uma invocação de mutate, ela não funcionou durante meus testes.
Por último, podemos querer ordenar um gráfico de barras de acordo com a frequência das categorias, o que podemos fazer com fct_infreq e fct_rev (opcional).
gss_cat %>%
mutate(marital = marital %>% fct_infreq()) %>%
ggplot(aes(marital)) +
geom_bar()
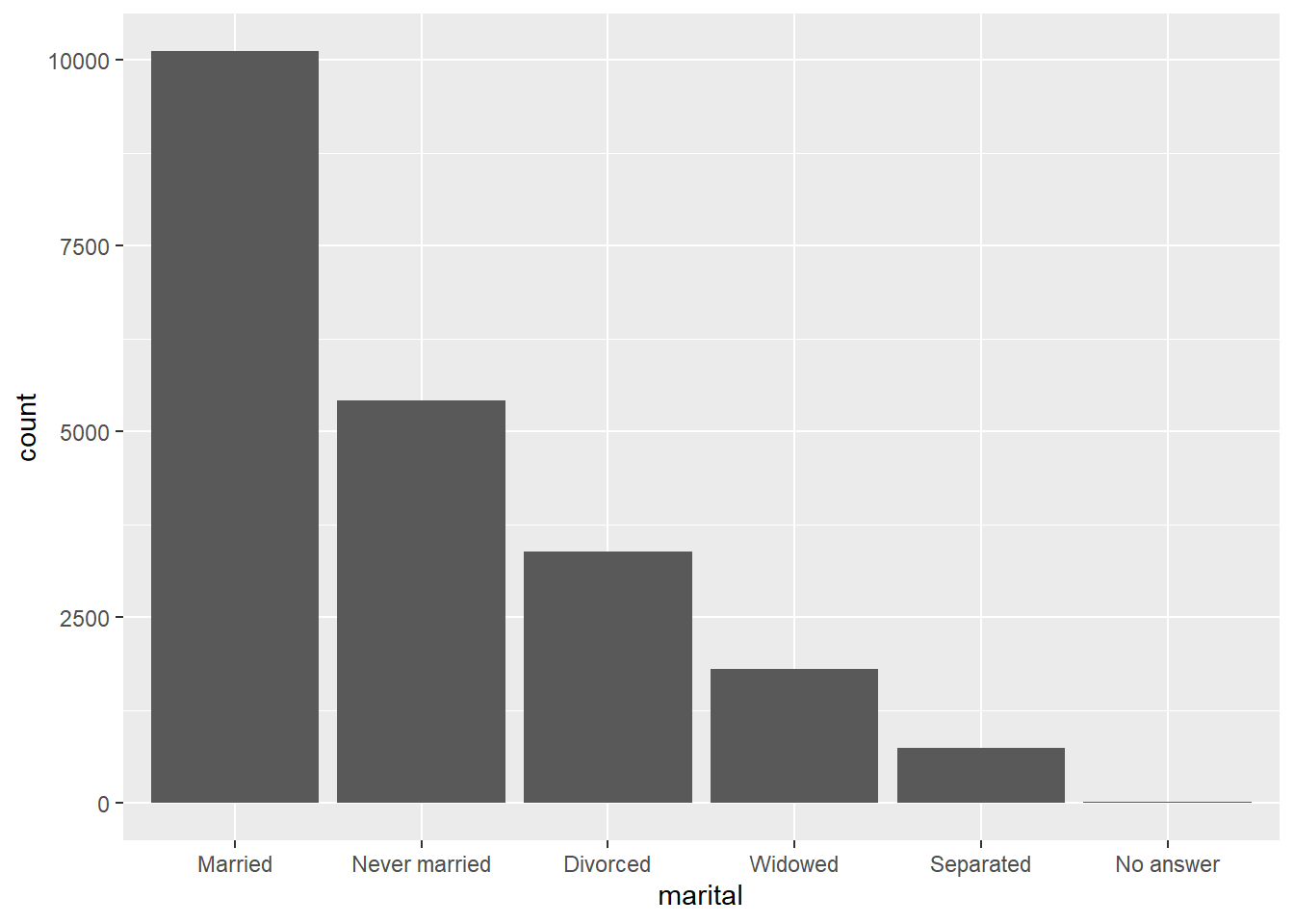
# OU
gss_cat %>%
mutate(marital = marital %>% fct_infreq() %>% fct_rev()) %>%
ggplot(aes(marital)) +
geom_bar()
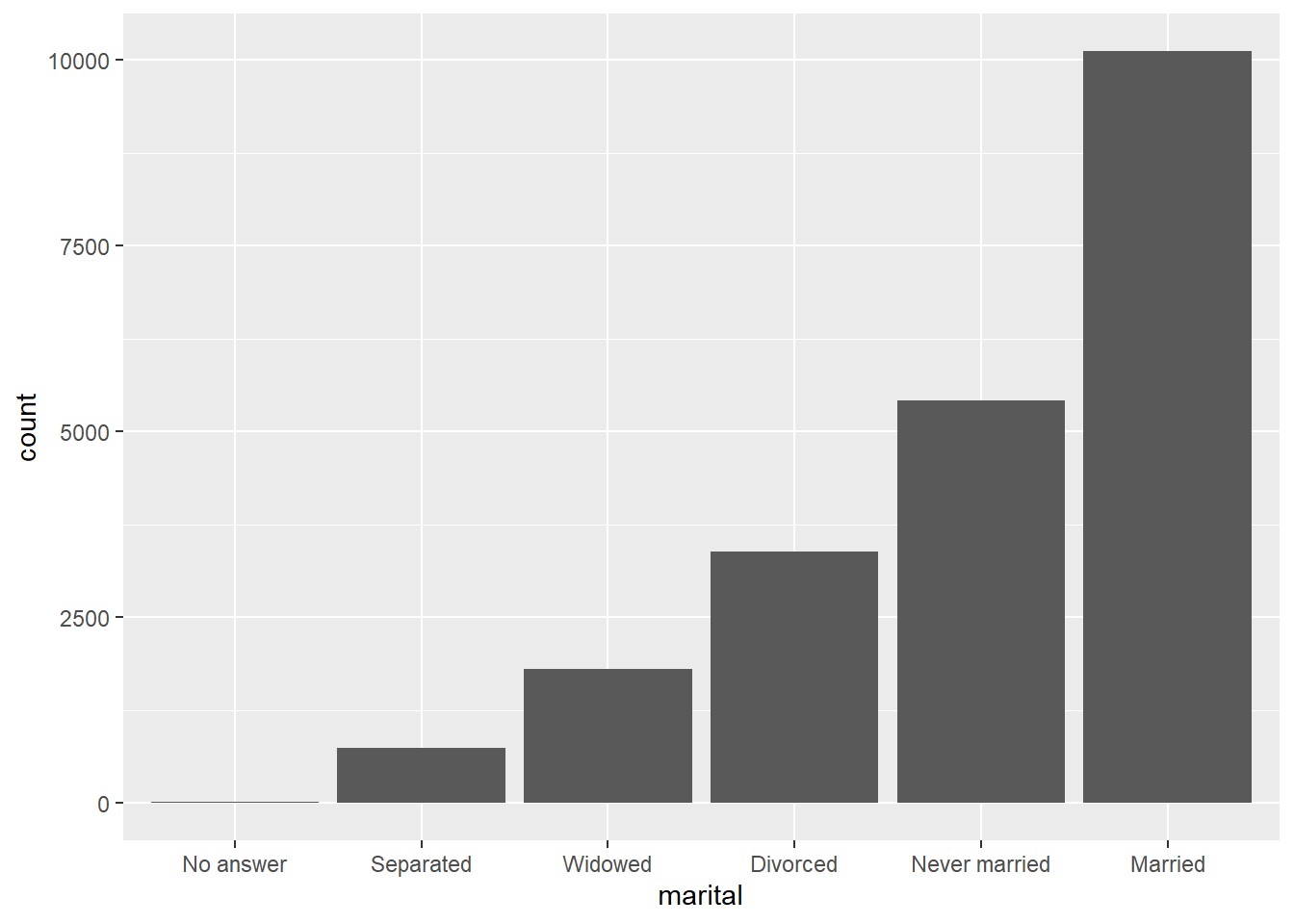
Notem o uso do pipe na hora de modificar a variável “marital.”
Modificando os níveis
O outro tipo de operação bastante comum é a alteração nos níves do fator. Em geral, queremos que os nossos níveis sejam representativos das nossas categorias de análise, sejam de fácil leitura e entendimento e contenham um número significativo de observações. Por essa razão, frequentemente precisamos alterar os rótulos, agrupar categorias, etc.
Vejamos o exemplo da variável partyid, que registra a identificação do entrevistado com os partidos políticos dos EUA.
gss_cat %>% count(partyid)
## # A tibble: 10 x 2
## partyid n
## <fct> <int>
## 1 No answer 154
## 2 Don't know 1
## 3 Other party 393
## 4 Strong republican 2314
## 5 Not str republican 3032
## 6 Ind,near rep 1791
## 7 Independent 4119
## 8 Ind,near dem 2499
## 9 Not str democrat 3690
## 10 Strong democrat 3490
Vamos supor que, por qualquer motivo, essa forma de representação das categorias não nos satisfaz. Vejamos algumas das ferramentas que podemos utilizar para modificar esse fator.
Podemos, simplesmente, reescrever essas categorias de forma mais completa:
gss_cat %>%
mutate(partyid = fct_recode(partyid,
"Republicano, forte" = "Strong republican",
"Republicano, fraco" = "Not str republican",
"Independente, próx. repub." = "Ind,near rep",
"Independente, próx. democ." = "Ind,near dem",
"Independente" = "Independent",
"Democrata, forte" = "Strong democrat",
"Democrata, fraco" = "Not str democrat",
"Outro partido" = "Other party",
"Não sei" = "Don't know",
"Sem resposta" = "No answer"
)) %>%
count(partyid)
## # A tibble: 10 x 2
## partyid n
## <fct> <int>
## 1 Sem resposta 154
## 2 Não sei 1
## 3 Outro partido 393
## 4 Republicano, forte 2314
## 5 Republicano, fraco 3032
## 6 Independente, próx. repub. 1791
## 7 Independente 4119
## 8 Independente, próx. democ. 2499
## 9 Democrata, fraco 3690
## 10 Democrata, forte 3490
A função utilizada é fct_recode e ela é a mais genérica e flexível de todas, porém, exige que cada nível seja modificado individualmente. Dentro dela, é possível agrupar vários níveis associando vários níveis antigos a um mesmo nível novo. Veja o exemplo:
gss_cat %>%
mutate(partyid = fct_recode(partyid,
"Republicano, forte" = "Strong republican",
"Republicano, fraco" = "Not str republican",
"Independente, próx. repub." = "Ind,near rep",
"Independente, próx. democ." = "Ind,near dem",
"Independente" = "Independent",
"Democrata, forte" = "Strong democrat",
"Democrata, fraco" = "Not str democrat",
# Note o nome
"Outro" = "Other party",
"Outro" = "Don't know",
"Outro" = "No answer"
)) %>%
count(partyid)
## # A tibble: 8 x 2
## partyid n
## <fct> <int>
## 1 Outro 548
## 2 Republicano, forte 2314
## 3 Republicano, fraco 3032
## 4 Independente, próx. repub. 1791
## 5 Independente 4119
## 6 Independente, próx. democ. 2499
## 7 Democrata, fraco 3690
## 8 Democrata, forte 3490
Se você quiser recategorizar um fator que tem muitos níveis para um menor, com poucos níveis, utilize fct_collapse:
gss_cat %>%
mutate(partyid = fct_collapse(partyid,
Outro = c("No answer", "Don't know", "Other party"),
Republicano = c("Strong republican", "Not str republican"),
Independente = c("Ind,near rep", "Independent", "Ind,near dem"),
Democrata = c("Not str democrat", "Strong democrat")
)) %>%
count(partyid)
## # A tibble: 4 x 2
## partyid n
## <fct> <int>
## 1 Outro 548
## 2 Republicano 5346
## 3 Independente 8409
## 4 Democrata 7180
Repare que do lado esquerdo, nos valores novos, não foi necessário usar aspas. É preciso cuidado com essa característica dos verbos do tidyverse. Ela se chama “tidy evaluation” e está um pouco fora do escopo do curso. Basicamente, se rolar dúvida ou der erros, se for usar acentos ou algum caractere diferente, use aspas.
gss_cat %>%
mutate(partyid = fct_collapse(partyid,
"Outro" = c("No answer", "Don't know", "Other party"),
"Republicano" = c("Strong republican", "Not str republican"),
"Independente" = c("Ind,near rep", "Independent", "Ind,near dem"),
"Democrata" = c("Not str democrat", "Strong democrat")
)) %>%
count(partyid)
## # A tibble: 4 x 2
## partyid n
## <fct> <int>
## 1 Outro 548
## 2 Republicano 5346
## 3 Independente 8409
## 4 Democrata 7180
Outro tipo de mudança importante no número de níveis é agrupar os níveis menos frequentes, por exemplo, para produzir uma visualização que dê maior destaque aos níveis mais frequentes. Esse é o trabalho de fct_lump.
gss_cat %>%
mutate(relig = fct_lump(relig, n = 5)) %>%
count(relig)
## # A tibble: 6 x 2
## relig n
## <fct> <int>
## 1 Christian 689
## 2 None 3523
## 3 Jewish 388
## 4 Catholic 5124
## 5 Protestant 10846
## 6 Other 913
Note que usando o argumento n eu indico quantos níveis eu quero. No caso, escolhi os 5 níveis mais frequentes e todos os outros são automáticamente agrupados na categoria “Other.” Posso mudar esse nome também:
gss_cat %>%
mutate(relig = fct_lump(relig, n = 5, other_level = "Outros")) %>%
count(relig)
## # A tibble: 6 x 2
## relig n
## <fct> <int>
## 1 Christian 689
## 2 None 3523
## 3 Jewish 388
## 4 Catholic 5124
## 5 Protestant 10846
## 6 Outros 913
Exercícios
-
Encontre os vôos que:
- Atrasaram mais de duas horas
- Com destino a Houston (
IAHouHOU) - Operados pela United, American ou Delta
- Decolaram entre julho e setembro
- Chegaram com mais de duas horas de atraso, mas não decolaram com atraso
- Atrasaram mais de uma hora para decolar, mas recuperaram mais de 30 minutos durante o voo
- Decolaram entre a meia-noite e 6 da manhã (inclusive)
-
Reordene suas colunas para encontrar os voos mais rápidos (maior velocidade de voo).
-
Teste várias maneiras diferentes de selecionar as variáveis
dep_time,dep_delay,arr_timeearr_delayusando as várias helper functions deselect. -
As variáveis
dep_timeesched_dep_timeestão num formato incorreto (veja?flights). Converta-as commutatepara um valor em minutos passados desde a meia-noite. Dica: utilize%/%e%%. -
O que o código abaixo está fazendo? Porque mesmo após o código abaixo continuam existindo diferenças entre os valores das variáveis
air_timeetravel_time?
flights %>%
select(air_time, dep_time, arr_time, dep_delay, arr_delay) %>%
mutate(dep_hour = dep_time %/% 100,
dep_min = dep_time %% 100,
dep_time2 = dep_hour * 60 + dep_min,
arr_hour = arr_time %/% 100,
arr_min = arr_time %% 100,
arr_time2 = arr_hour * 60 + arr_min,
travel_time = arr_time2 - dep_time2) %>%
select(-dep_hour, -dep_min, -arr_hour, -arr_min)
## # A tibble: 336,776 x 8
## air_time dep_time arr_time dep_delay arr_delay dep_time2 arr_time2
## <dbl> <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 227 517 830 2 11 317 510
## 2 227 533 850 4 20 333 530
## 3 160 542 923 2 33 342 563
## 4 183 544 1004 -1 -18 344 604
## 5 116 554 812 -6 -25 354 492
## 6 150 554 740 -4 12 354 460
## 7 158 555 913 -5 19 355 553
## 8 53 557 709 -3 -14 357 429
## 9 140 557 838 -3 -8 357 518
## 10 138 558 753 -2 8 358 473
## # ... with 336,766 more rows, and 1 more variable: travel_time <dbl>
- Use o stringr para concatenar as seguintes strings em uma frase
x <- "."
y <- "feliz"
w <- "acordei"
z <- "hoje"
- Corrija as inconsistências nas colunas país, primeiro_nome, segundo_nome e crie uma nova coluna nomes contendo as duas anteriores. No final, ordene o banco em ordem alfabética.
df <-
tibble::tribble(
~pais, ~primeiro_nome, ~segundo_nome,
# -------|----------------|-------------|
"BRASIL", "ISABELA", "MARTINS",
"Brasil", "Eduardo", "cabellos",
"brasil", "márcia", "pinto",
"bRaSiL", "rogério", "Marinho",
)
- Transforme a string
c("Seu nome", "Seu sobrenome da mãe", "Seu sobrenome do pai")na string"SEU SOBRENOME DO PAI, sua inicial do nome. sua inicial da mãe.", como numa citação. Veja o exemplo abaixo:
# Transforme
c("Vinícius", "de Souza", "Maia")
## [1] "Vinícius" "de Souza" "Maia"
# Resultado
"MAIA, V. S."
## [1] "MAIA, V. S."
- DESAFIO: Nos microdados da área de saúde, é comum que a variável idade esteja registrada da seguinte forma: “150,” “219,” “312,” “471.” Esses códigos indicam primeiro qual a unidade de medida da idade e segundo o valor desta unidade, 1 = horas, 2 = dias, 3 = meses, 4 = anos. Proponha um código usando
stringrpara transformar o vetor abaixo em um valor numérico.
# Não precisa se preocupar com essa parte
x <- as.character(round(c(
runif(25, 100, 124),
runif(25, 201, 230),
runif(25, 301, 312),
runif(25, 401, 499)
)))
# Como você transformaria esse vetor em número?
x
## [1] "115" "113" "119" "121" "118" "116" "100" "108" "113" "119" "121" "103"
## [13] "116" "111" "111" "115" "114" "102" "116" "103" "120" "115" "123" "103"
## [25] "119" "230" "228" "225" "214" "225" "206" "207" "208" "202" "210" "229"
## [37] "204" "207" "215" "218" "223" "221" "205" "214" "220" "227" "202" "224"
## [49] "214" "201" "305" "310" "309" "310" "305" "305" "309" "303" "312" "310"
## [61] "303" "302" "305" "303" "304" "306" "309" "304" "303" "309" "306" "311"
## [73] "306" "307" "310" "417" "477" "470" "493" "414" "446" "402" "423" "476"
## [85] "432" "490" "499" "429" "414" "455" "409" "462" "447" "483" "458" "471"
## [97] "402" "423" "464" "483"
-
Explore as contagens da variável
rincomeemgss_cat, ela ficaria bem representada num gráfico? De qual tipo? -
Qual a religião mais comum em
gss_cat? Qual o partido (partyid) mais popular? -
A que religião se refere a variável
denom? Você pode descobrir isso fazendo uma tabela de contagens? -
Como você poderia diminuir o número de categorias da variável
rincomedo bancogss_cat?