ggplot2
O pacote ggplot2 e a “gramática dos gráficos”
Ainda me lembro da primeira vez que li o terceiro capítulo de R for Data Science em que o conceito de visualização de dados é apresentado junto com a ideia de data.frame e o código utilizado para gerar o gráfico. Acho que se o termo sobrecarga infromacional não existisse, eu teria inventado ele na hora.
Anedotas a parte, não é culpa do autor. O livro pressupõe um certo conhecimento prévio que eu não tinha quando o li pela primeira vez. Imagino que a maioria de vocês já viu gráficos na vida e até construiu um ou dois deles usando esse ou outros softwares estatísticos. O que talvez nem todos tenham claro na mente é que os gráficos são uma codificação num sistema de coordenadas das informações presentes em um banco de dados através de escalas. Vamos destrinchar um pouco melhor isso:
Suponha que você tenha o banco de dados mpg, presente na biblioteca ggplot2.
library(ggplot2)
mpg
## # A tibble: 234 x 11
## manufacturer model displ year cyl trans drv cty hwy fl class
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
## 1 audi a4 1.8 1999 4 auto(l~ f 18 29 p comp~
## 2 audi a4 1.8 1999 4 manual~ f 21 29 p comp~
## 3 audi a4 2 2008 4 manual~ f 20 31 p comp~
## 4 audi a4 2 2008 4 auto(a~ f 21 30 p comp~
## 5 audi a4 2.8 1999 6 auto(l~ f 16 26 p comp~
## 6 audi a4 2.8 1999 6 manual~ f 18 26 p comp~
## 7 audi a4 3.1 2008 6 auto(a~ f 18 27 p comp~
## 8 audi a4 quat~ 1.8 1999 4 manual~ 4 18 26 p comp~
## 9 audi a4 quat~ 1.8 1999 4 auto(l~ 4 16 25 p comp~
## 10 audi a4 quat~ 2 2008 4 manual~ 4 20 28 p comp~
## # ... with 224 more rows
De posse desse banco, você gostaria de construir um gráfico relacionando a eficiência do combustível de um carro (hwy) com o seu peso (displ). Sábio e malandro no ggplot2, você escreve o código a seguir:
ggplot(mpg, aes(displ,hwy, color = class)) +
geom_point()
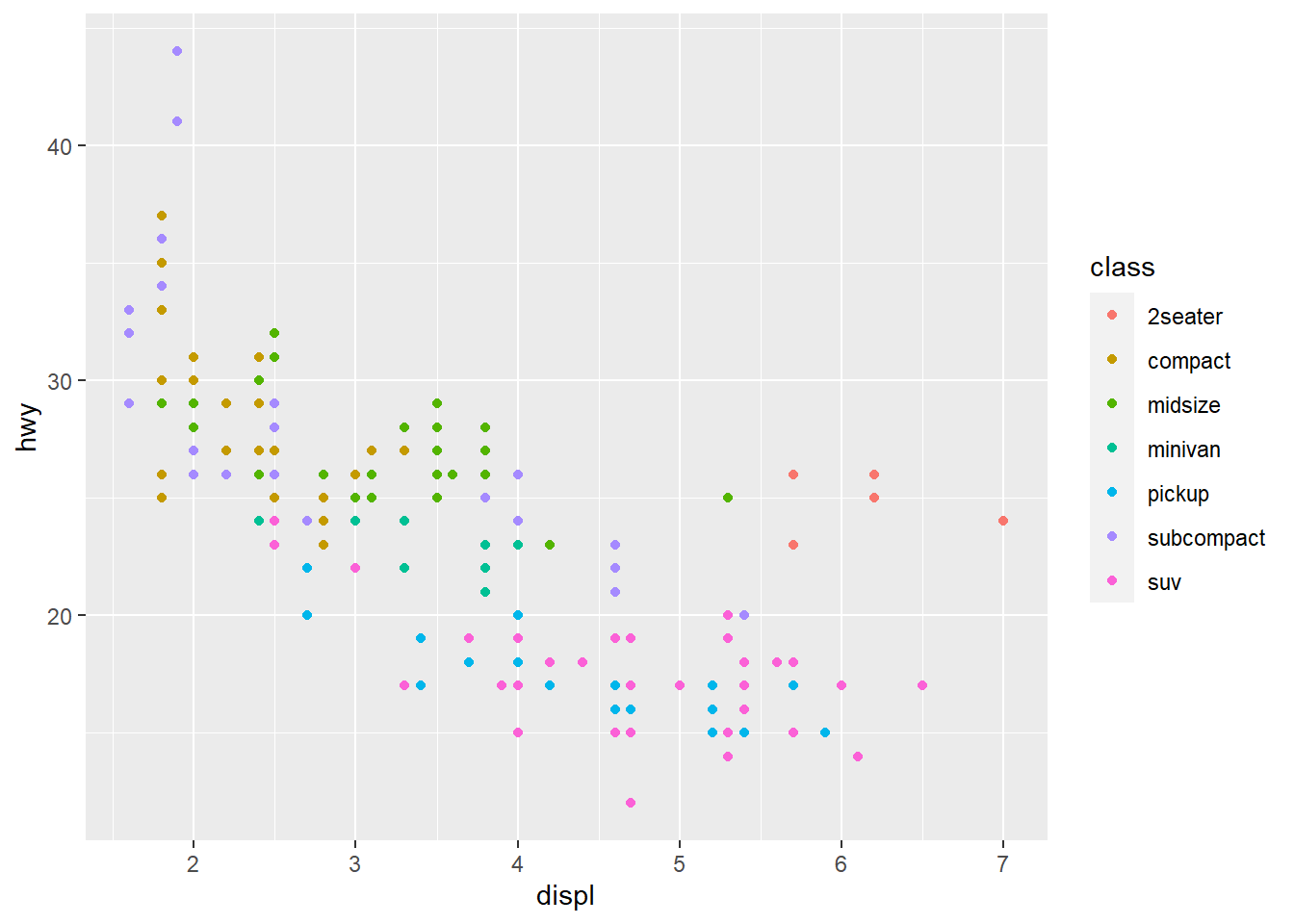
Mas fica a dúvida: que escolhas foram feitas no momento de traduzir a minha intenção de produzir um diagrama de dispersão (scatterplot) do peso com o consumo de gasolina para a representação gráfica diante de nós? Que unidades de medidas estão dispostas nos eixos X e Y? Qual o sistema de coordenadas no qual isto foi representado? Quem define os limites de início e fim de cada eixo? Como cada ponto recebeu a sua cor? Essas perguntas podem parecer óbvias ou tontas, dependendo da perspectiva e da experiência do usuário, mas elas são centrais para entender como construir e modificar gráficos no ggplot2.
O pacote é inspirado pela Gramática dos Gráficos, e procura decompor o processo de produção de gráficos em uma sequência de camadas que vão se sobrepondo até chegar no objeto desejado.
- a camada dos dados e do mapeamento estético (que variáveis vão em quais eixos/escalas)
- a camada dos objetos geométricos (pontos, linhas, barras, etc.)
- a camada das escalas (natural? logarítmica? escala de cores?)
- a camada das facetas (mini gráficos separados por alguma característica)
- a camada das transformações estatísticas (distribuições de probabilidade, contagens, proporções, etc.)
- o sistema de coordenadas (cartesiano? polar?)
Obviamente, nem todo gráfico possui essa complexidade, e na verdade, a maioria dos gráficos que fazemos se encaixa num pequeno subgrupo de todas essas especificações, então porque toda essa complexidade?
Porque não? Em primeiro lugar, se você está produzindo visualizações simples que cumprem seu propósito, você não precisa se preocupar com quase nada disso, os padrões do ggplot2, via de regra, se encaixam perfeitamente na maioria dos problemas e, em segundo lugar, se você sentir a necessidade de ir mais fundo e produzir visualizações mais complexas, as mesmas ferramentas que você já conhece estão a sua disposição.
Três gráficos para entender a mecânica do ggplot2
Scatterplots
Voltemos para o nosso gráfico original, vamos decompô-lo em suas camadas como se estivéssemos construindo ele passo-a-passo:
# Primeiro, a camada dos dados e mapeamentos estéticos
ggplot(
# Dados
data = mpg,
# Que variável vai em que eixo
mapping = aes(x = displ, y = hwy)
)
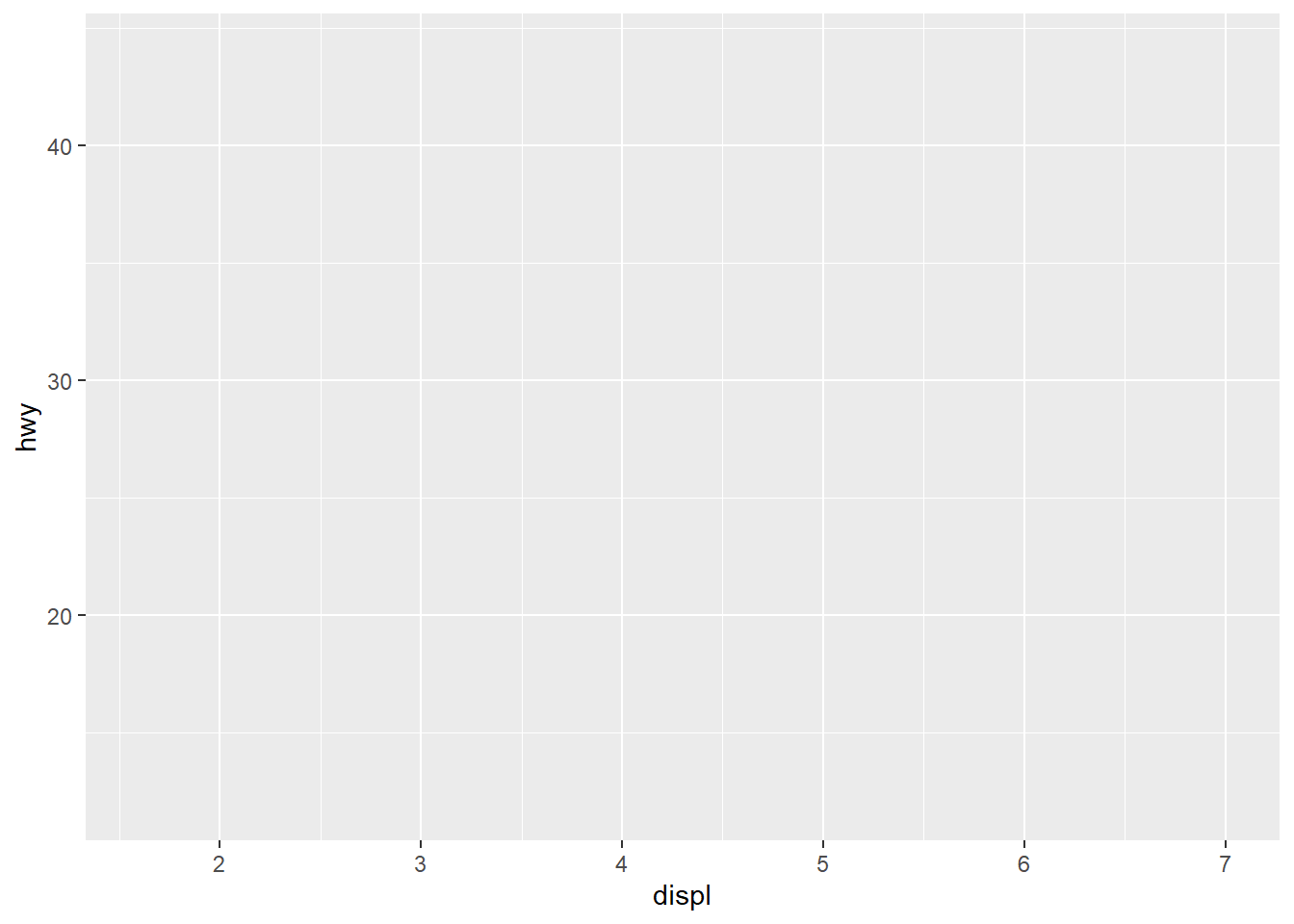
Examinando a saída, vemos que ggplot desenhou um canvas com nossas variáveis, mas ainda nenhum objeto geométrico. Tudo bem, adicionamos (+) uma camada de objetos geométricos, no caso, pontos.
# Objetos geométricos começam com "geom_"
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + # adicionamos
geom_point()
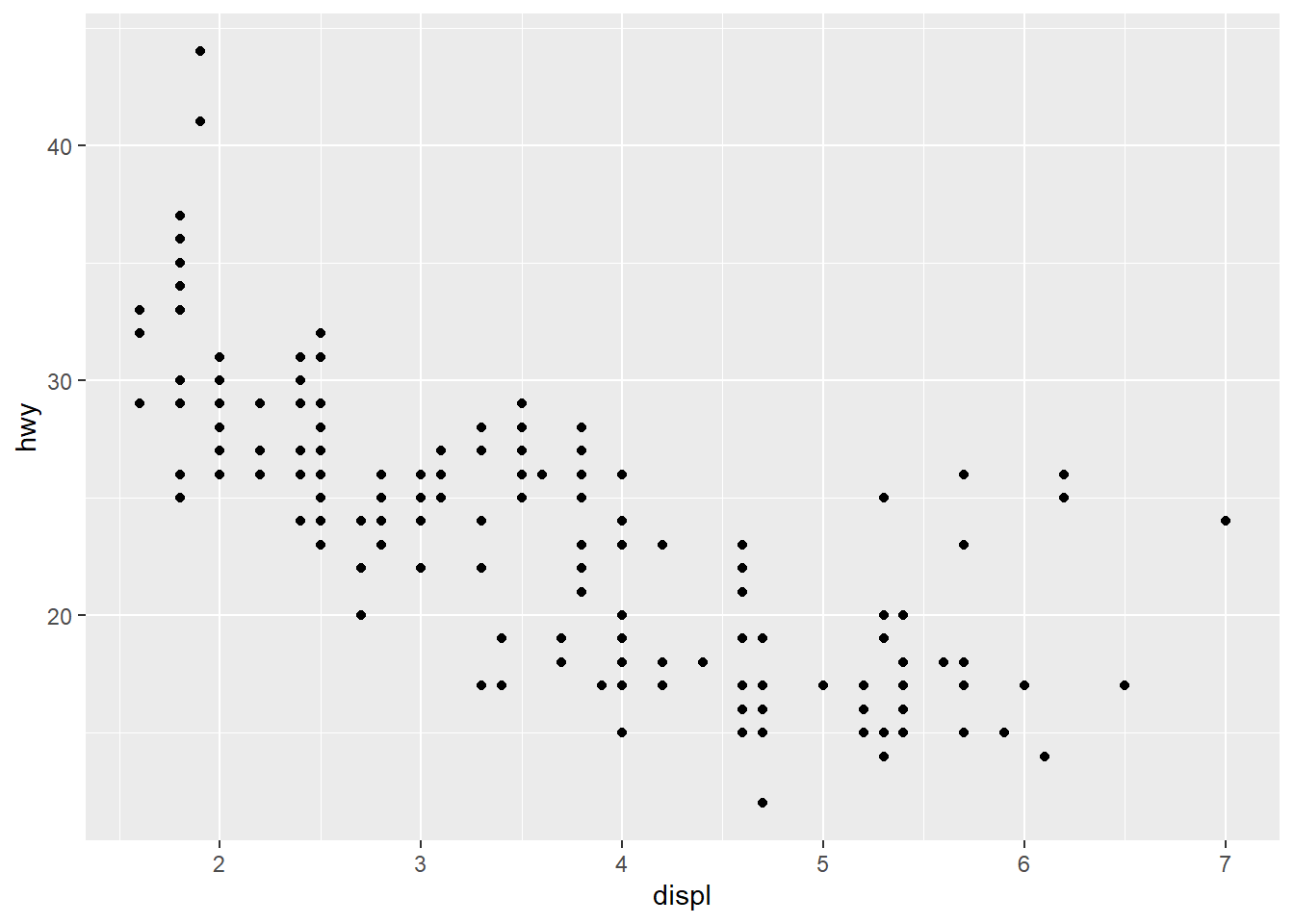
Agora, nosso gráfico já tem uma cara de diagrama de dispersão. Mas ainda não tem as cores das classes de automóvel. Tudo bem, voltamos para a primeira camada e informamos que queremos um terceiro mapeamento estético.
# A cor é mapeada a variável class
ggplot(data = mpg,
mapping = aes(
x = displ, y = hwy,
color = class) # novo mapeamento estético
) + # adicionamos
geom_point()
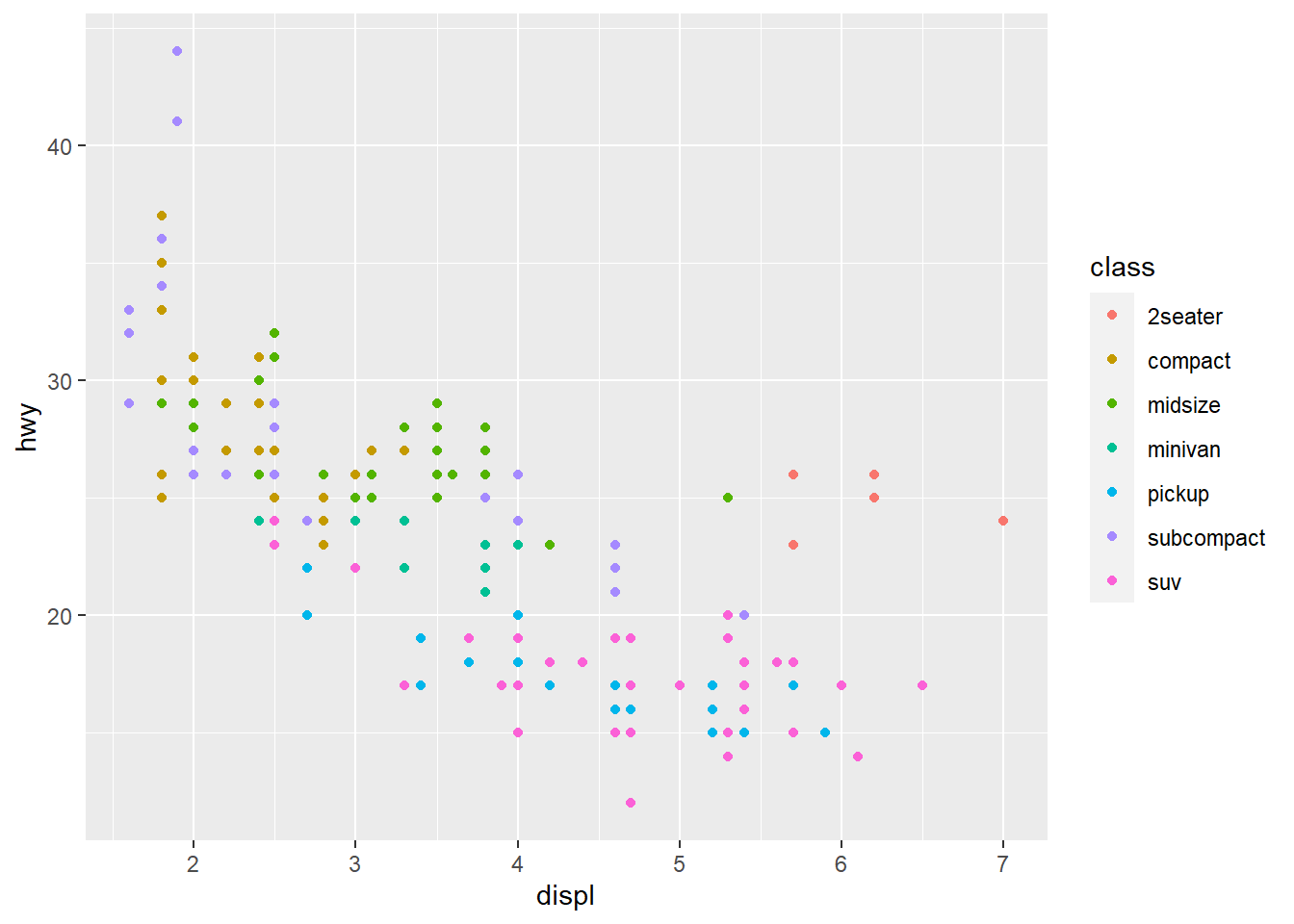
Ok, chegamos no gráfico original. Mas como podem entender melhor as outras camadas? Vamos pensar, por exemplo, que talvez queiramos trabalhar a variável hwy numa escala logarítmica. Poderíamos transformar a variável original, claro, mas o ggplot2 nos permite especificar as transformações diretamente nas escalas do gráfico!
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = class)) +
geom_point() + # adicionando uma nova "camada"
scale_y_continuous(trans = "log")

Mas você, leitor, não ficou satisfeito. Você queria era transformar a variável displ em raíz quadrada. Tudo bem:
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = class)) +
geom_point() +
scale_x_continuous(trans = "sqrt") # especificamos a transformação na escala de x
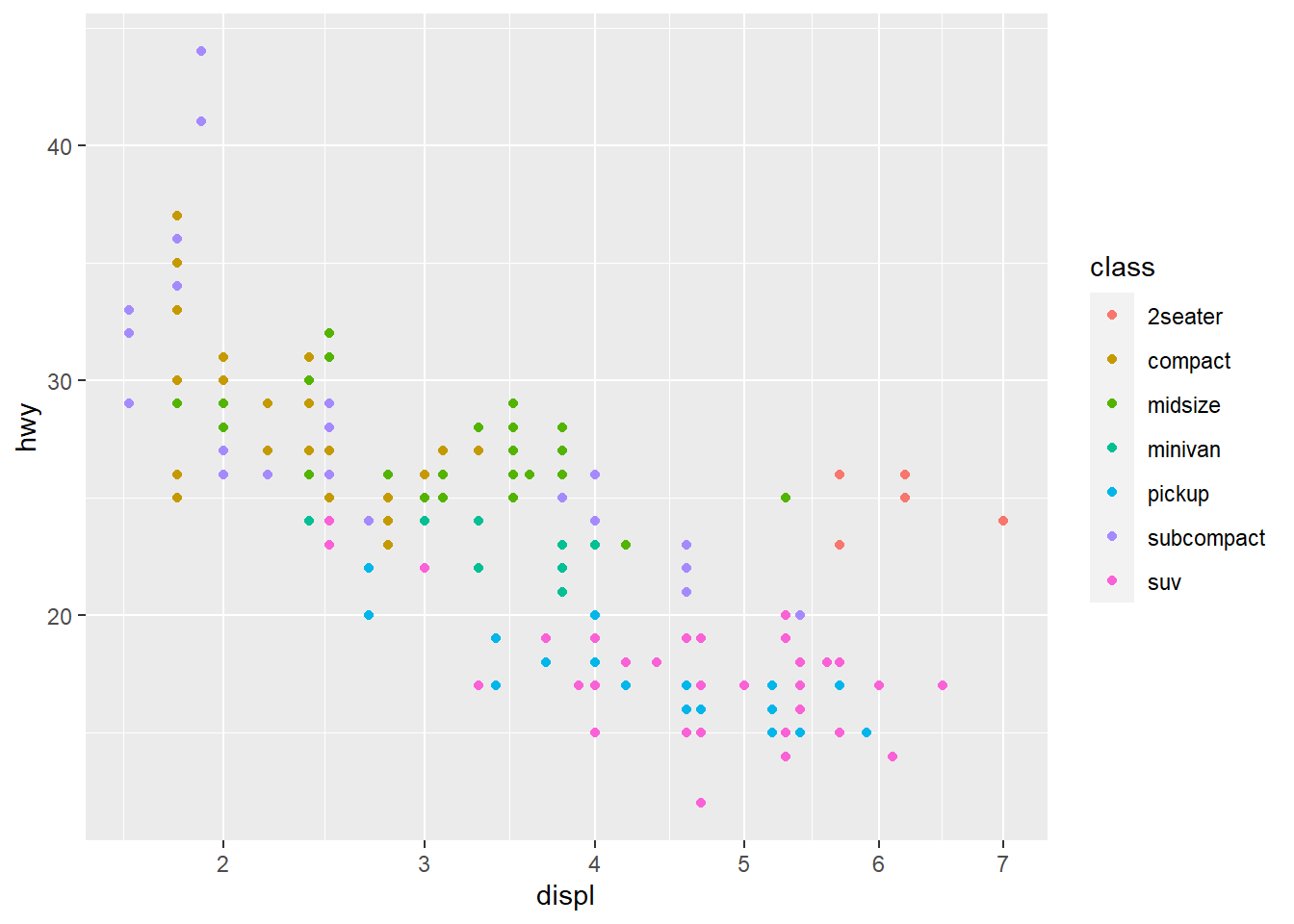
Outro leitor não estava interessado nas escalas dos eixos x ou y, que são contínuas nesse caso, mas sim na seleção de cores utilizadas para representar a escala das cores. Por ser um leitor conhecedor das formas de deficiência visual cromática, ele optou pelas paletas de cores do Colorbrewer:
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = class)) +
geom_point() +
scale_color_brewer(palette = "Set1") # transformação da escala de cores
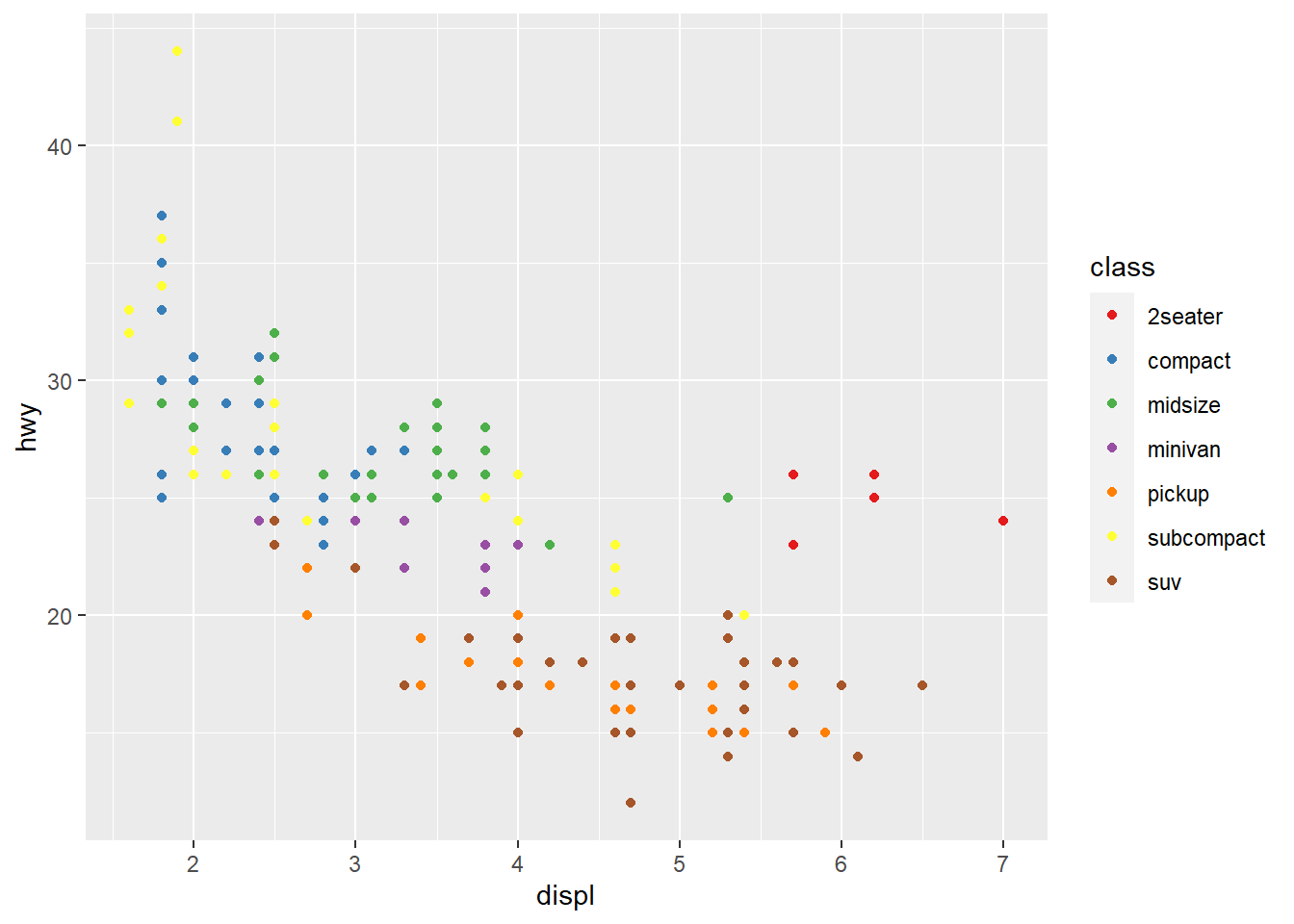
Um geógrafo entrou na conversa e disse que o sistema cartesiano de coordenadas estava iludindo os leitores a pensar que a relação entre peso e consumo de combustível estava distorcida pelas diferenças entre as unidades de medida das variáveis, produzida pelo sistema cartesiano de coordenadas, então ele sugeriu que usássemos um sistema de coordenadas fixas:
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = class)) +
geom_point() +
scale_color_brewer(palette = "Set1") +
coord_fixed()
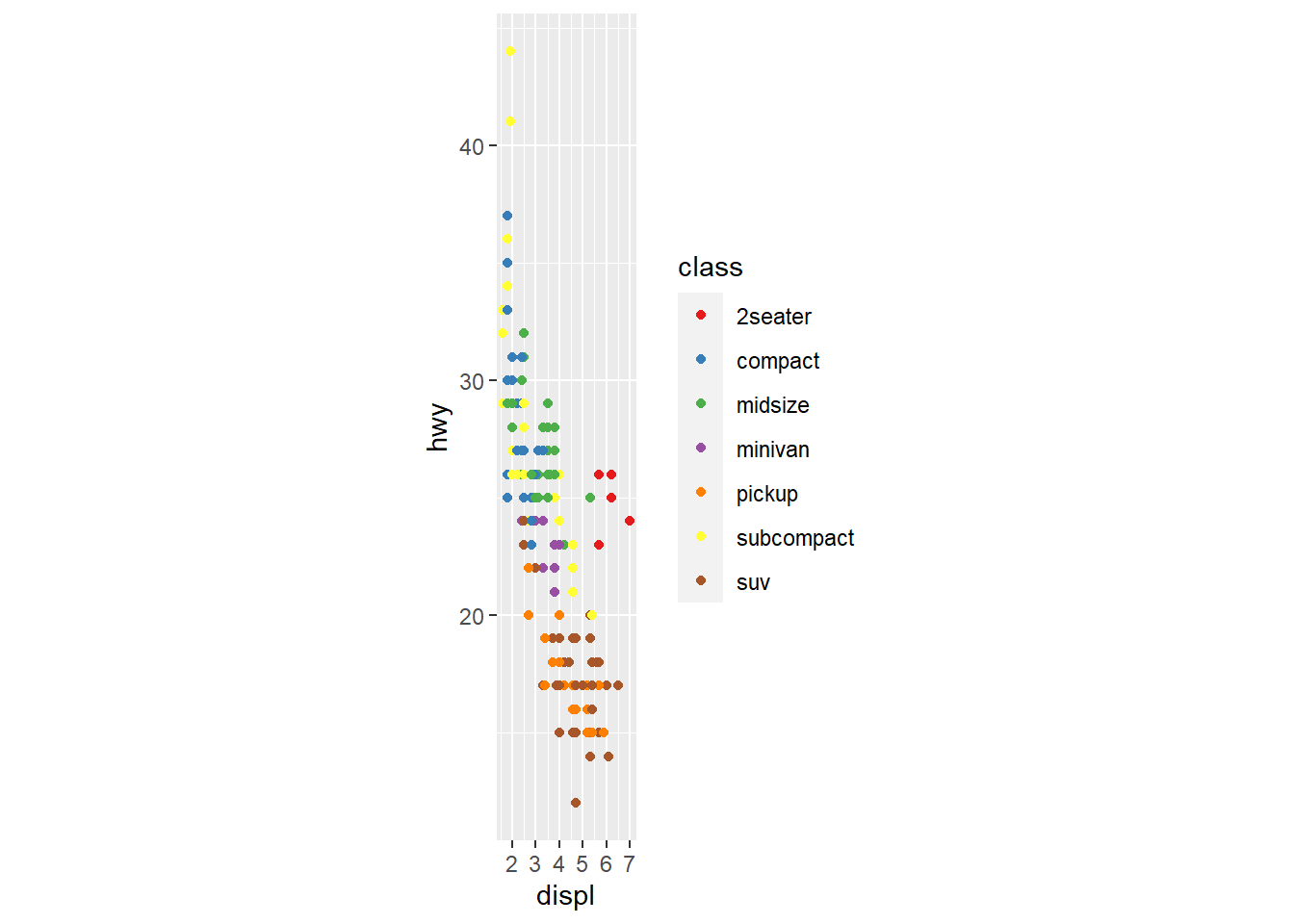
Ficou horrível, esse geógrafo não sabe nada. Como recompensa pela sua ignorância, agora ele ocupa um cargo no primeiro escalão do Ministério da Saúde.
Outro pesquisador estava interessado em visualizar as relações entre consumo, peso e classe, mas levando em consideração o fabricante do veículo, então, ele sugeriu que construíssemos um gráfico para cada. Você, que é preguiçoso, usou a capacidade do ggplot2 de dividir gráficos através da introdução de uma camada de facets.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = class)) +
geom_point() +
scale_color_brewer(palette = "Set1") + # adicionamos mais uma camada
facet_wrap(~manufacturer) # de facetas
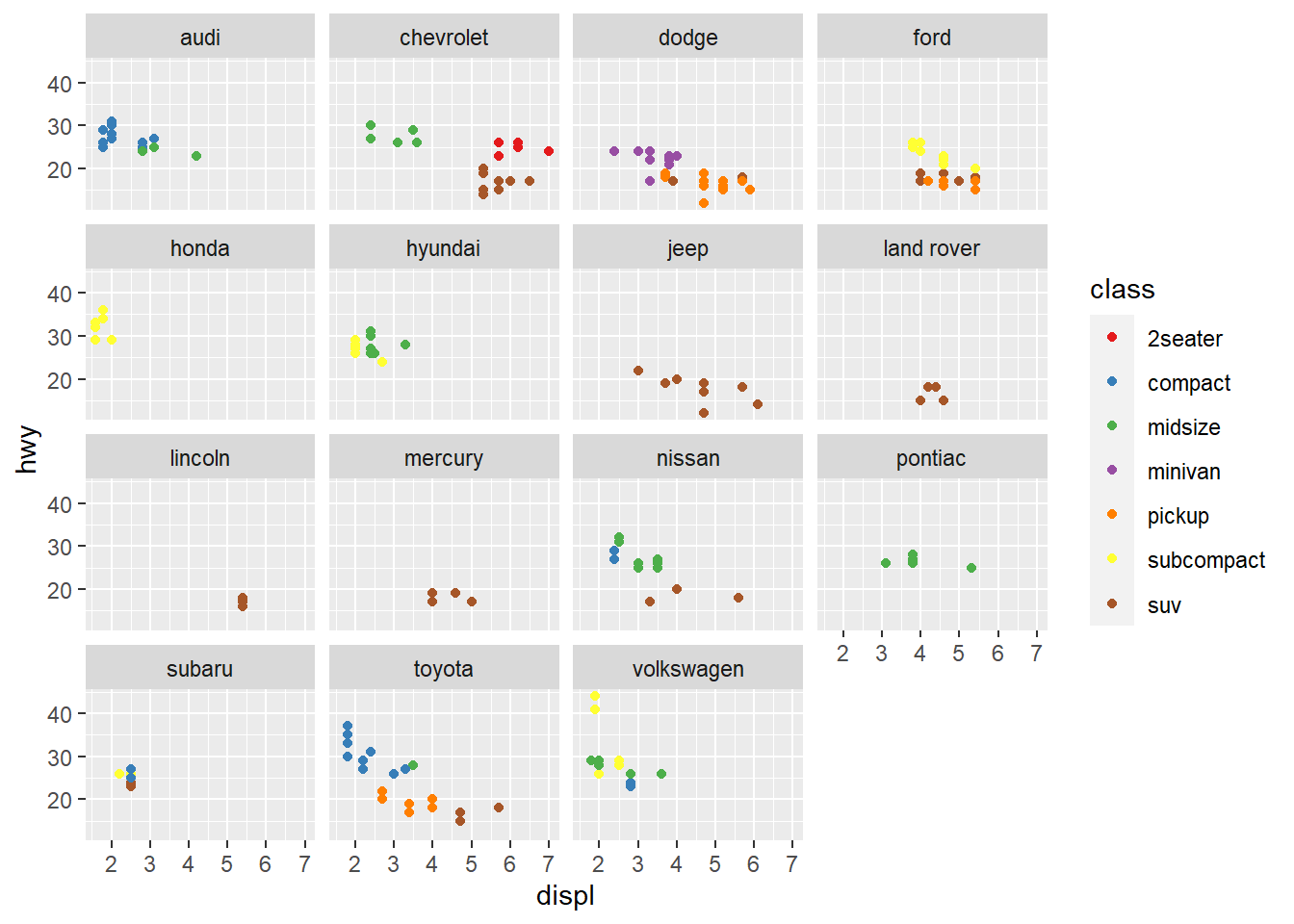
Agora, muito satisfeitos com o resultado do nosso trabalho, resolvemos incluir o gráfico numa publicação, mas do jeito que está, não dá. Então adicionamos mais algumas camadas para torná-lo apresentável.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = class)) +
geom_point() +
scale_color_brewer(palette = "Set1") +
facet_wrap(~manufacturer) +
# Colocamos os nomes nos eixos
labs(title = "Relação entre peso e economia de combustível de automóveis",
subtitle = "Separado por categoria e fabricante",
x = "Peso do veículo em toneladas",
y = "Consumo em milhas por galão de 3,5l",
color = "Categoria",
caption = "Fonte: Agência de Proteção Ambiental Estadunidense.") +
# Escolhemos um tema bonito
theme_light() +
# Mudamos a posição da legenda, pra ficar mais jeitozinho
theme(legend.position = "bottom")
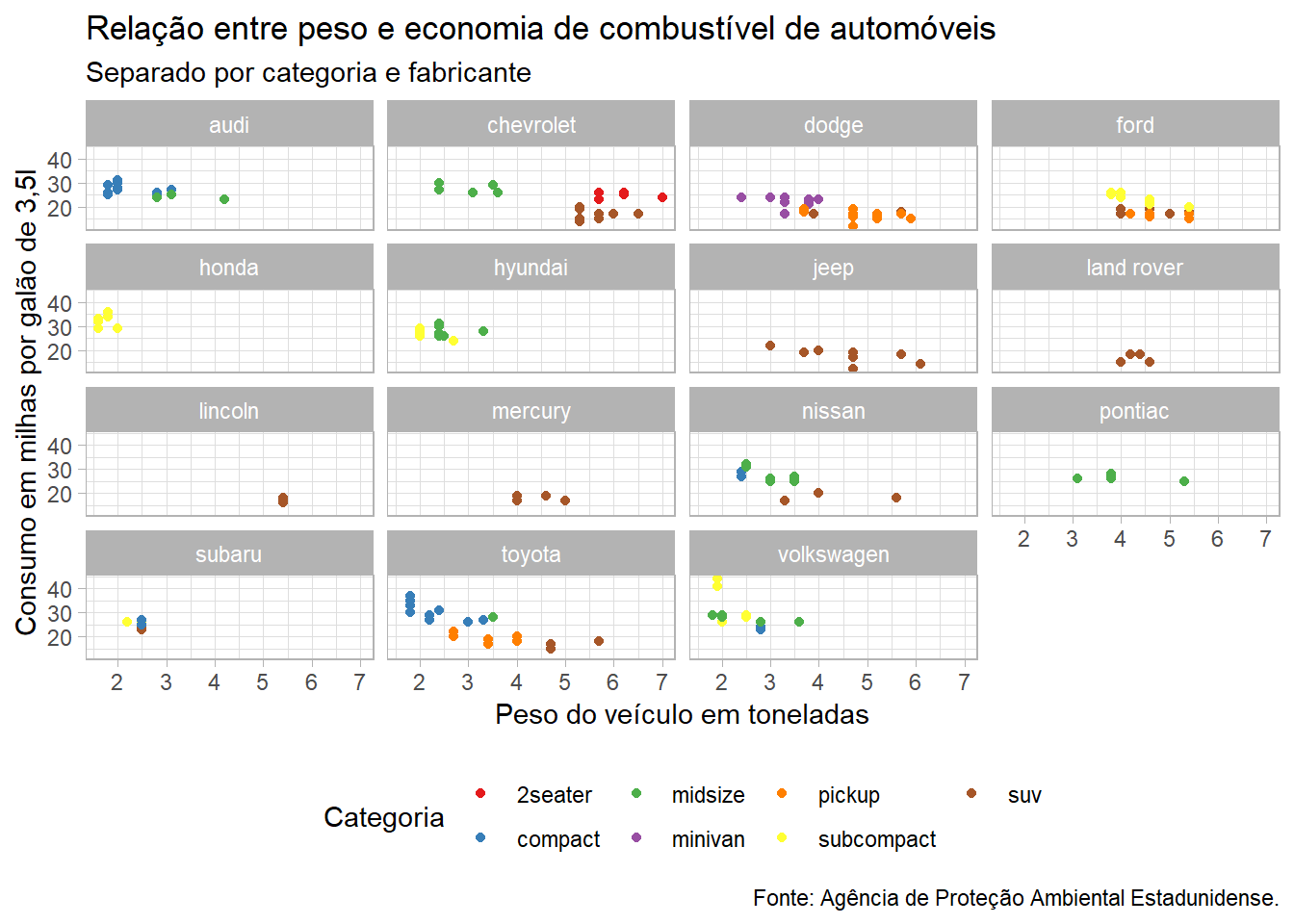
Pronto. Mamãe vai ficar orgulhosa.
Brincadeiras a parte, entendendo um pouco melhor a gramática do gráfico, podemos construir nossas visualizações passo a passo, até chegar no resultado desejado.
Lineplots
O segundo exemplo que quero mostrar pra vocês é a construção de gráficos com linhas. Eles são interessantes porque dão bastante dor de cabeça pra quem está começando. Vamos continuar brincando com o mpg.
Agora que eu fiz meu diagrama de dispersão, estou interessado em começar um processo de modelagem, mas primeiro quero ter uma noção visual da relação entre as variáveis.
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_smooth()
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
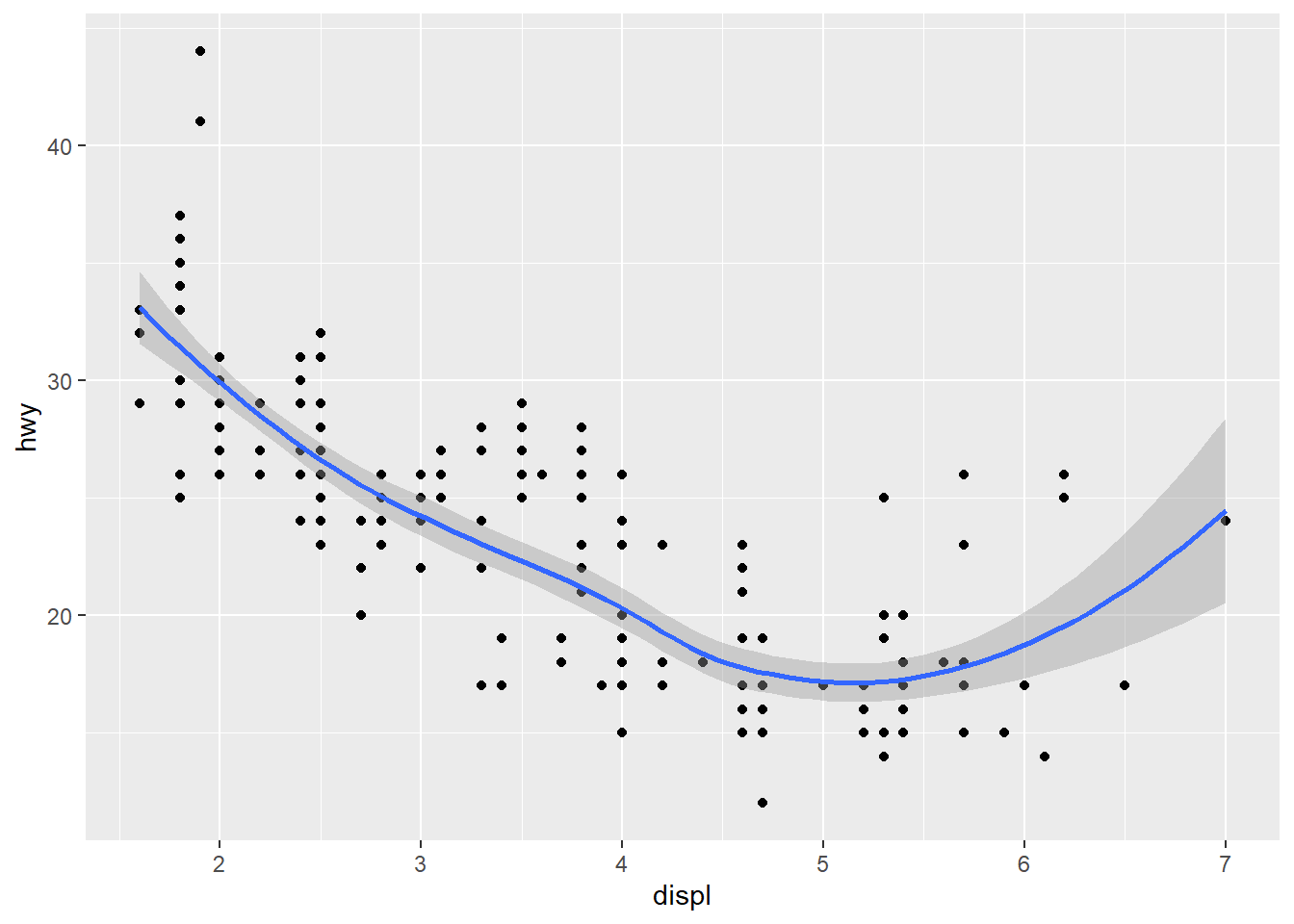
geom_smooth ajusta um modelo aos dados e desenha a linha com os valores preditos. Agora que temos dois objetos geométricos, talvez seja interessante ver o que acontece se eu colocar as cores das classes.
ggplot(mpg, aes(displ, hwy, color = class)) +
geom_point() +
geom_smooth(se = FALSE)
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
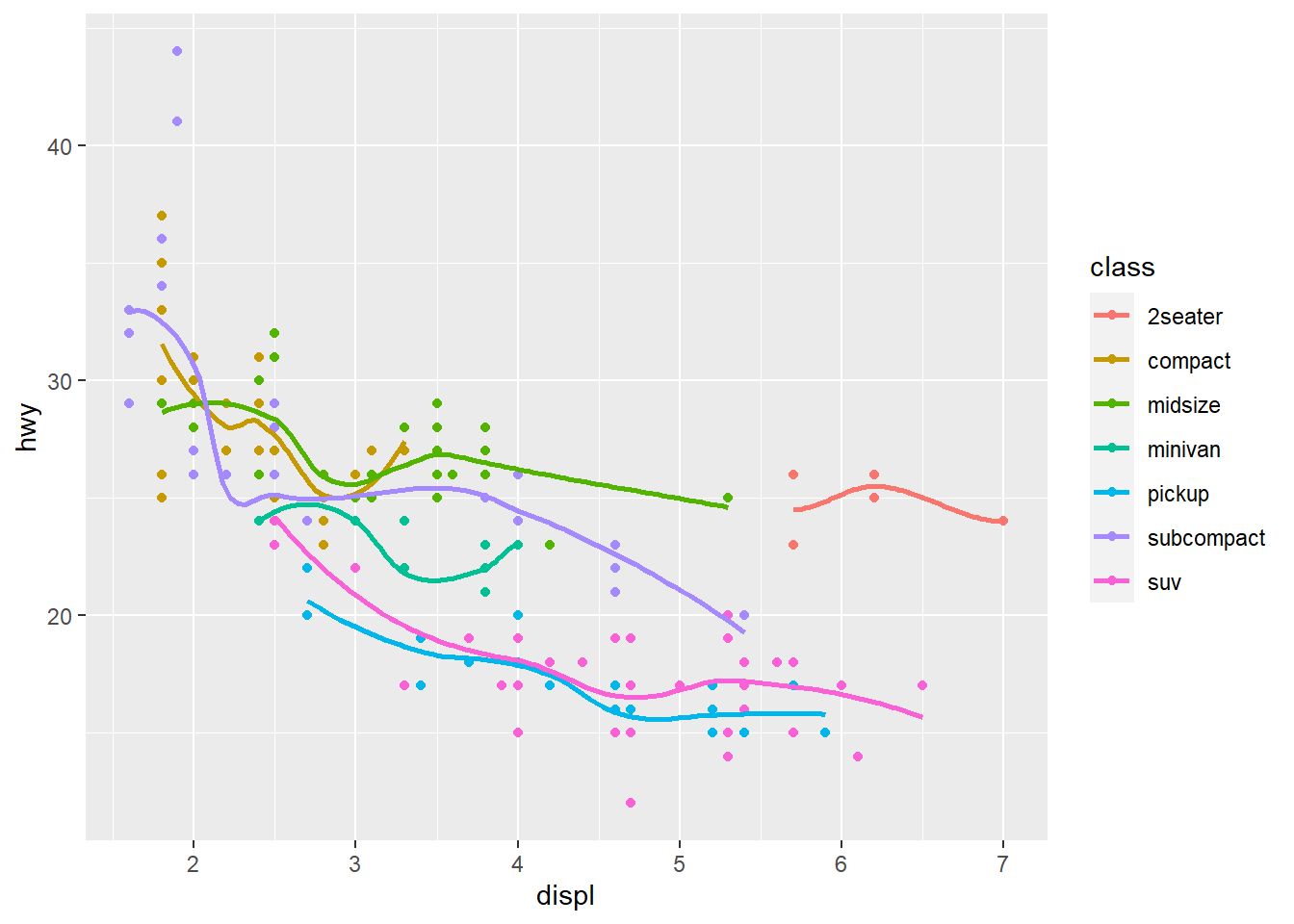
Veja que ele fez o possível para aplicar as escalas nos dois objetos geométricos. Eu pedi para geom_smooth tirar os intervalos de confiança para melhorar a visibilidade. Mas e seu eu quisesse ver a cor dos pontos, mas manter a linha de tendência geral? Você pode especificar mapeamentos estéticos gerais (na primeira camada) ou mapeamentos estéticos locais (dentro de cada camada geométrica).
ggplot(mpg, aes(displ, hwy)) + # mapeamentos gerais, se aplicam a todos os objetos
geom_point(aes(color = class)) + # mapeamento local, só se aplica aqui
geom_smooth(se = FALSE)
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
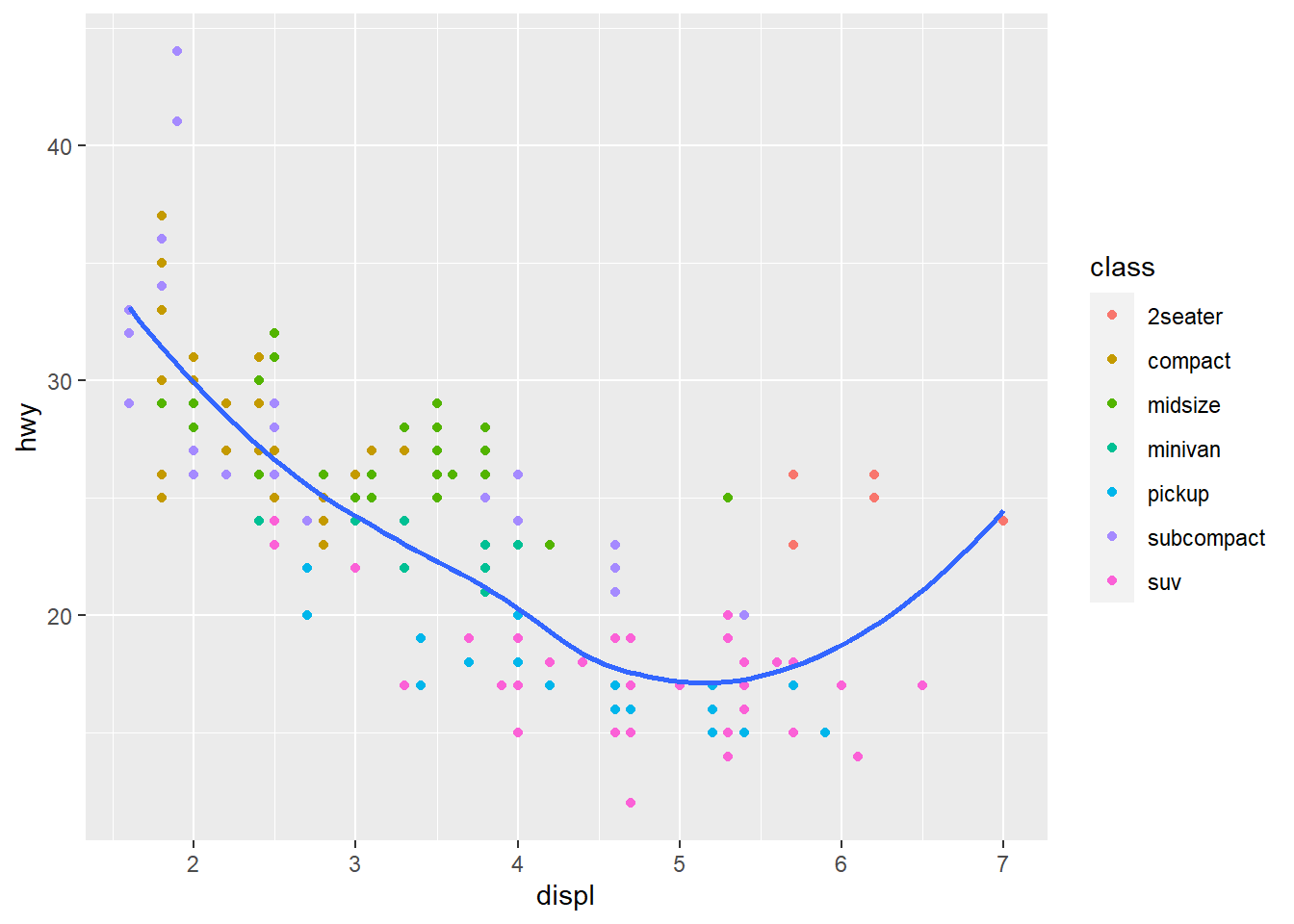
Ok, mas e se eu quisesse um modelo linear ao invés de um “Smoother de Loess”?
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(method = lm)
## `geom_smooth()` using formula 'y ~ x'
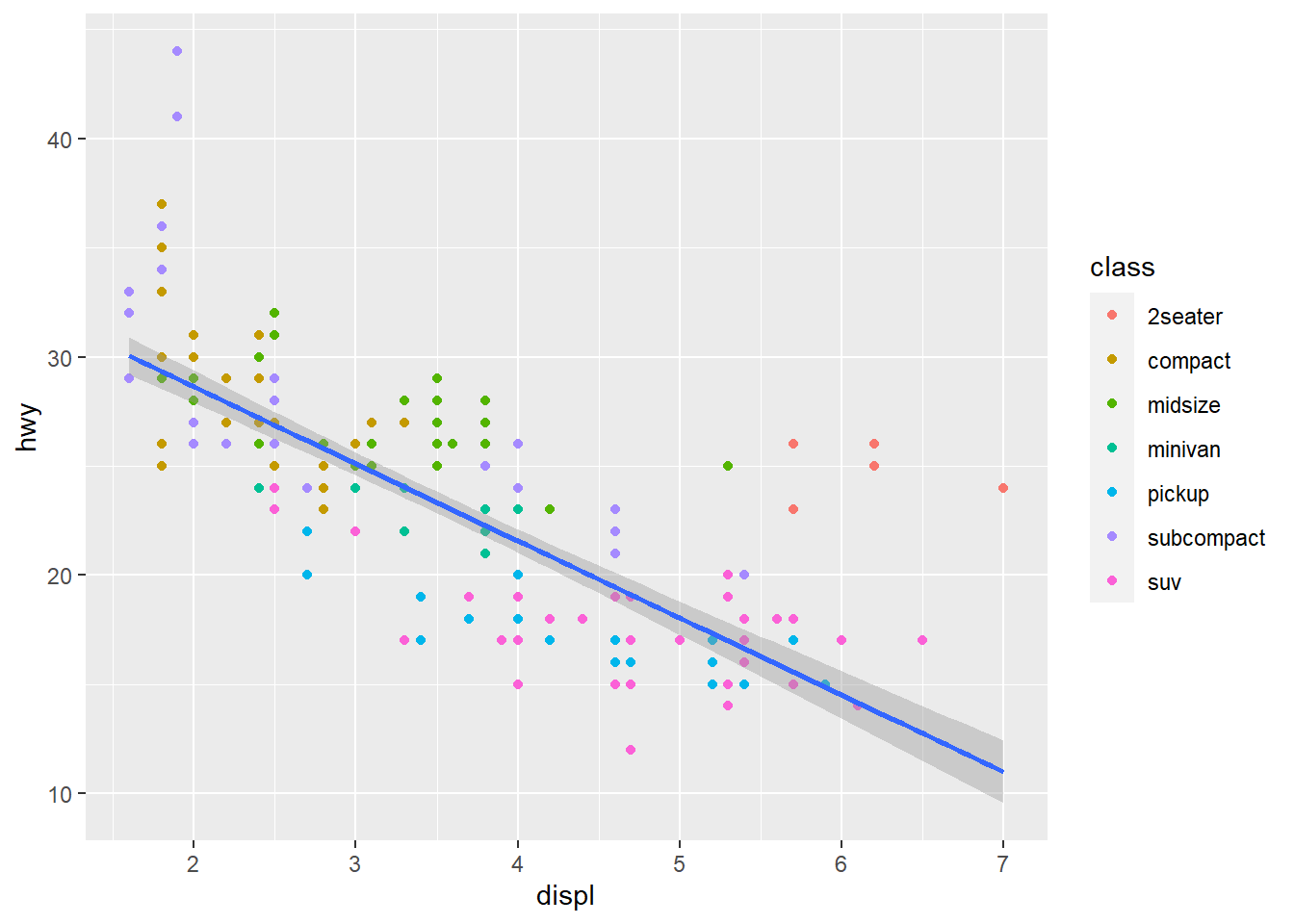
Não vou entrar muito nos argumentos de cada objeto geométrico e função, vocês podem aprender isso na prática olhando a documentação das funções que são do interesse de vocês. ?geom_smooth para ver todas as possibilidades. Uma dica boa é usar geom_smooth para verificar interações entre variáveis numéricas e fatores.
ggplot(mpg, aes(displ, hwy, color = factor(cyl))) +
geom_point() +
geom_smooth(method = lm)
## `geom_smooth()` using formula 'y ~ x'
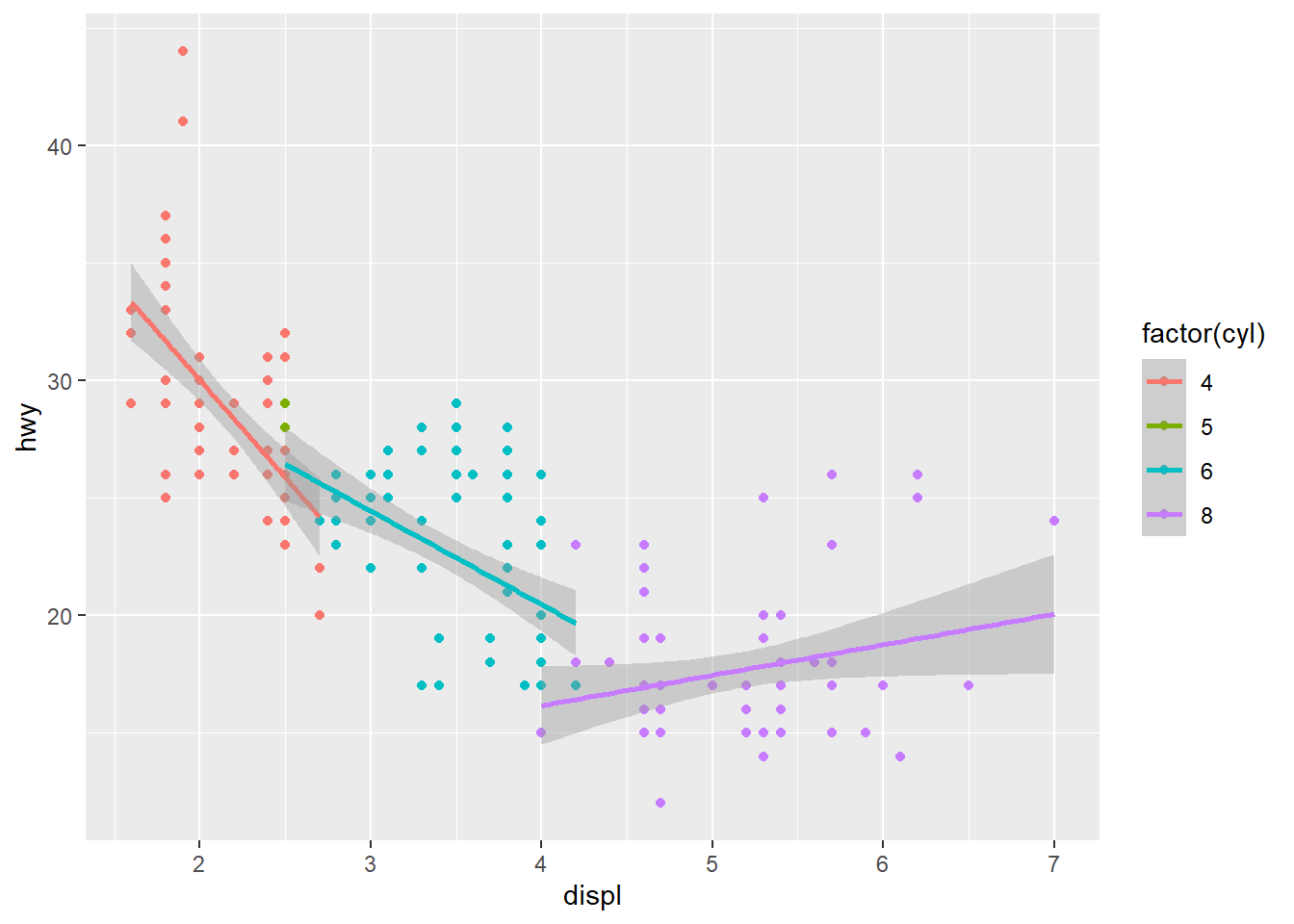
Ok, mas e se temos um gráfico de linhas mais tradicional, tipo uma série histórica?
economics
## # A tibble: 574 x 6
## date pce pop psavert uempmed unemploy
## <date> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1967-07-01 507. 198712 12.6 4.5 2944
## 2 1967-08-01 510. 198911 12.6 4.7 2945
## 3 1967-09-01 516. 199113 11.9 4.6 2958
## 4 1967-10-01 512. 199311 12.9 4.9 3143
## 5 1967-11-01 517. 199498 12.8 4.7 3066
## 6 1967-12-01 525. 199657 11.8 4.8 3018
## 7 1968-01-01 531. 199808 11.7 5.1 2878
## 8 1968-02-01 534. 199920 12.3 4.5 3001
## 9 1968-03-01 544. 200056 11.7 4.1 2877
## 10 1968-04-01 544 200208 12.3 4.6 2709
## # ... with 564 more rows
Podemos criar um gráfico de linhas tendo como base a data (date) e alguma das variáveis registradas, como a taxa de desemprego.
ggplot(economics, aes(x = date, y = uempmed)) +
geom_line()
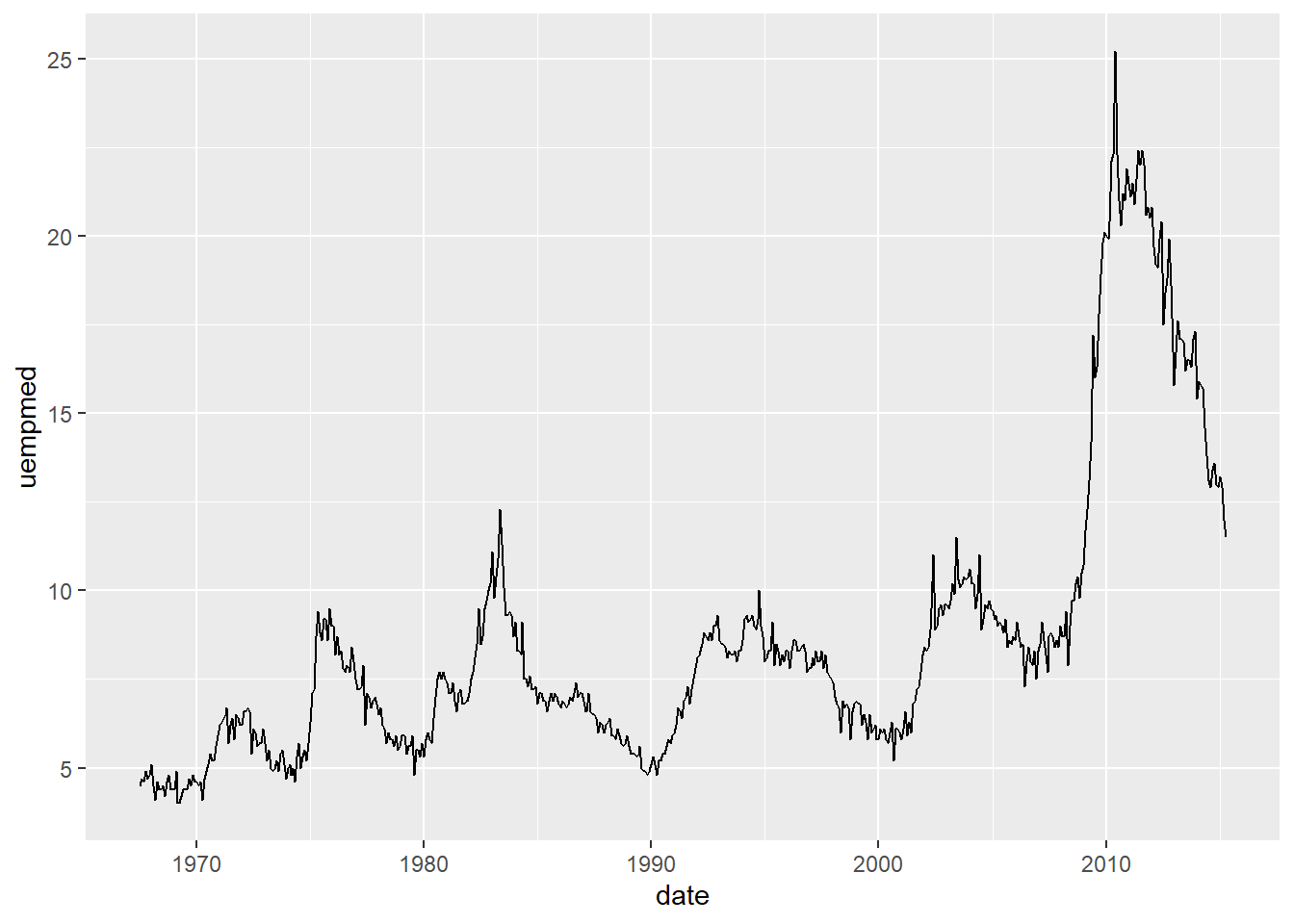
Ou o consumo em bilhões de dólares
ggplot(economics, aes(x = date, y = pce)) +
geom_line()
Ou a população
ggplot(economics, aes(x = date, y = pop)) +
geom_line()
Ok, mas eu quero comparar visualmente o que ocorre com uma variável quando a outra muda. Podemos recorrer ao que aprendemos sobre mapeamentos estéticos globais e locais.
ggplot(economics, aes(x = date)) +
geom_line(aes(y = uempmed)) +
geom_line(aes(y = pce)) +
geom_line(aes(y = pop))
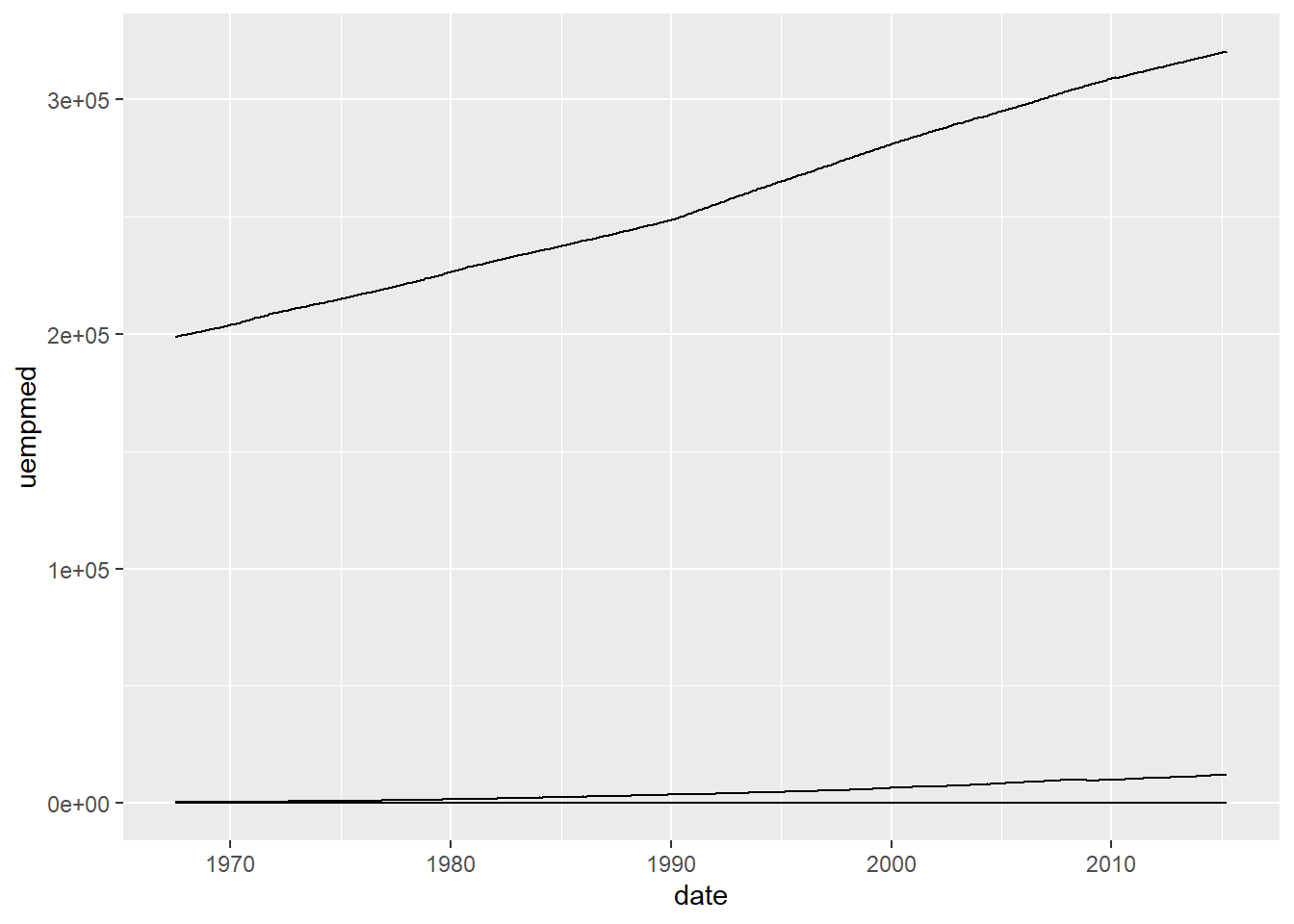
Ficou meio ruim, porque as variável tem grandezas distintas. Podemos tentar resolver esse problema aplicando transformações na variável idade, mas meio que pra qualquer lugar onde caminhos, batemos numa parede ou noutra. Esse tipo de solução é muito frequente entre pessoas que vem do base pro ggplot2, porque no base estamos acostumado a ideia de adicionar mais objetos geométricos ao nosso gráfico original adicionando invocações à funções como lines ou text. Porém, a solução preferida no tidyverse é aplicar uma transformação no banco original de tal forma que as nossas variáveis numéricas caiam todas num par que especifica o nome da variável | e o valor dela.
library(tidyr)
economics %>%
pivot_longer(cols = -date,
names_to = "variavel",
values_to = "valor")
## # A tibble: 2,870 x 3
## date variavel valor
## <date> <chr> <dbl>
## 1 1967-07-01 pce 507.
## 2 1967-07-01 pop 198712
## 3 1967-07-01 psavert 12.6
## 4 1967-07-01 uempmed 4.5
## 5 1967-07-01 unemploy 2944
## 6 1967-08-01 pce 510.
## 7 1967-08-01 pop 198911
## 8 1967-08-01 psavert 12.6
## 9 1967-08-01 uempmed 4.7
## 10 1967-08-01 unemploy 2945
## # ... with 2,860 more rows
Talvez não fique imediatamente claro para todos porque eu optei por esta solução, mas talvez essa próxima figura fale mais que mil palavras.
economics %>%
pivot_longer(cols = -date,
names_to = "variavel",
values_to = "valor") %>%
ggplot(aes(date, valor)) +
geom_line() +
facet_wrap(~variavel, scales = "free_y", ncol = 1)
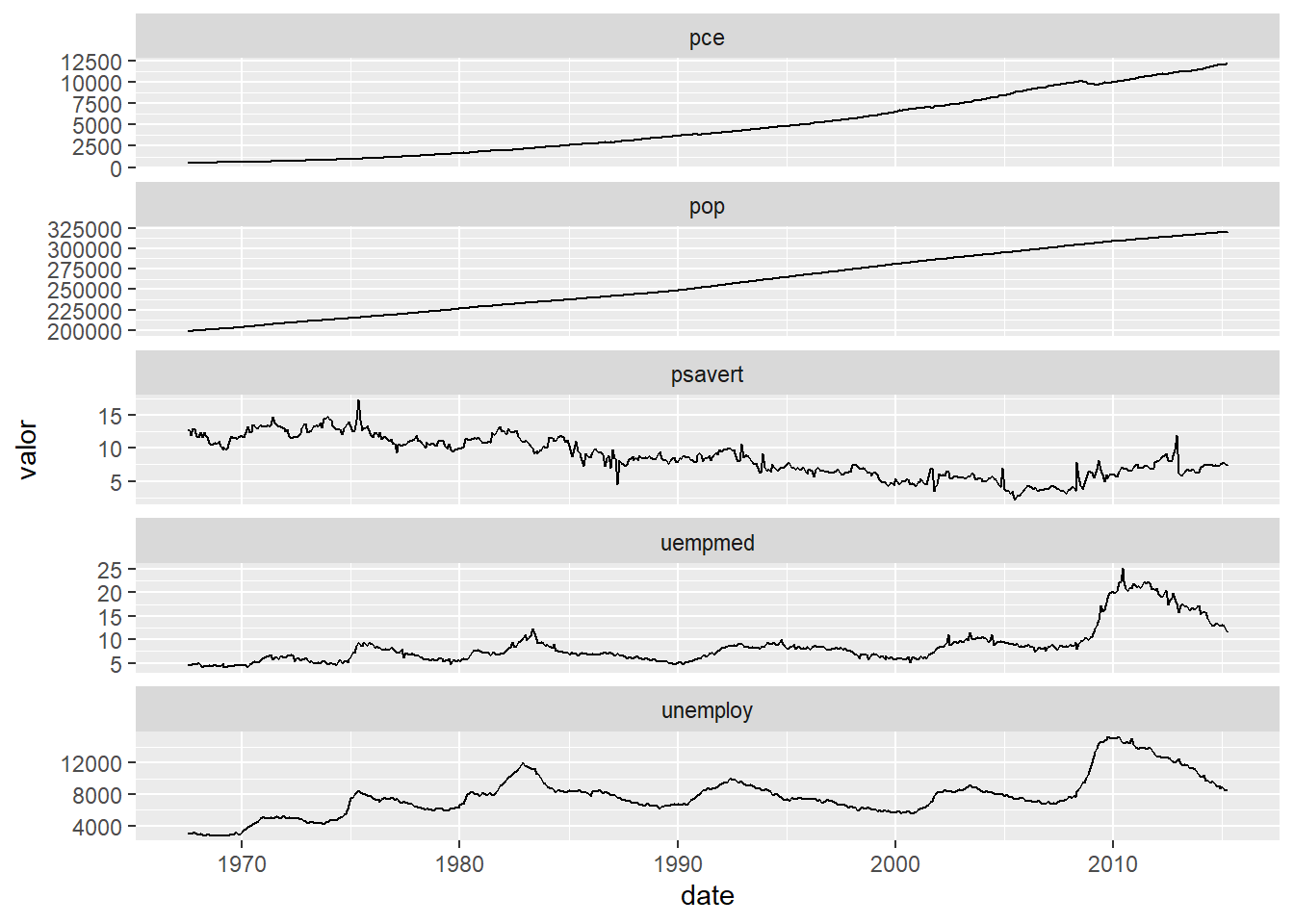
A ênfase em usar tidy data no tidyverse decorre do fato de que todos os pacotes são programados para usar a forma de organização do banco como uma alavanca para facilitar a análise de dados. Vejam esta outra pipeline.
# Como vamos fazer algumas transformações nos dados, vamos carregar o dplyr aqui
library(dplyr)
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
economics %>%
pivot_longer(cols = -date,
names_to = "variavel",
values_to = "valor") %>%
filter(variavel %in% c("psavert", "uempmed")) %>%
ggplot(aes(date, valor, color = variavel, shape = variavel)) +
geom_line()
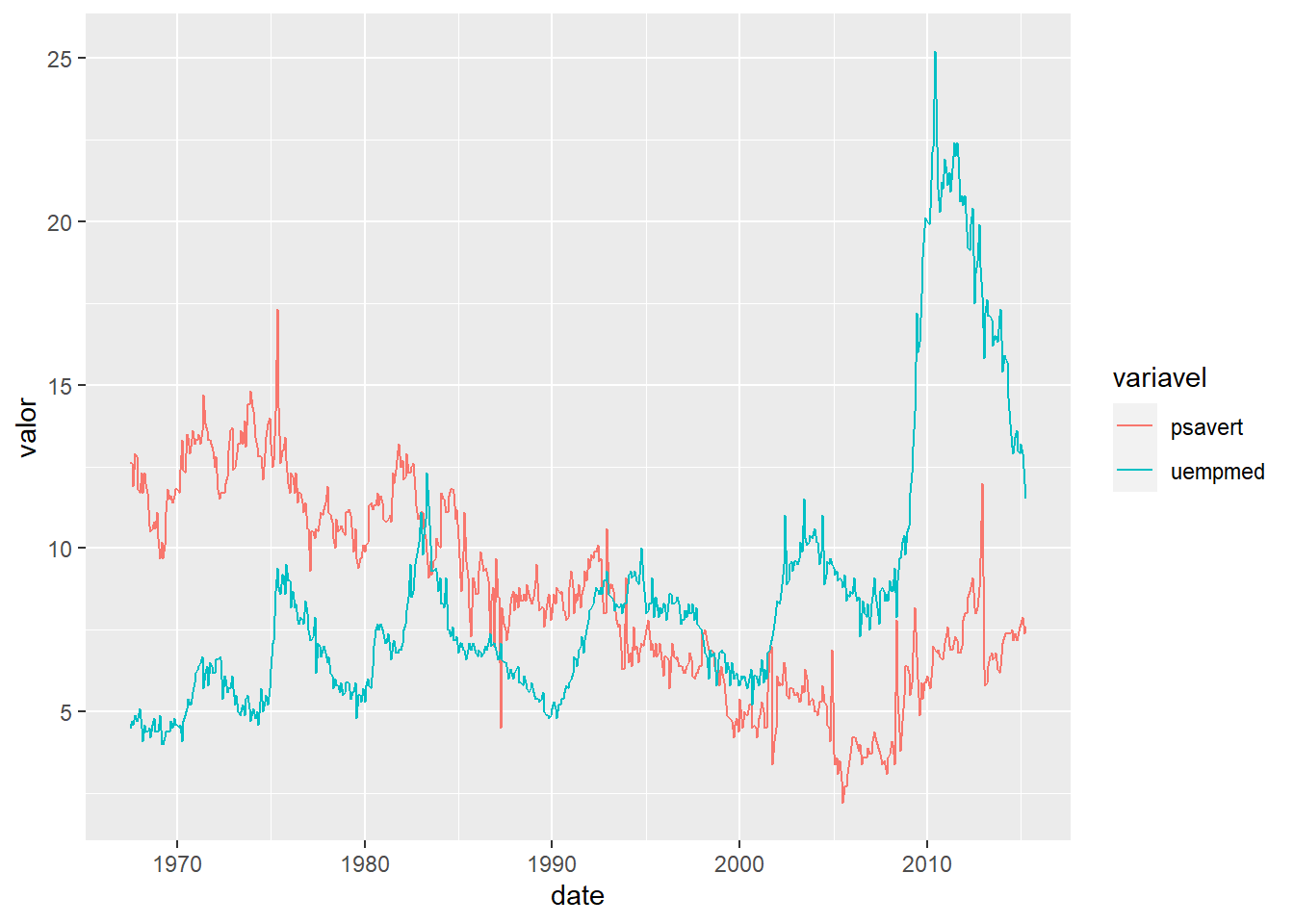
E agora vejam um dos erros mais comuns de quem está começando:
economics %>%
pivot_longer(cols = -date,
names_to = "variavel",
values_to = "valor") %>%
filter(variavel %in% c("psavert", "uempmed")) %>%
ggplot(aes(date, valor)) +
geom_line()
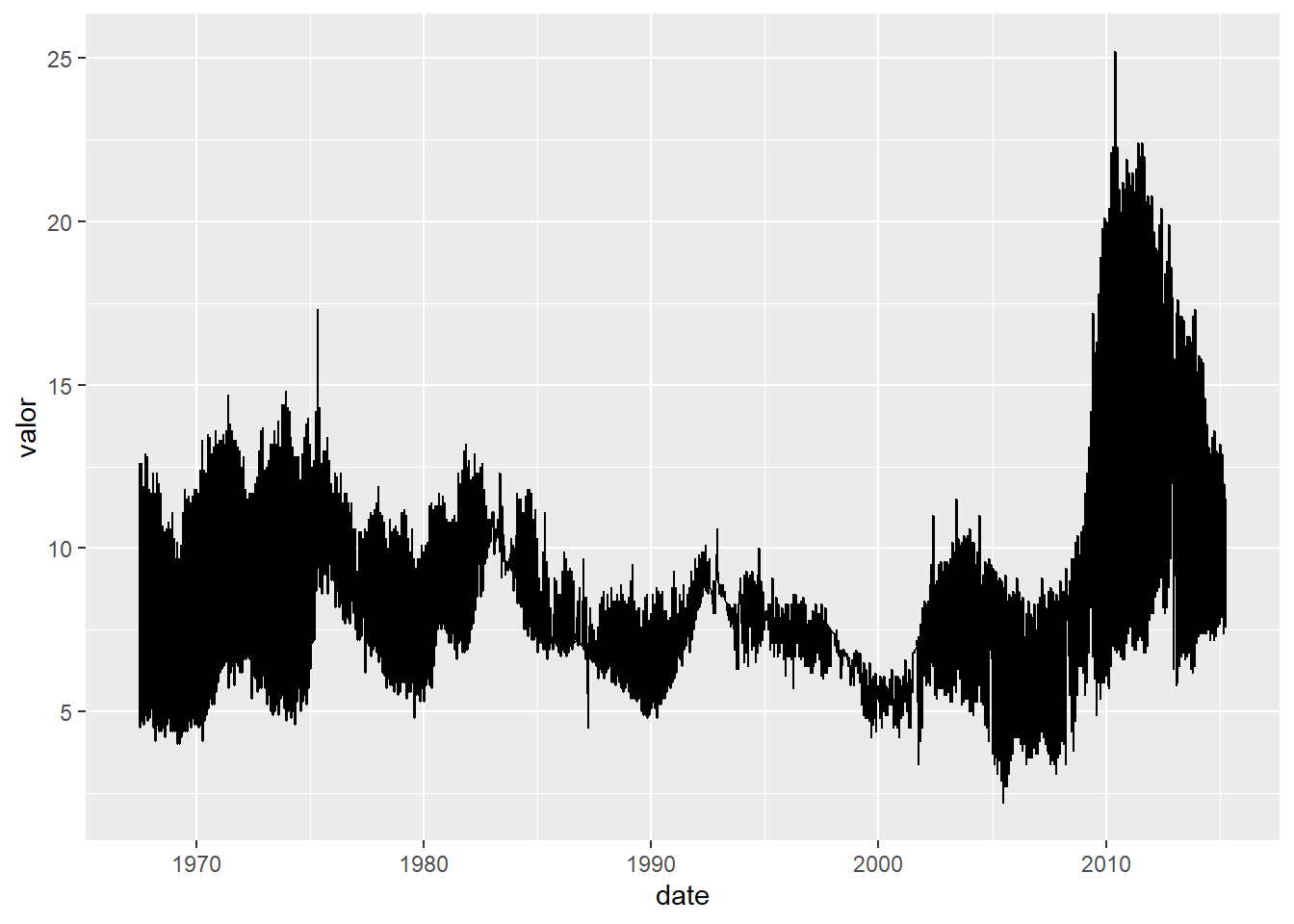
Ao não especificar uma separação entre grupos, o ggplot2 não interpreta meus dados! Ele simplesmente conecta as observações mais ou menos na ordem em que elas aparecem no eixo x. Para resolver esse problema, precisamos especificar grupos! Seja indiretamente, através de uma escala de cores, formas ou tipos de linha, seja diretamente através da estética groups.
economics %>%
pivot_longer(cols = -date,
names_to = "variavel",
values_to = "valor") %>%
filter(variavel %in% c("psavert", "uempmed")) %>%
ggplot(aes(date, valor, group = variavel)) +
geom_line()

economics %>%
pivot_longer(cols = -date,
names_to = "variavel",
values_to = "valor") %>%
filter(variavel %in% c("psavert", "uempmed")) %>%
ggplot(aes(date, valor, color = variavel, linetype = variavel)) +
geom_line()
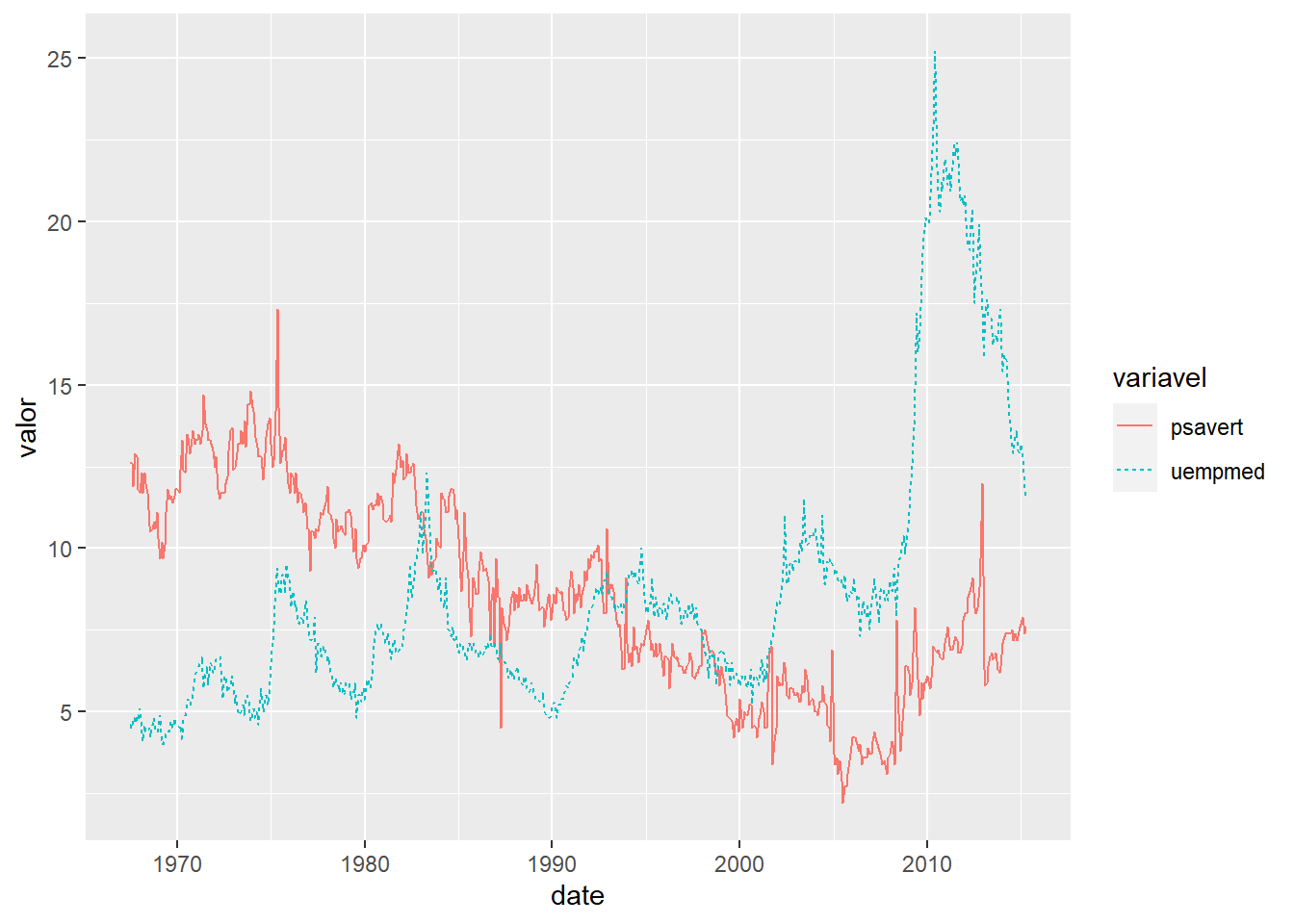
Legal né?
Barcharts
Para terminar e ilustrar alguns exemplos de transformação estatística, vamos fazer alguns gráficos de barras usando o diamonds, um banco de dados para fazer a alegria das piores pessoas na história da humanidade.
diamonds
## # A tibble: 53,940 x 10
## carat cut color clarity depth table price x y z
## <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
## 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
## 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
## 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
## 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
## 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
## 7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47
## 8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53
## 9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49
## 10 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39
## # ... with 53,930 more rows
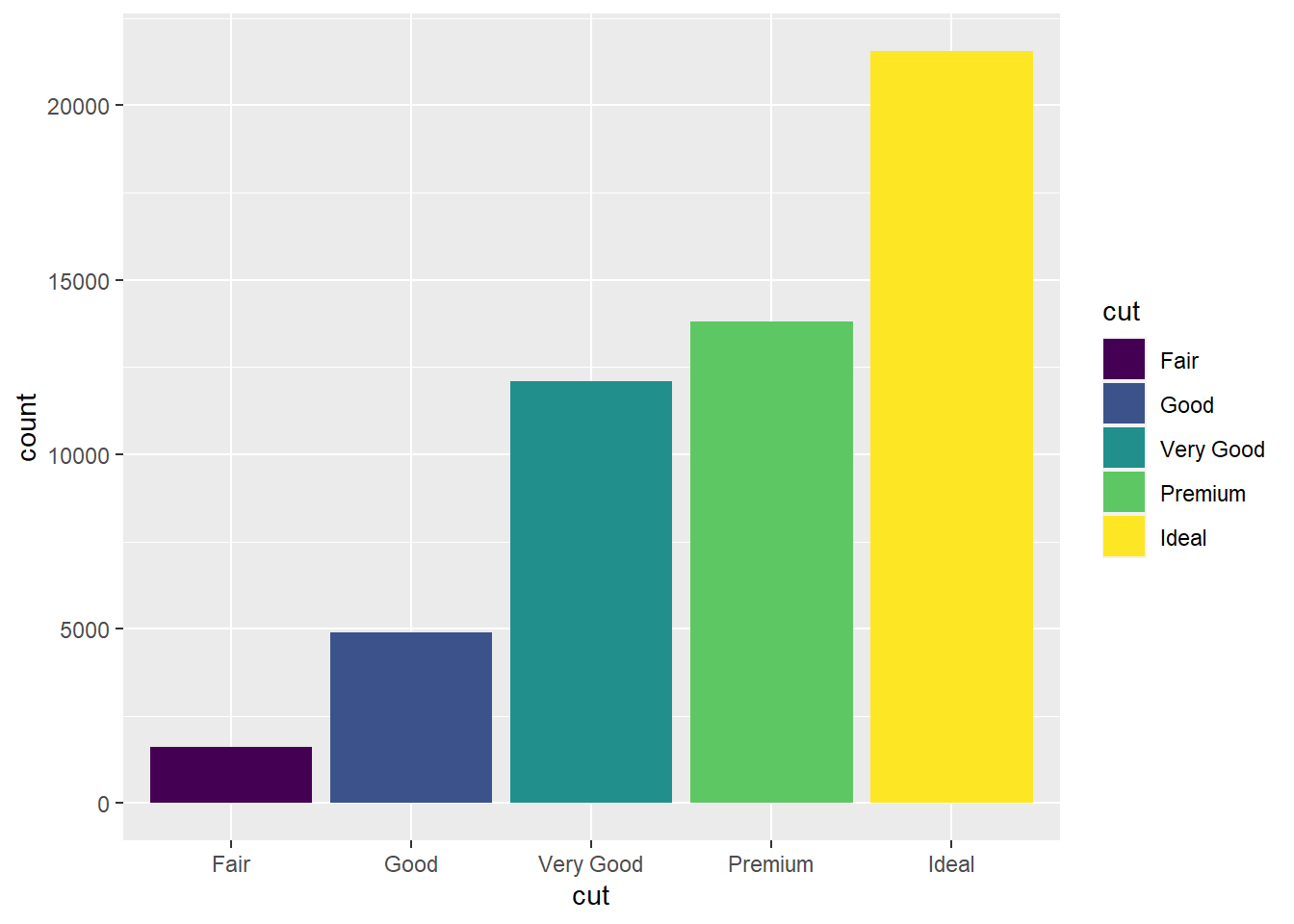
Que tal um gráfico básico, do número de diamantes de acordo com a qualidade de seu corte (cut). Olhando a ajuda do ?geom_bar você vai na certeza de que você entendeu a aula e escreve o seguinte código:
ggplot(diamonds, aes(x = cut, color = cut)) +
geom_bar()
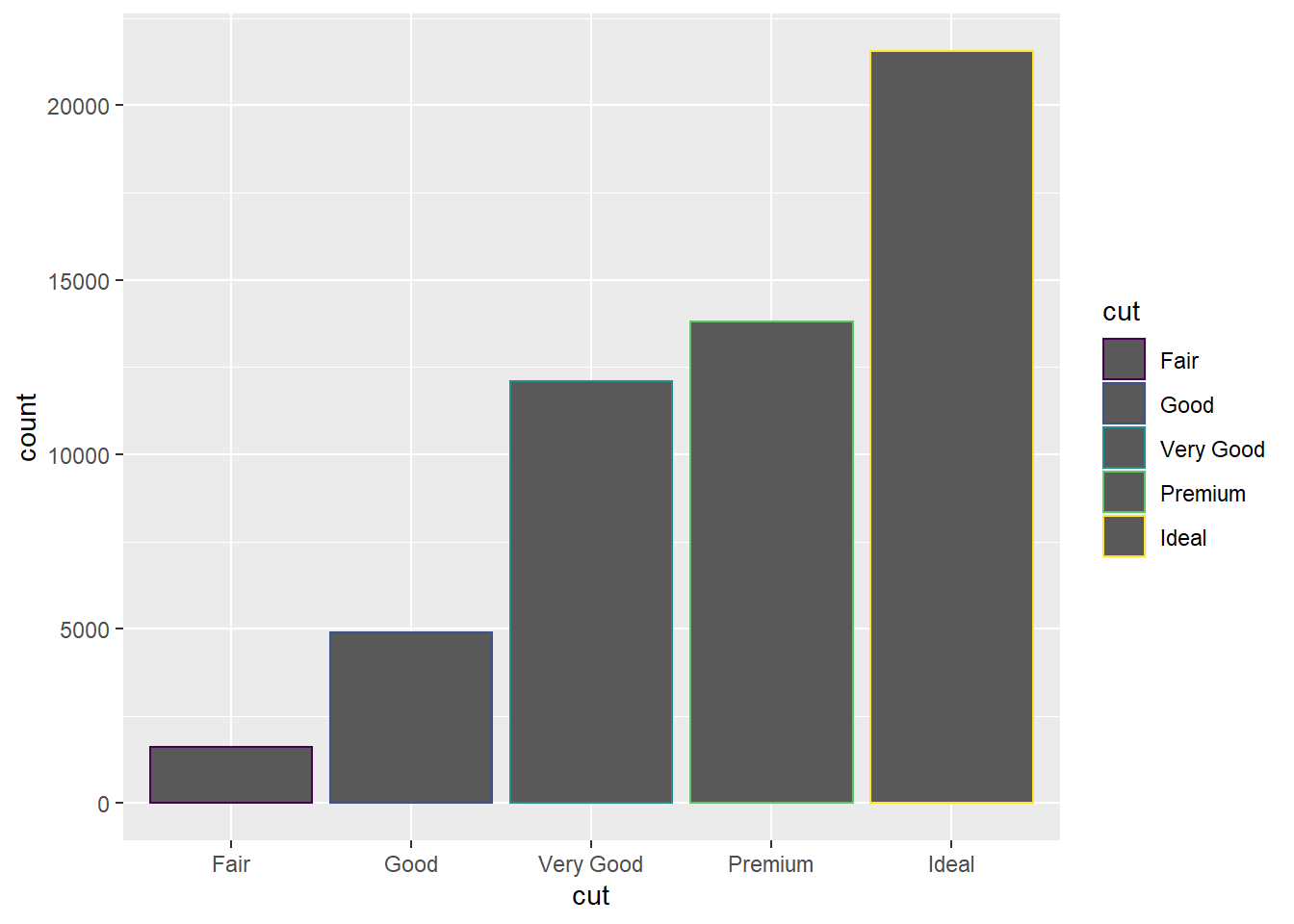
E agora, você fica olhando pro seu computador com cara de tacho. O que aconteceu? Bom, no caso de geoms com duas dimensões, podem existir casos em que você quer dar mapeamentos estéticos distintos para as bordas e para o conteúdo deles. Por isso, existem as estéticas color e fill. Você pode pensar nelas como a casca do pão e o recheio.
ggplot(diamonds, aes(x = cut, fill = cut)) +
geom_bar()
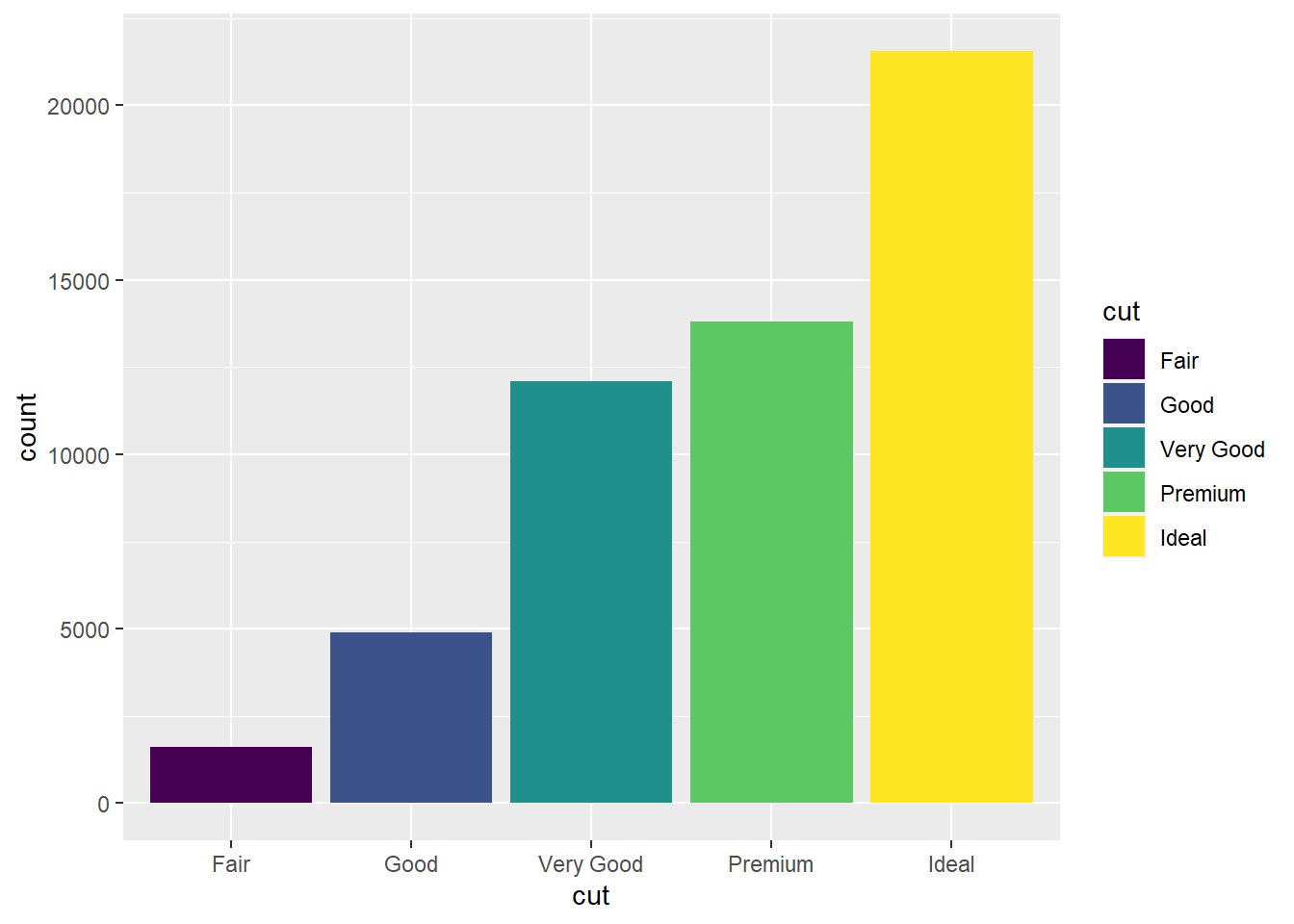
Mas, você ainda não está satisfeito. Pela sua ampla experiência com uma das indústrias mais sangrentas e retrógadas do planeta você entende que a qualidade do corte não é o suficiente para determinar o valor de um diamante, então você quer ver a distribuição também pelo nível de transparência do diamante, codificado na variável clarity.
ggplot(diamonds, aes(x = cut, fill = clarity)) +
geom_bar()
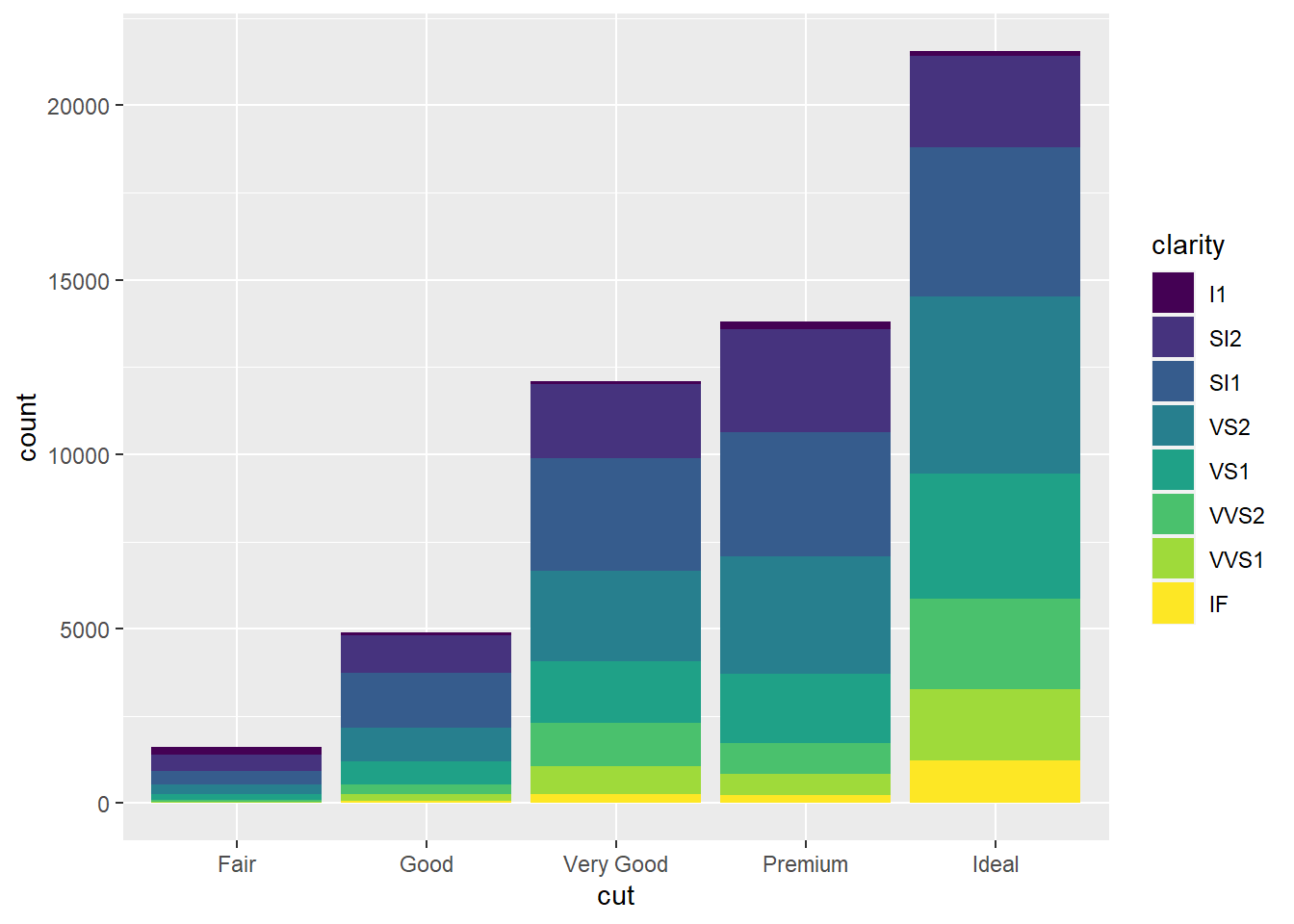
Esse é um primeiro passo interessante, e se tivessemos apenas duas ou três categorias, a gente poderia parar por aí. Mas no geral, para facilitar comparações, queremos poder controlar o posicionamento das barras. Isso é possível ajustando o argumento position dos geoms onde isso é necessário.
# O padrão
ggplot(diamonds, aes(x = cut, fill = clarity)) +
geom_bar(position = "stack")
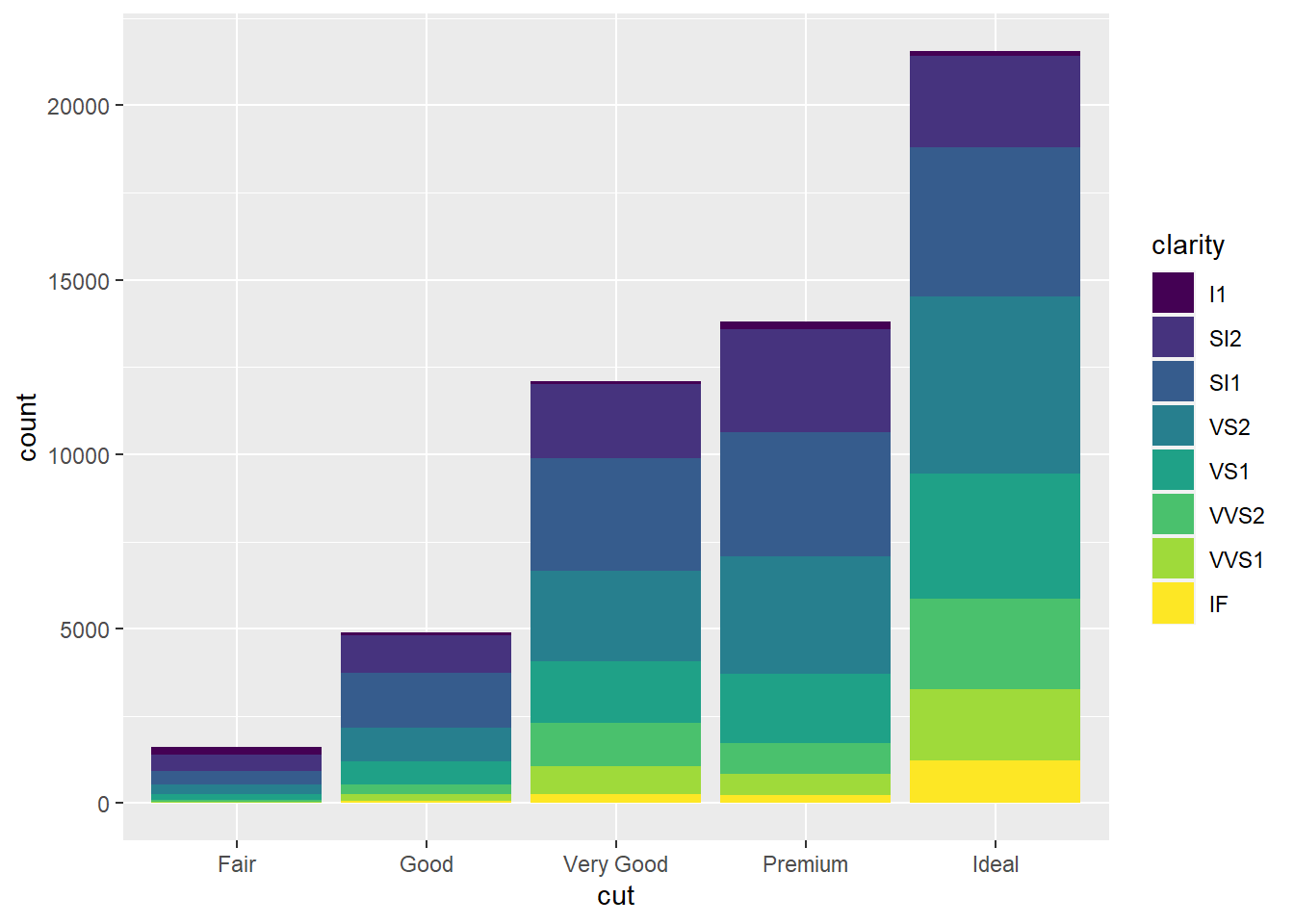
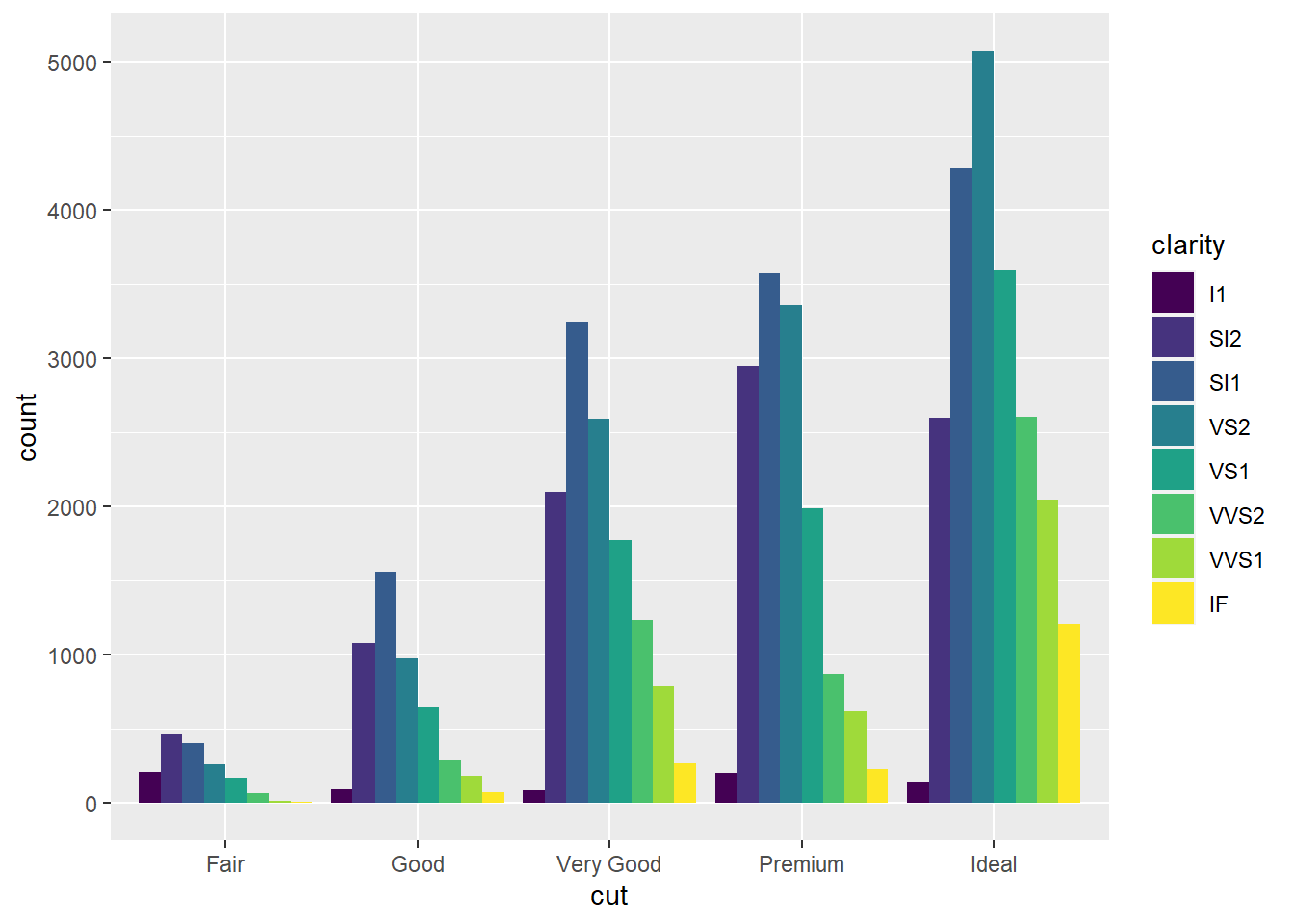
# O certo
ggplot(diamonds, aes(x = cut, fill = clarity)) +
geom_bar(position = "dodge")
# Empilhadas a 100%, para facilitar comparações entre categorias
ggplot(diamonds, aes(x = cut, fill = clarity)) +
geom_bar(position = "fill")
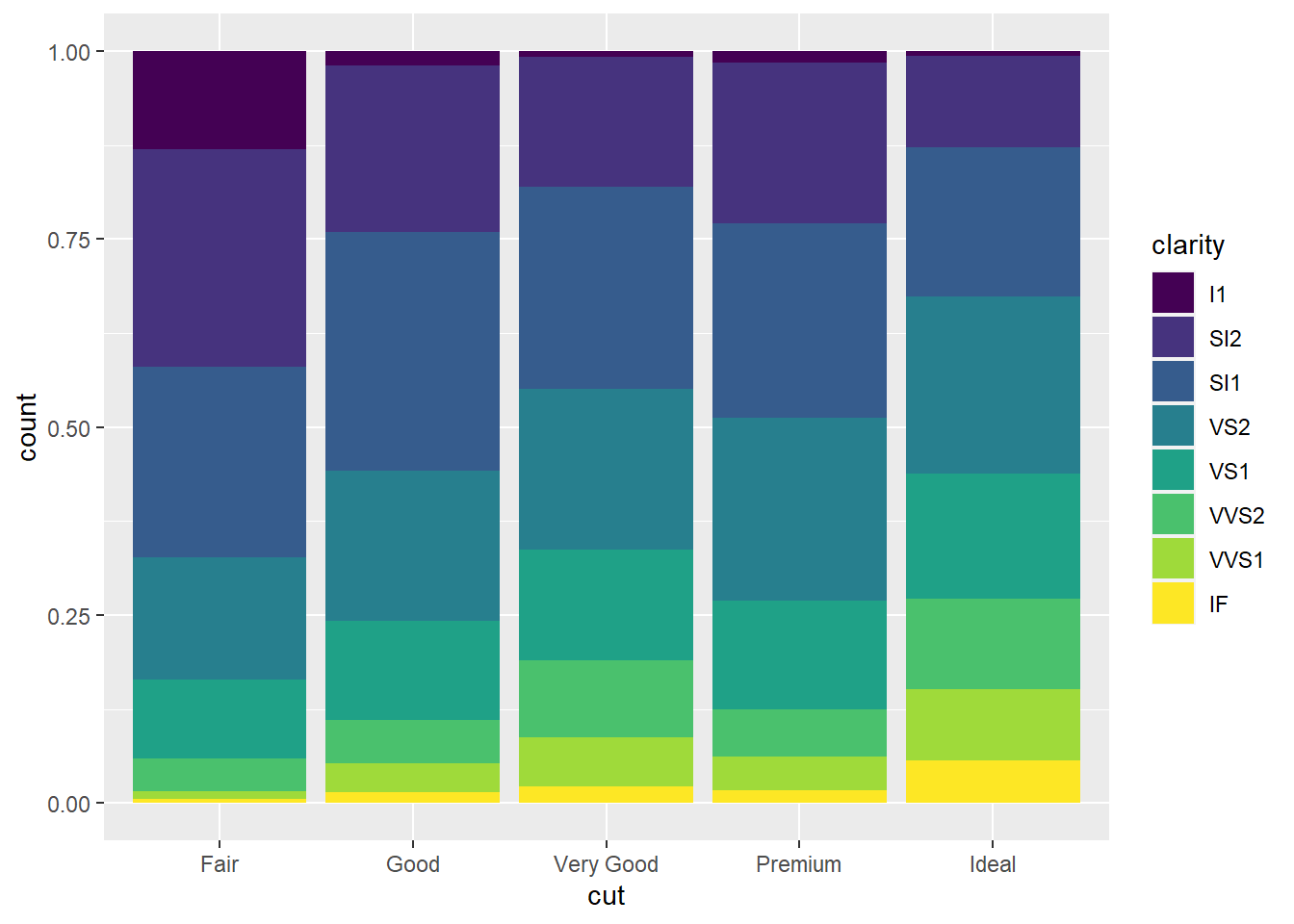
Pode parecer jocoso, mas em 99% dos casos, o correto é você usar barras lado-a-lado, assim você visualmente pode comparar as categorias simplesmente comparando a altura das barras. Da próxima vez que você pensar em construir um gráfico de pizza, desista e faça um gráfico de barras com position = "dodge". Seus leitores vão agradecer.
Esse exemplo também é legal para gente olhar um pouco para a parte de transformações estatísticas nas variáveis:
diamonds2 <- diamonds %>%
count(cut) %>%
mutate(prop = n/sum(n))
diamonds2 %>%
ggplot() +
geom_bar(aes(x = cut, y = prop), stat = "identity")
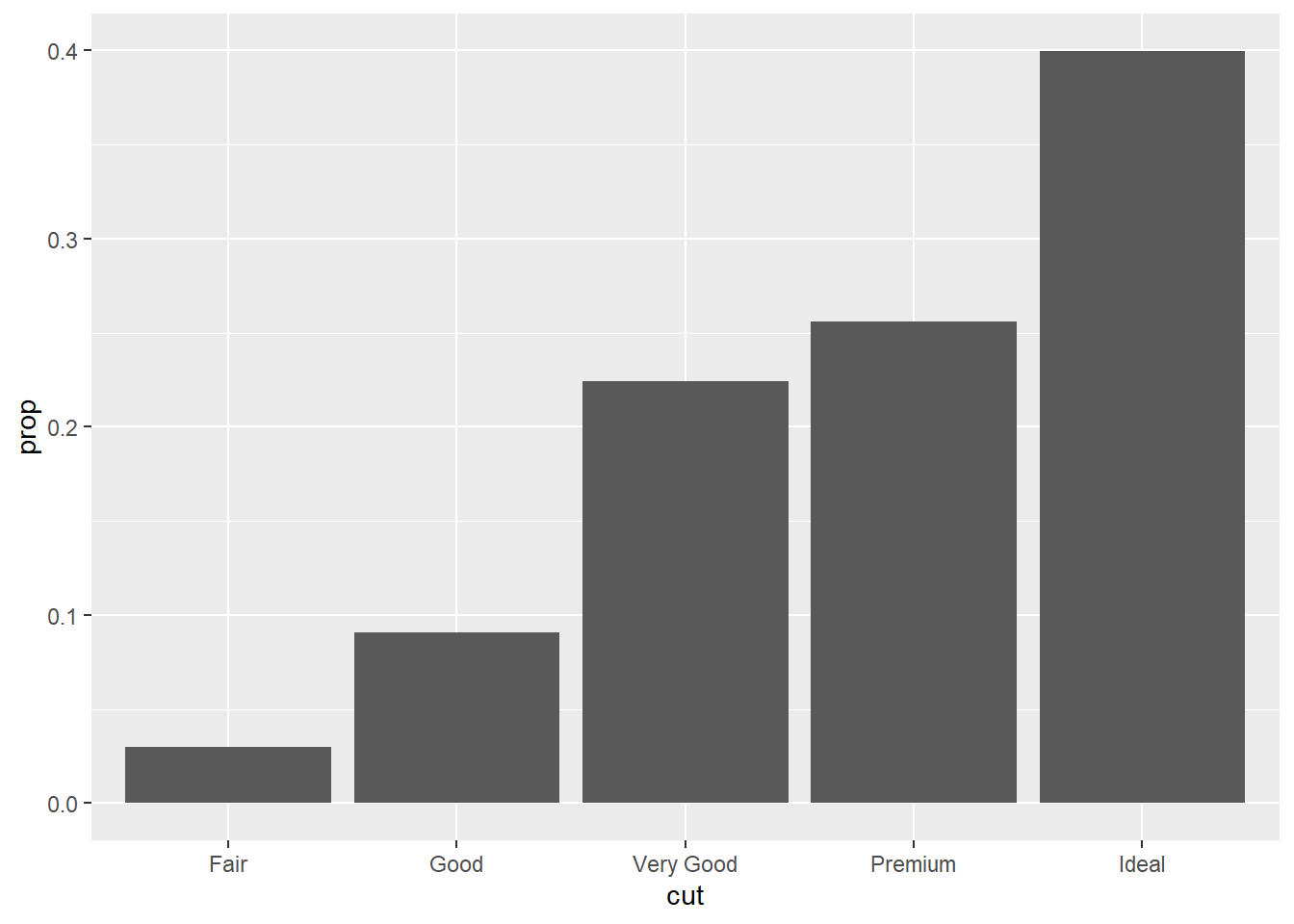
Por padrão, geom_bar já faz o primeiro passo e utiliza as contagens (stat_count) para produzir o gráfico de barras, mas eu posso mudar esse comportamento através do argumento stat. Eu também posso querer mostrar proprções ao invés de contagens de outra forma mais sucinta.
ggplot(diamonds, aes(x = cut,
# ao fazer isso, eu mudo o padrão de contagens para proporções.
y = stat(prop),
# preciso especificar o grupo, se não todas as barras vão a 100%.
group = 1)) +
geom_bar()
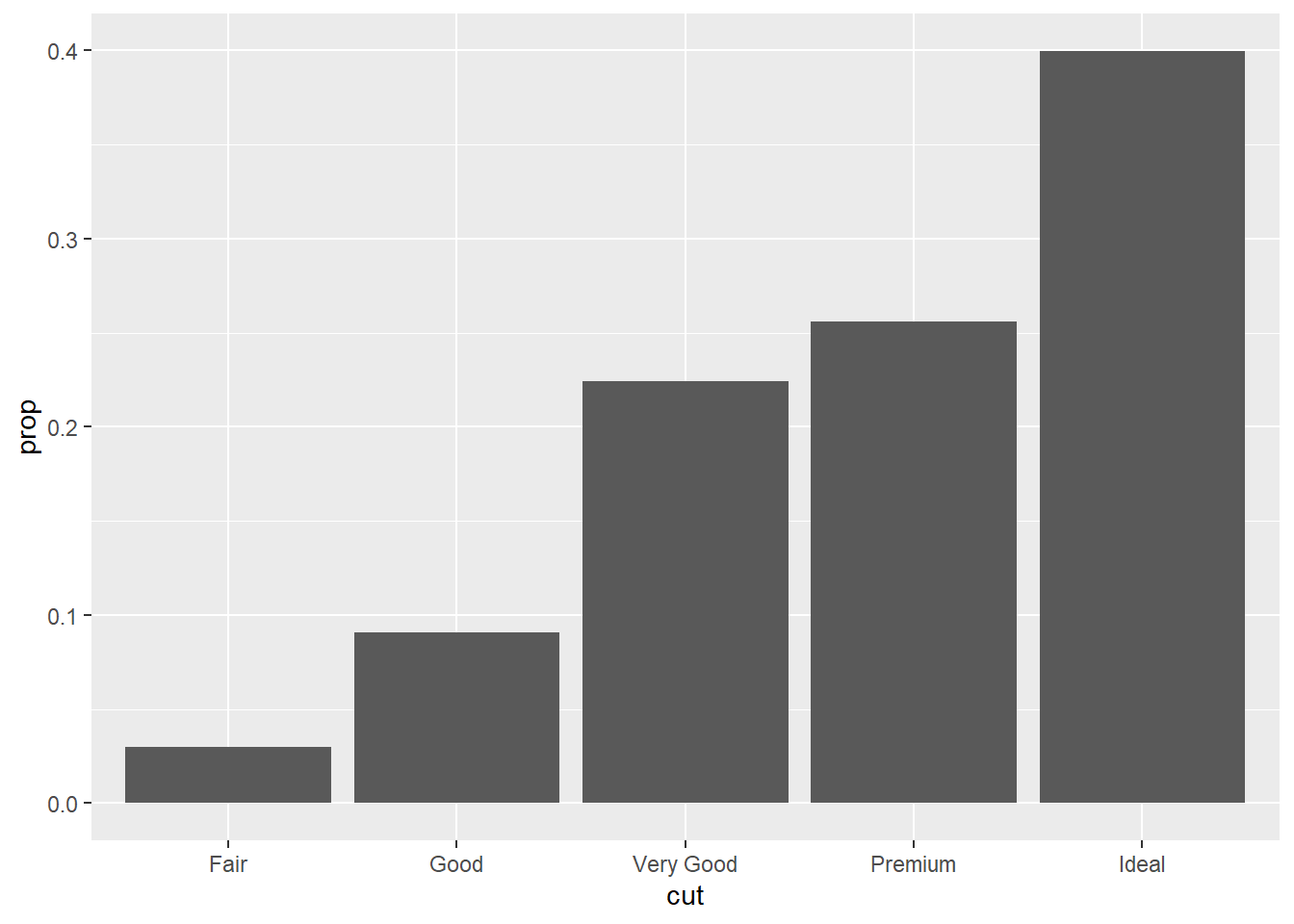
Você pode construir seus gráficos a partir de transformações estatísticas ao invés de objetos geométricos:
ggplot(data = diamonds) +
stat_summary(
mapping = aes(x = cut, y = depth),
fun.min = min,
fun.max = max,
fun = median
)
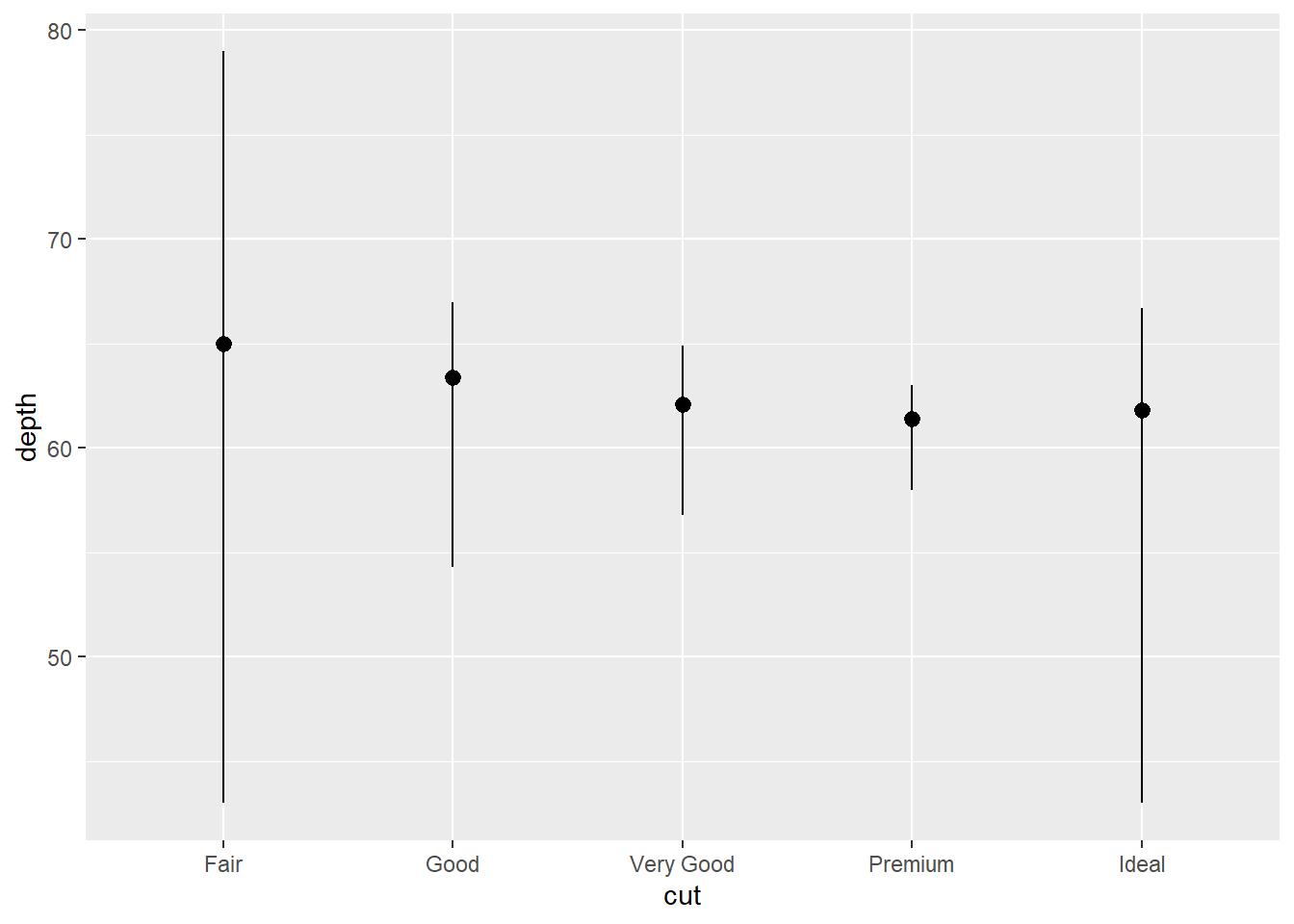
As transformações estatísticas começam sempre com stat_ e cada uma tem um objeto geométrico padrão, que você pode mudar com o argumento geom.
ggplot(data = diamonds) +
stat_summary(
mapping = aes(x = cut, y = depth),
fun.min = min,
fun.max = max,
# Não dá pra mostrar a mediana com barras de erro, sorry
#fun = median,
geom = "errorbar"
)
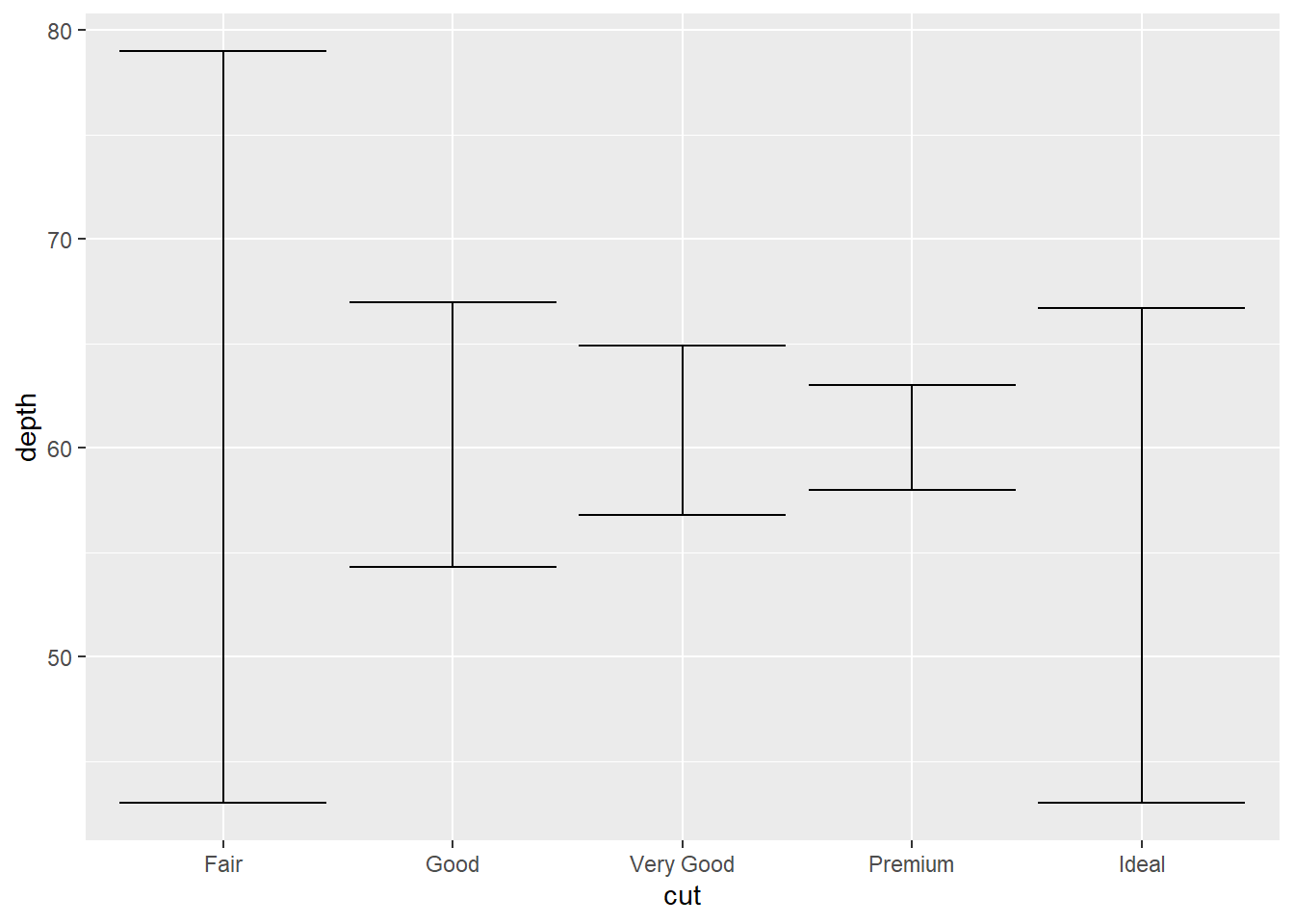
E era basicamente isso que eu tinha a dizer sobre como construir gráficos no ggplot2! Abaixo, uma seção com alguns detalhes para quem tiver interesse nessa parte de embelezamento dos gráficos.
Perfumaria
Essa seção pretende introduzir um pouco uma parte de customização dos gráficos. Frequentemente, as publicações de regras mais estritas sobre formatos, fontes, temas, etc. As opções padrão do ggplot2 podem não se acomodar, então, cabe a nós ajeitar essa reta final.
Títulos e rótulos
A melhor maneira de ajustar títulos e rótulos é através de labs, porque você resolve tudo em uma só invocação. Mas também há uma função ggtitle. Com ela, é possível setar apenas título e subtítulo.
ggplot(mpg, aes(displ, hwy, color = class)) +
geom_point() +
ggtitle("Título do gráfico", "Subtítulo do gráfico")
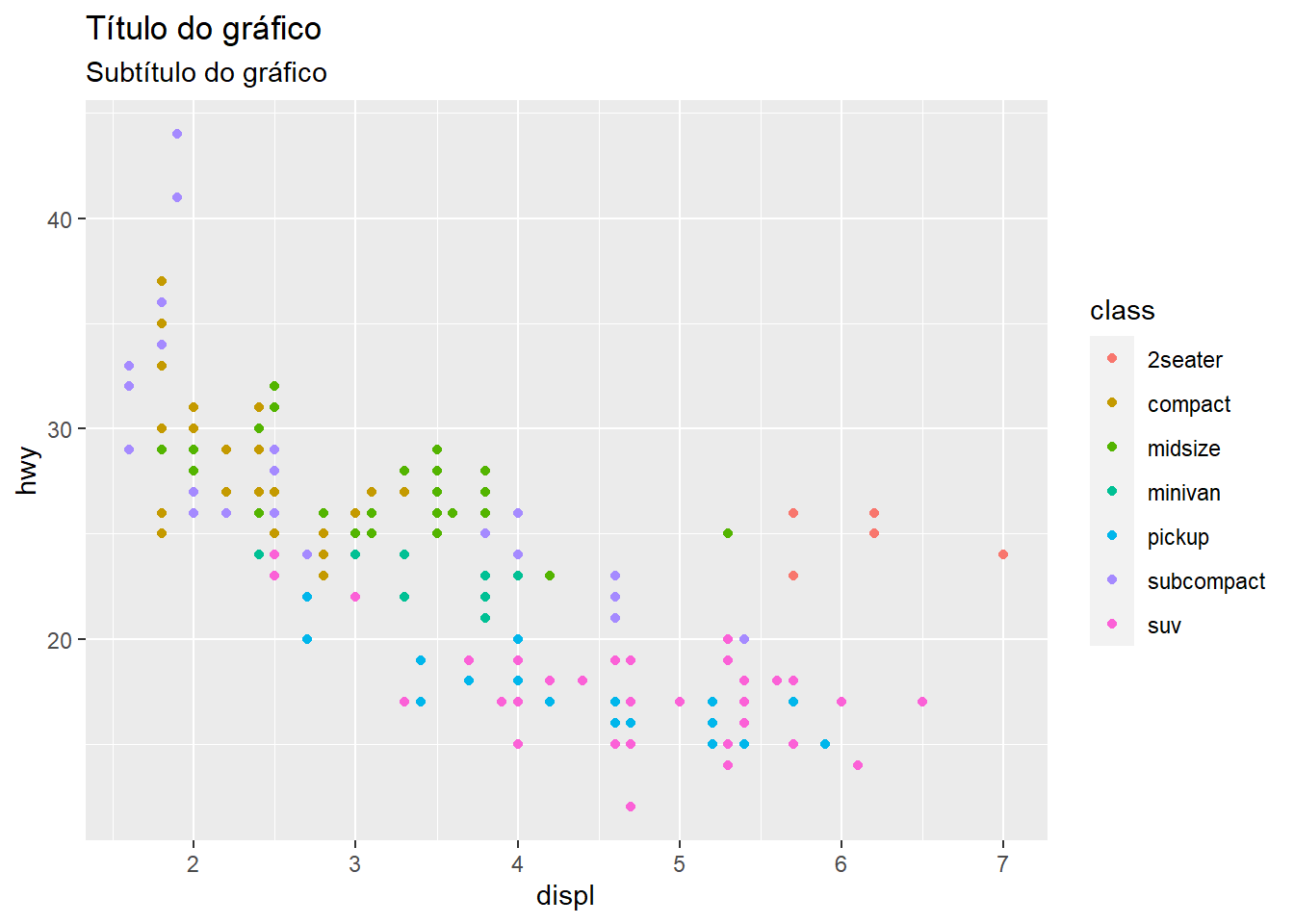
A maioria das opções de customização mais fina está na camada theme. Internamente, cada elemento do gráfico é controlado por uma função element_, por exemplo, element_text desenha textos e recebe argumentos relativos a isso, como família da fonte, tamanho, cor, etc.
Ali, você tem um controle mais direto sobre a construção do gráfico. No que diz respeito aos rótulos, podemos mudar a fonte do título.
ggplot(mpg, aes(displ, hwy, color = class)) +
geom_point() +
ggtitle("Título do gráfico", "Subtítulo do gráfico") +
# Family é meio complicado de mudar, mas você pode escolher serif, sans ou mono
theme(plot.title = element_text(family = "serif", face = "bold", colour = "red"),
plot.subtitle = element_text(family = "mono", face = "italic", color = "forestgreen"))
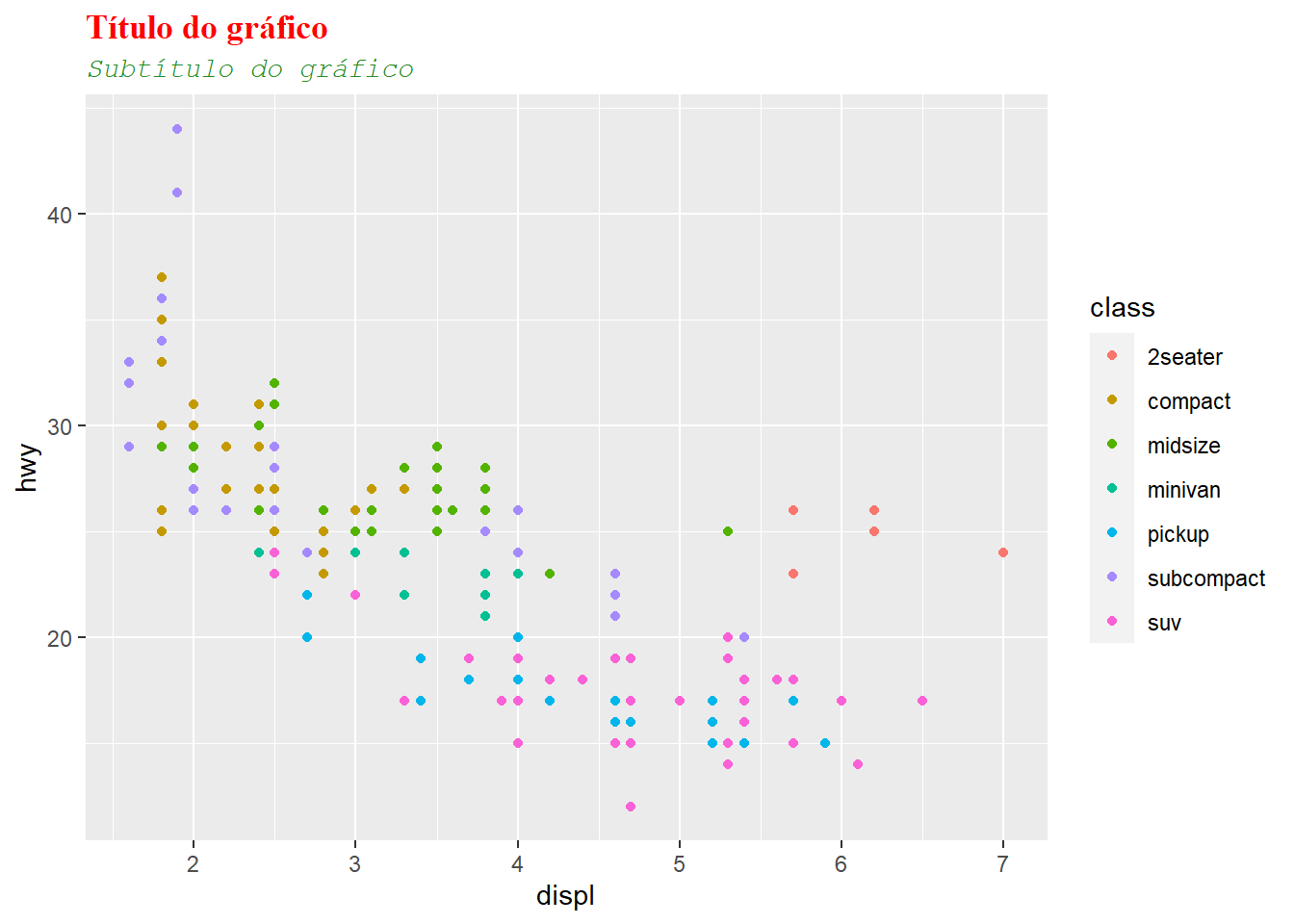
Usando uma síntaxe similar e os argumentos da função element_text, você pode mudar qual outro elemento textual do gráfico.
Eixos
Continuando o nosso frankenstein, podemos fazer alterações nos eixos, como remover pedaços de um eixo, modificar sua forma, seu ângulo e ajustar sua posição.
ggplot(mpg, aes(displ, hwy, color = class)) +
geom_point() +
ggtitle("Título do gráfico", "Subtítulo do gráfico") +
# Family é meio complicado de mudar, mas você pode escolher serif, sans ou mono
theme(plot.title = element_text(family = "serif", face = "bold", colour = "red"),
plot.subtitle = element_text(family = "mono", face = "italic", color = "forestgreen"),
# você pode remover pedaços inteiros do gráfico com "element_blank()"
axis.ticks.y = element_blank(),
axis.text.y = element_blank(),
axis.title.y = element_blank(),
# você pode mudar a orientação, angulo, posição e até formato de elementos
axis.title = element_text(angle = 90, hjust = 1),
axis.text.x = element_text(angle = 45, vjust = 1),
axis.ticks.x = element_line(
colour = "royalblue3",
arrow = grid::arrow(angle = 45, length = unit(0.5, "cm"), ends = "first", type = "closed"))
)
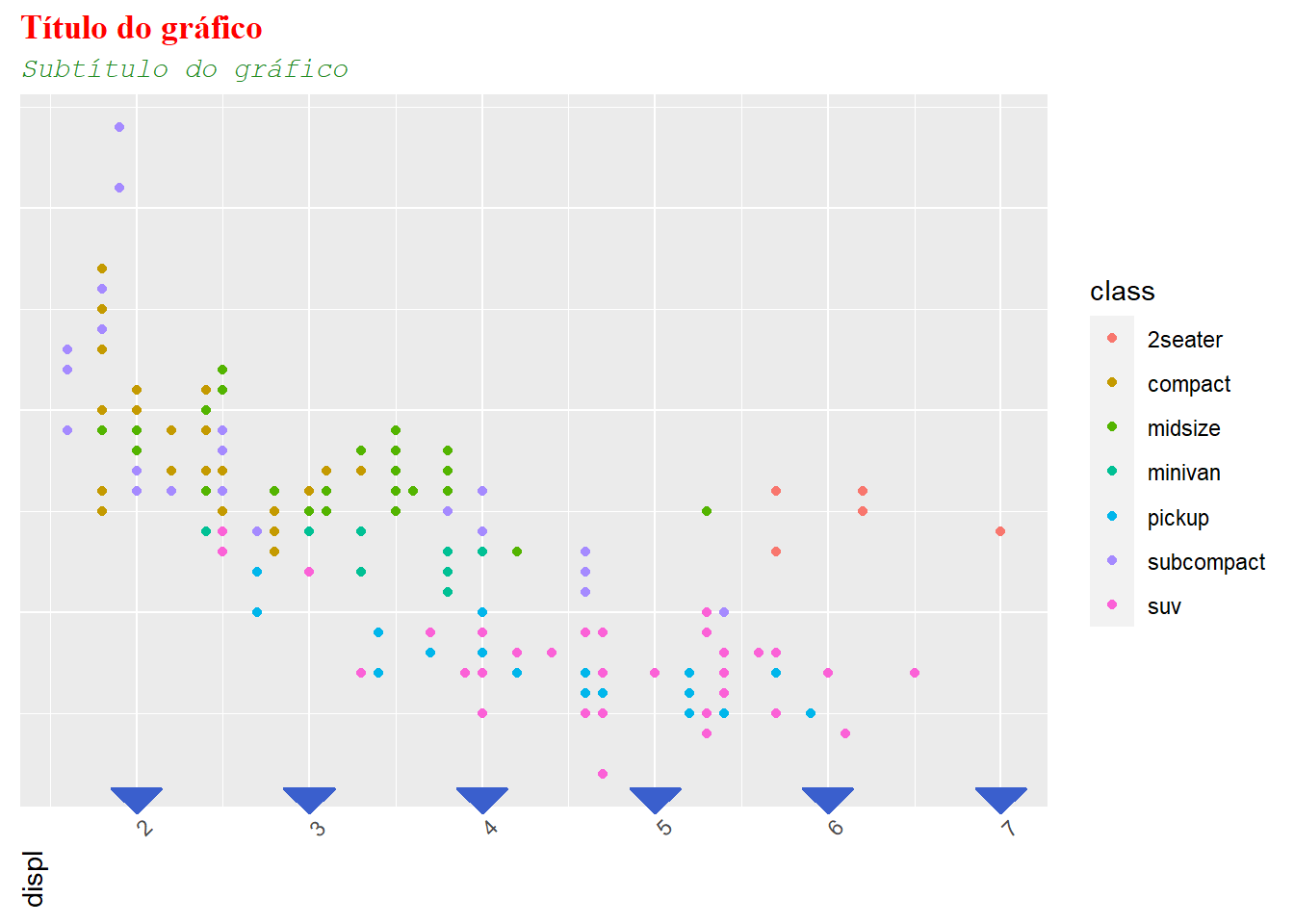
Realmente, o céu é o limite e você pode deixar o seu gráfico tão horrível quanto você quiser.
Legendas
Legendas no ggplot2 são controladas em alguns lugares diferentes. Elas são tratadas como guias (guides) no sentido de que são guias para o leitor. Vamos pegar outra variável de cores, para poder brincar com diferentes tipos de legenda.
ggplot(mpg, aes(displ, hwy, color = cyl)) +
geom_point()
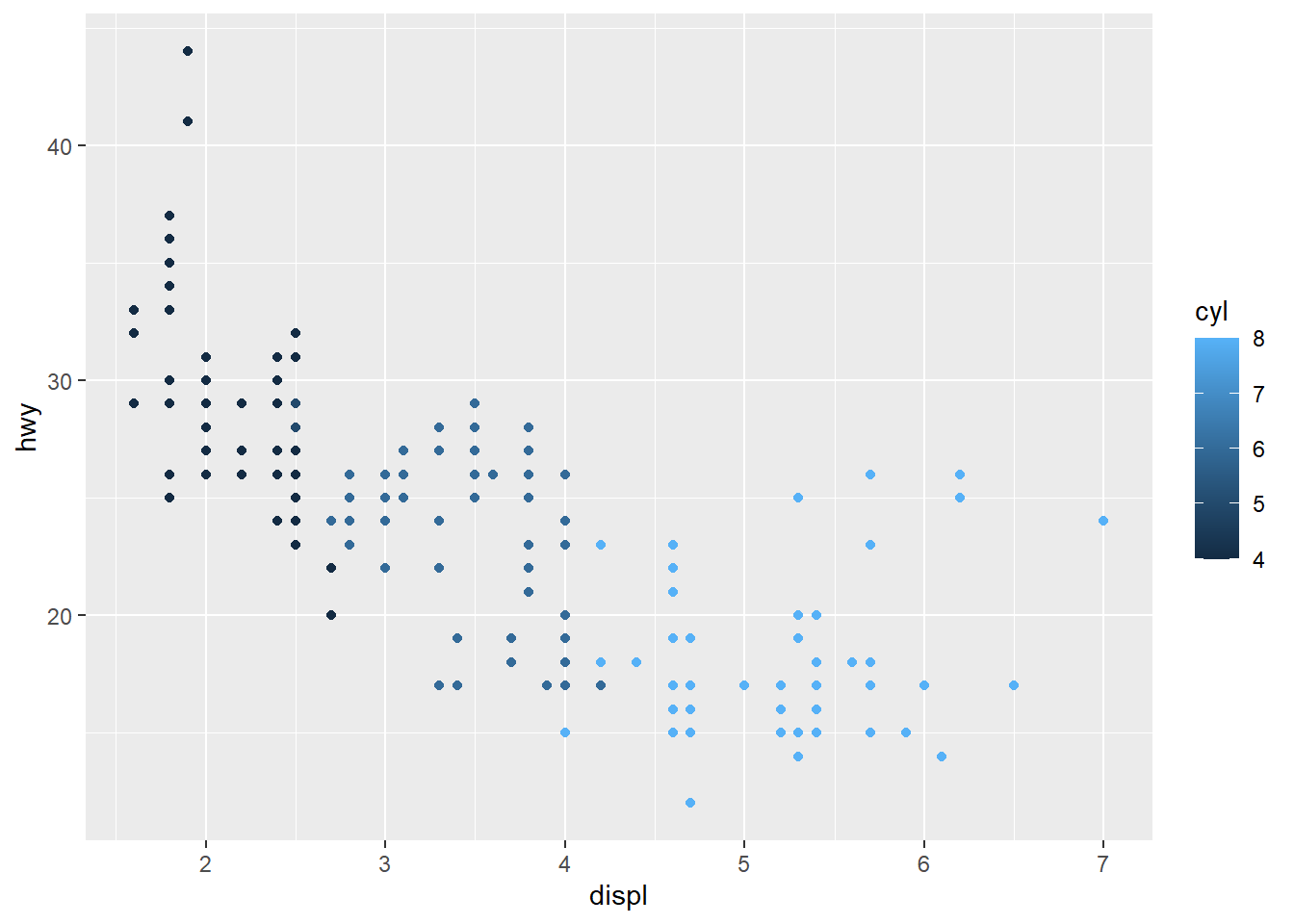
Por padrão, ele entende cilindros como numérico e faz uma barra de cores contínua. Mas eu quero uma legenda!
# Jeito 1 - Simples e rápido
ggplot(mpg, aes(displ, hwy, color = cyl)) +
geom_point() +
guides(color = "legend")
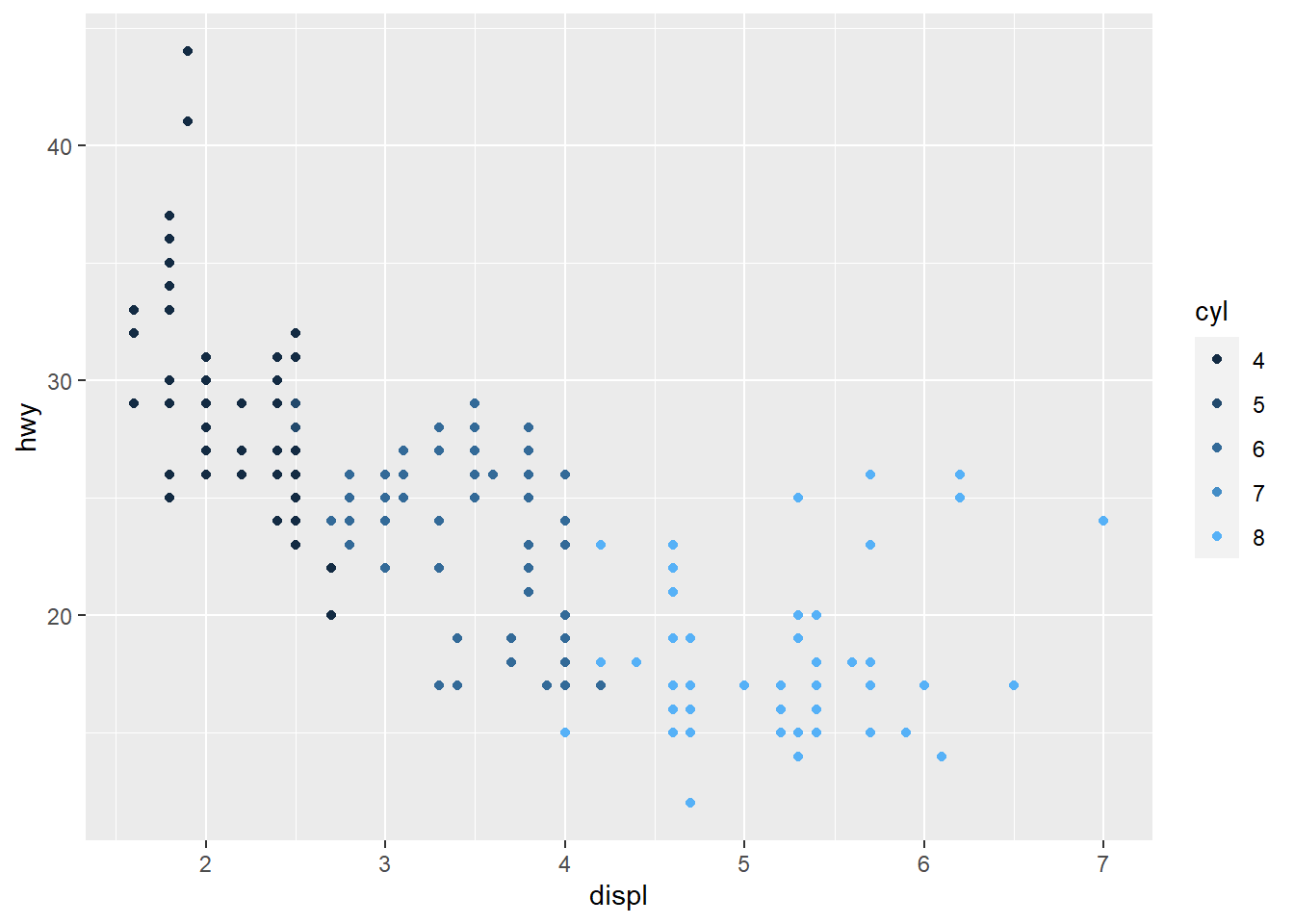
# Jeito 2 - Posso mudar detalhes!
ggplot(mpg, aes(displ, hwy, color = cyl)) +
geom_point() +
guides(color = guide_legend(title = "Cilindrossss",
title.position = "right",
label.position = "bottom",
direction = "horizontal"))
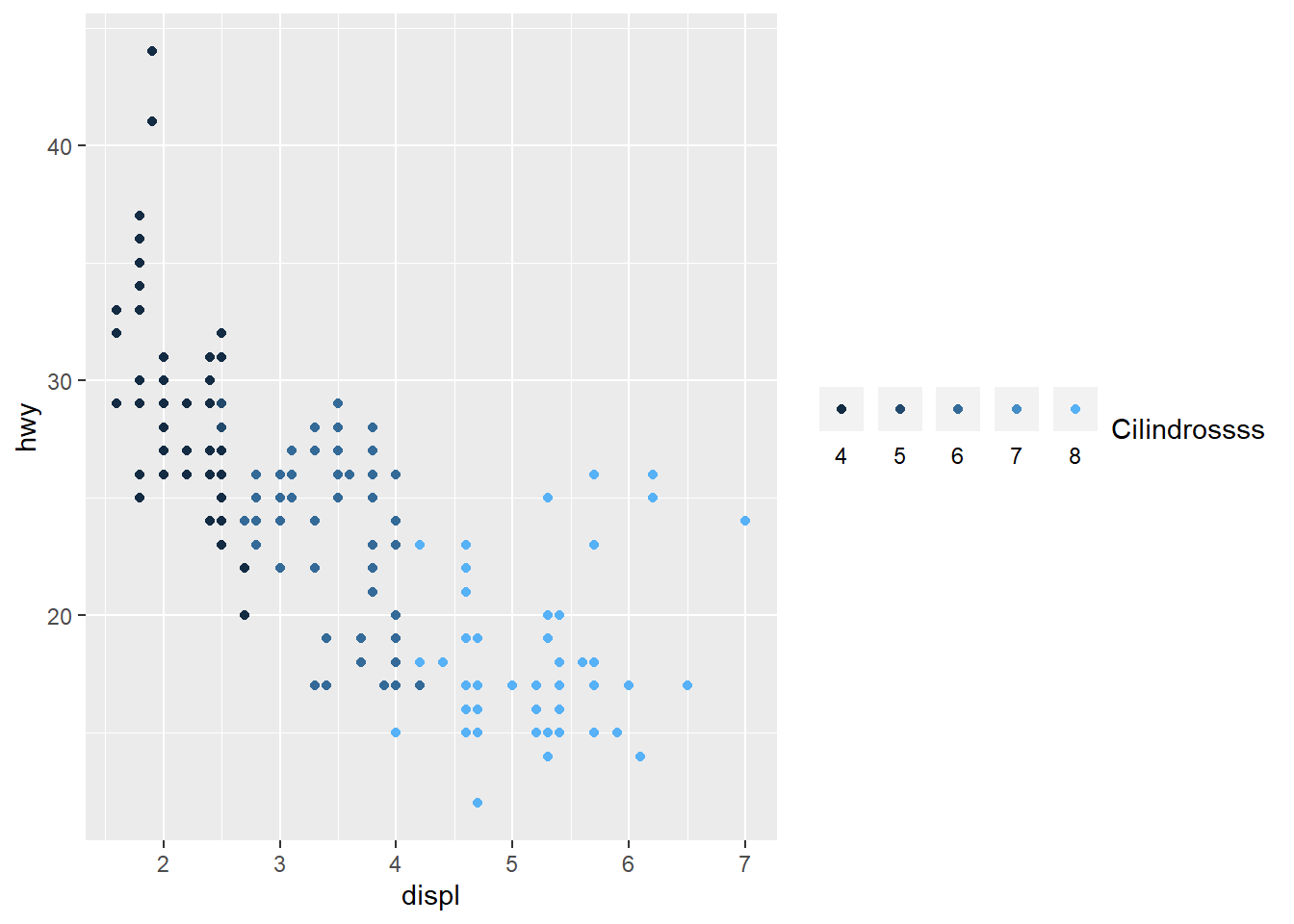
# Jeito 3 - Mexendo diretamente nas escalas
ggplot(mpg, aes(displ, hwy, color = cyl)) +
geom_point() +
# Minha escala de cores preferida
scale_color_viridis_c(guide = "legend", option = "B")
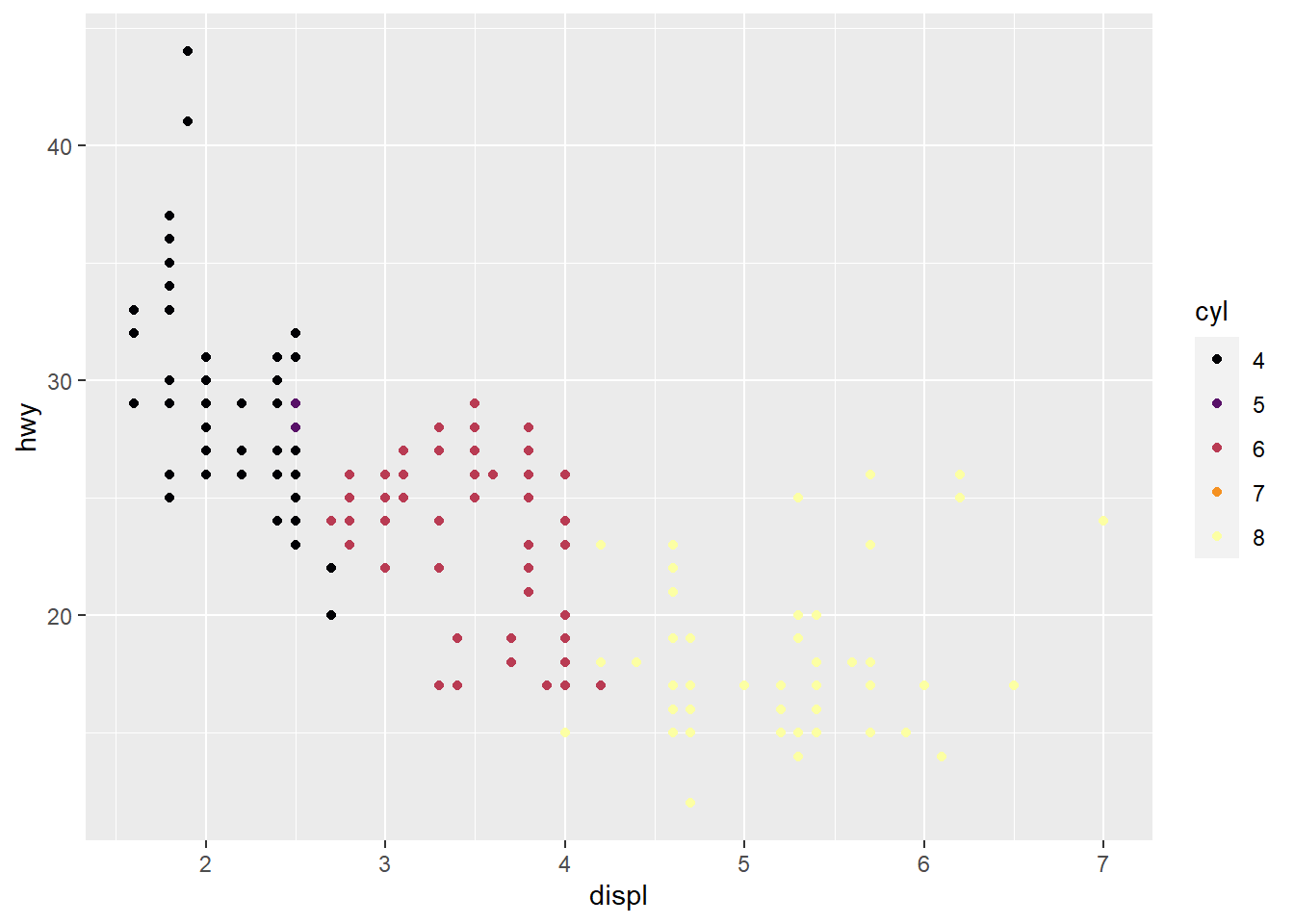
# Jeito 3 - de novo, mas agora usando a especificação mais completa do guia
ggplot(mpg, aes(displ, hwy, color = cyl)) +
geom_point() +
# Minha escala de cores preferida
scale_color_viridis_c(
guide = guide_legend(title = "Cilindrossss",
title.position = "right",
label.position = "bottom",
direction = "horizontal"),
option = "B")
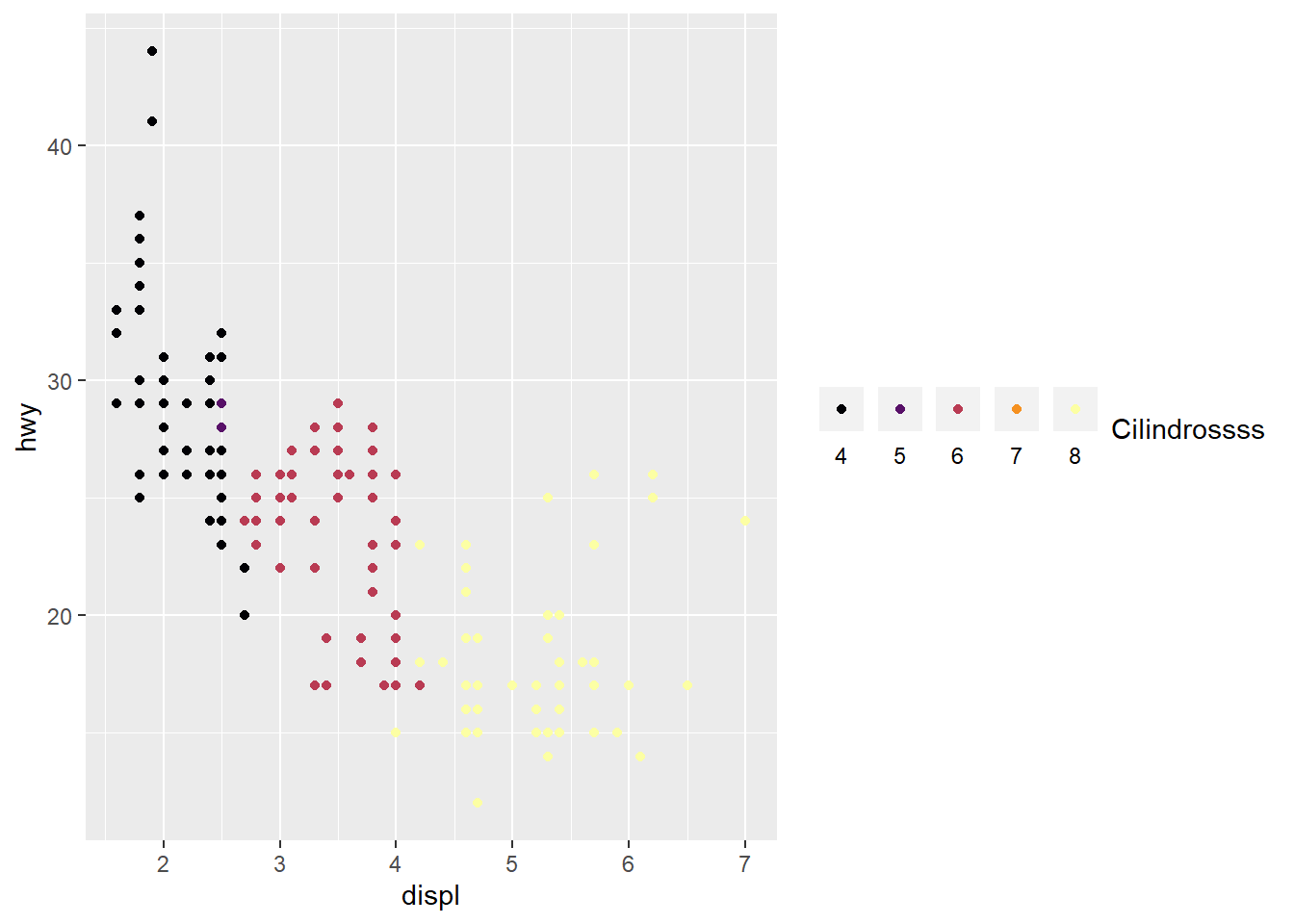
Em qualquer lugar onde você possa especificar guides, você pode passar o valor FALSE para remover a legenda.
# Na camada "guides()"
ggplot(mpg, aes(displ, hwy, color = cyl, size = cyl)) +
geom_point() +
guides(color = FALSE)
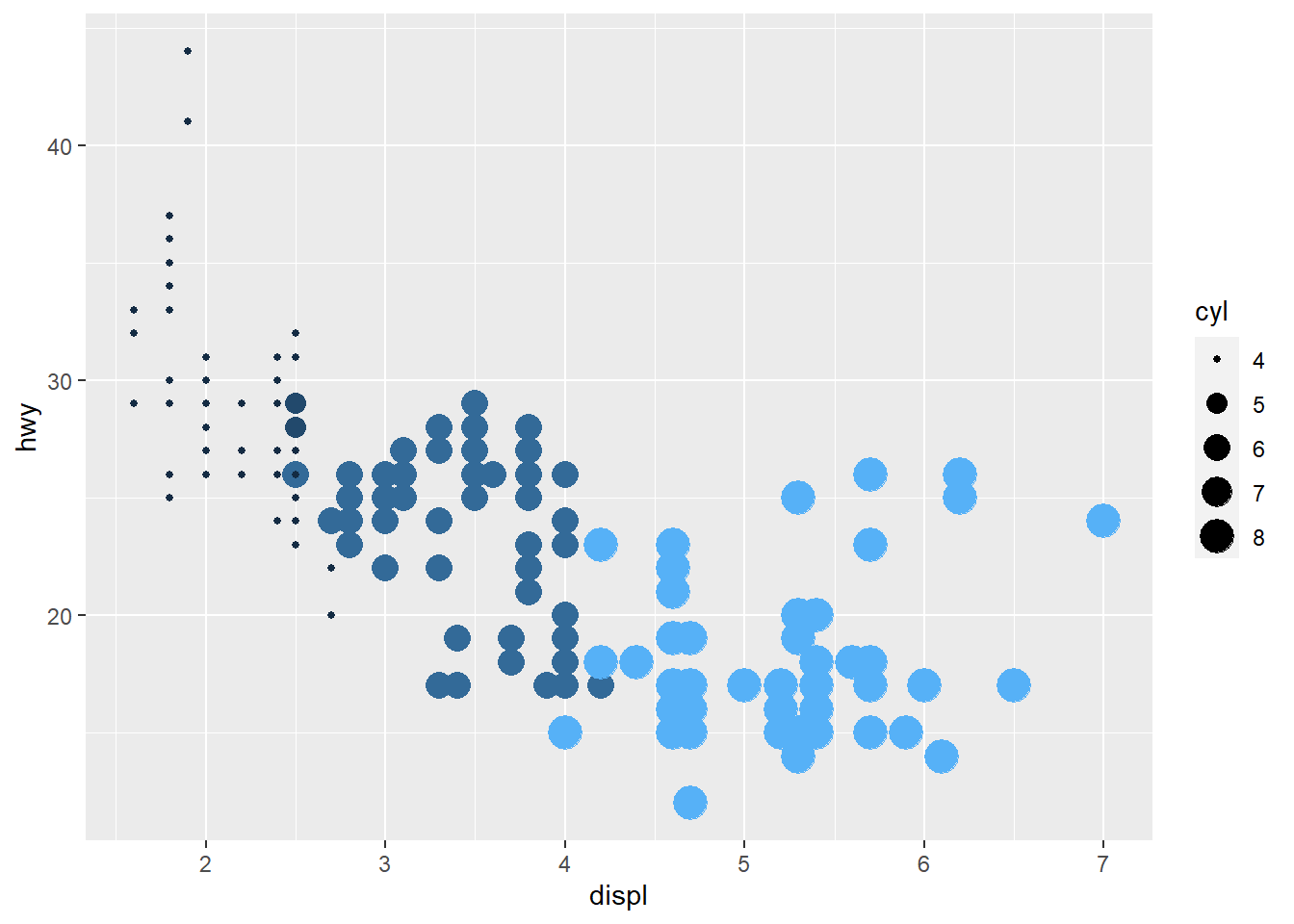
# Na própria escala
ggplot(mpg, aes(displ, hwy, color = cyl, size = cyl)) +
geom_point() +
scale_size(guide = FALSE)
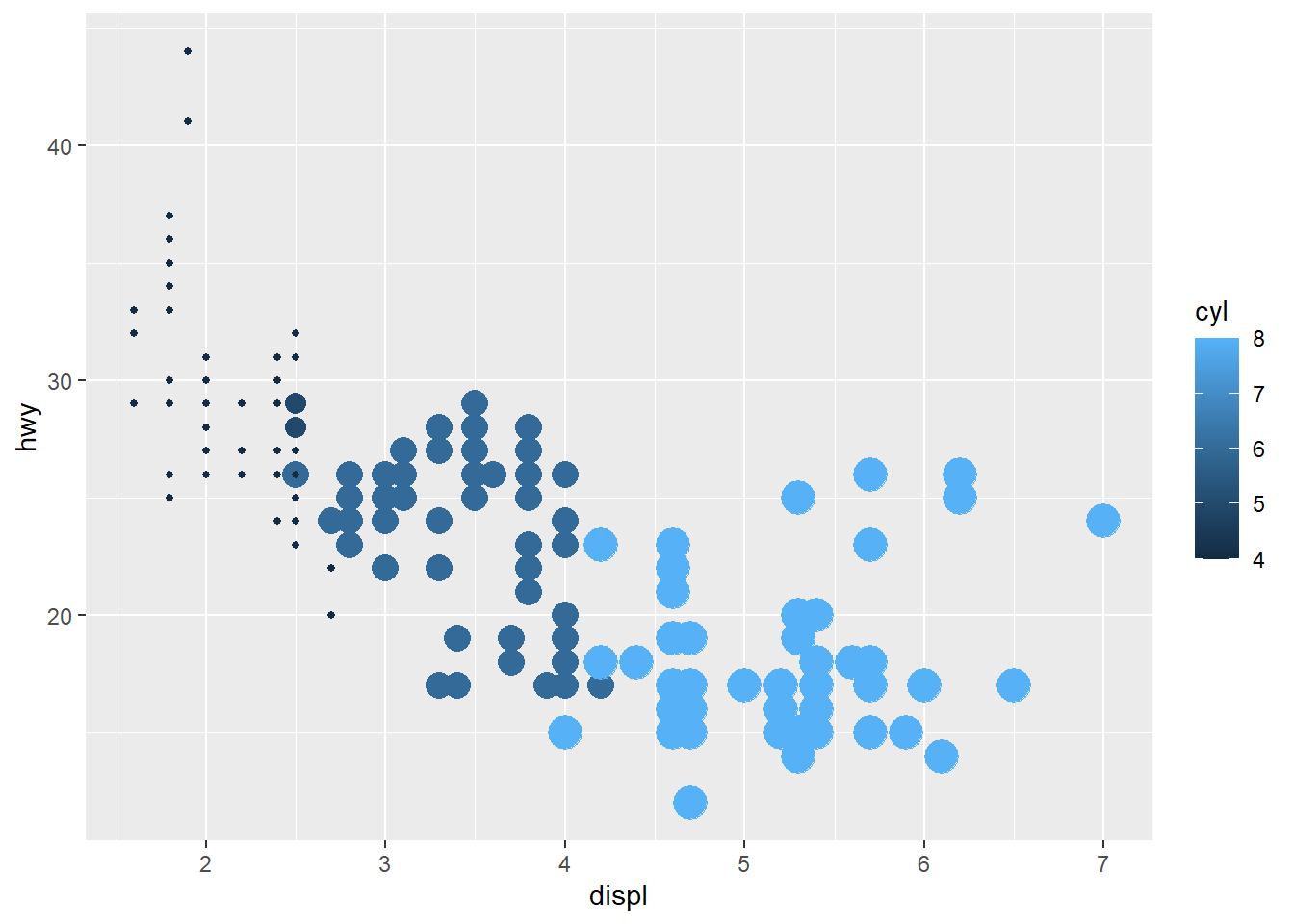
# Bônus = no tema, mas aí você remove todas
ggplot(mpg, aes(displ, hwy, color = cyl, size = cyl)) +
geom_point() +
theme(legend.position = "none")
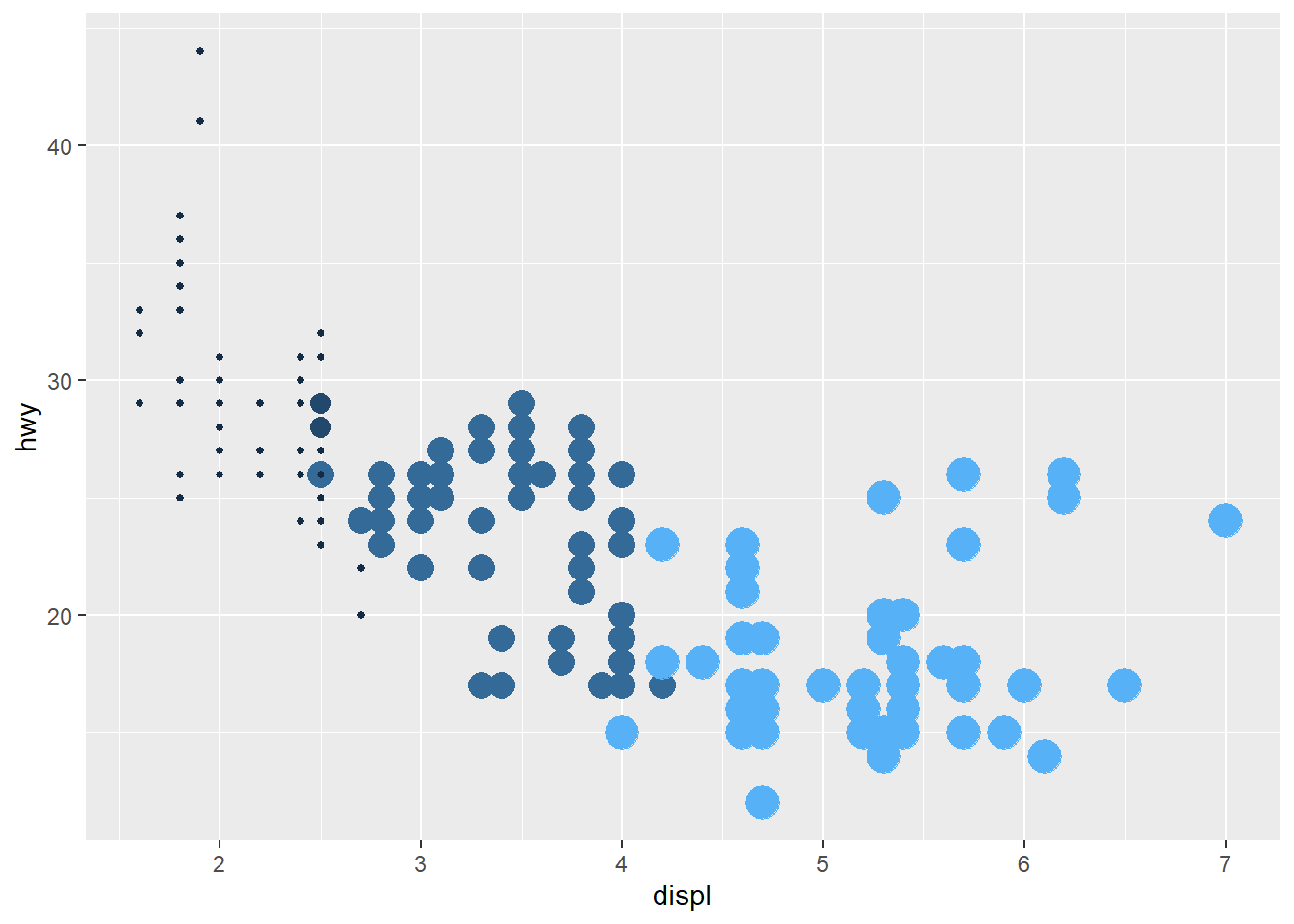
Escalas
Já dei uma palhinha de editar escalas, antes, então aqui vai um pouco mais de detalhe:
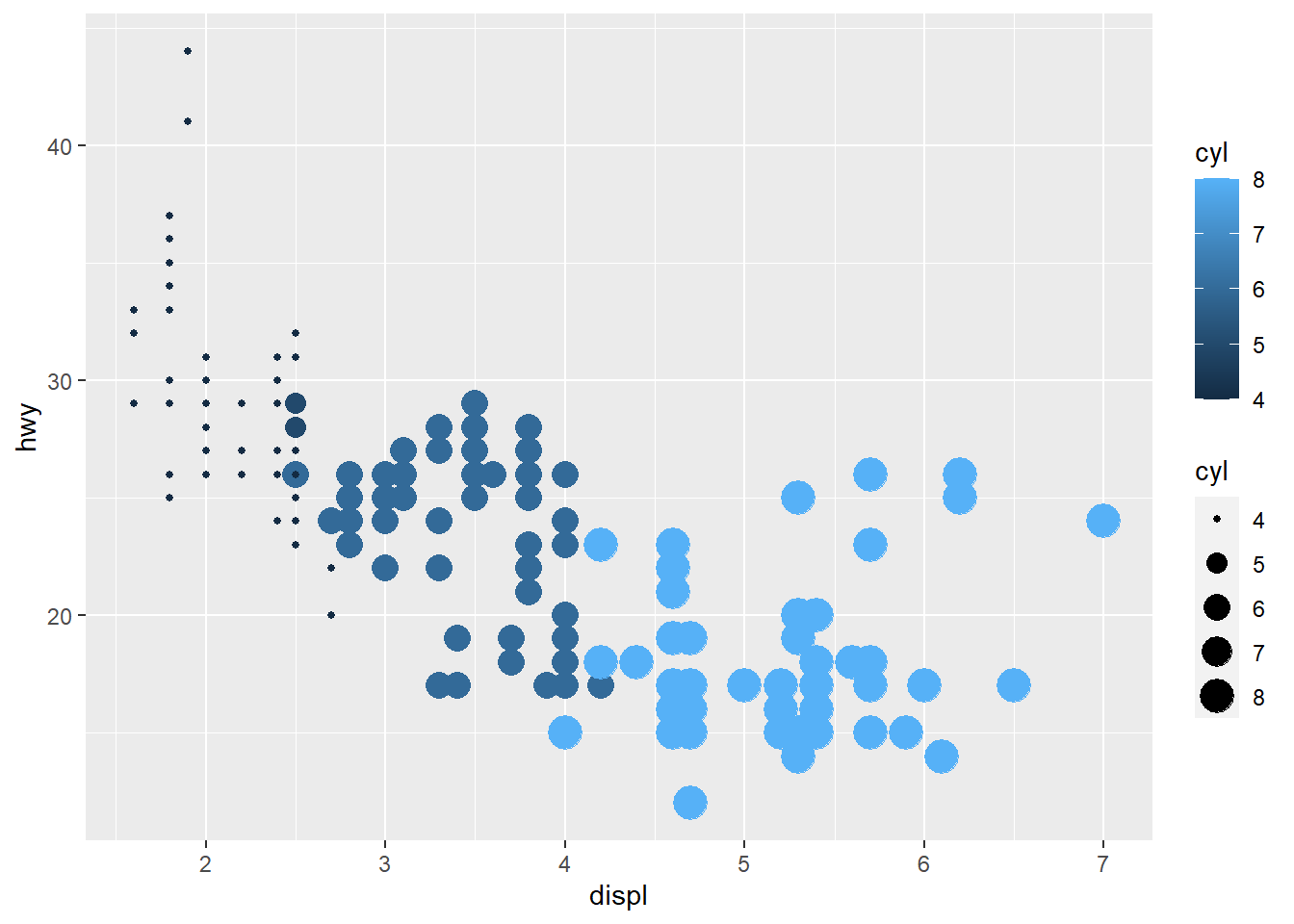
ggplot(mpg, aes(displ, hwy, color = cyl, size = cyl)) +
geom_point()
# Mudar as cores manualmente
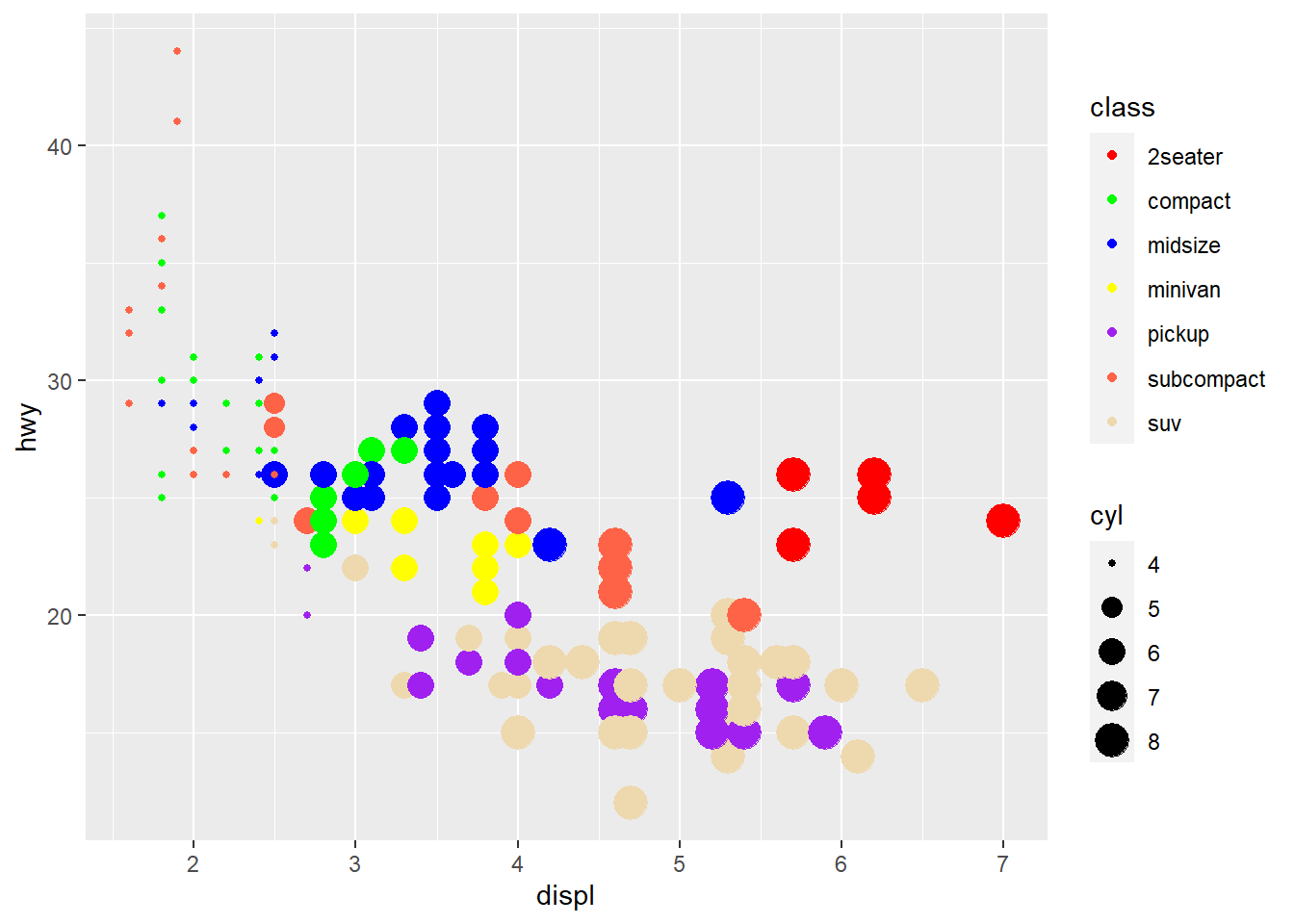
cores <- c("red", "green", "blue", "yellow", "purple", "tomato", "wheat2")
ggplot(mpg, aes(displ, hwy, color = class, size = cyl)) +
geom_point() +
scale_color_manual(values = cores)
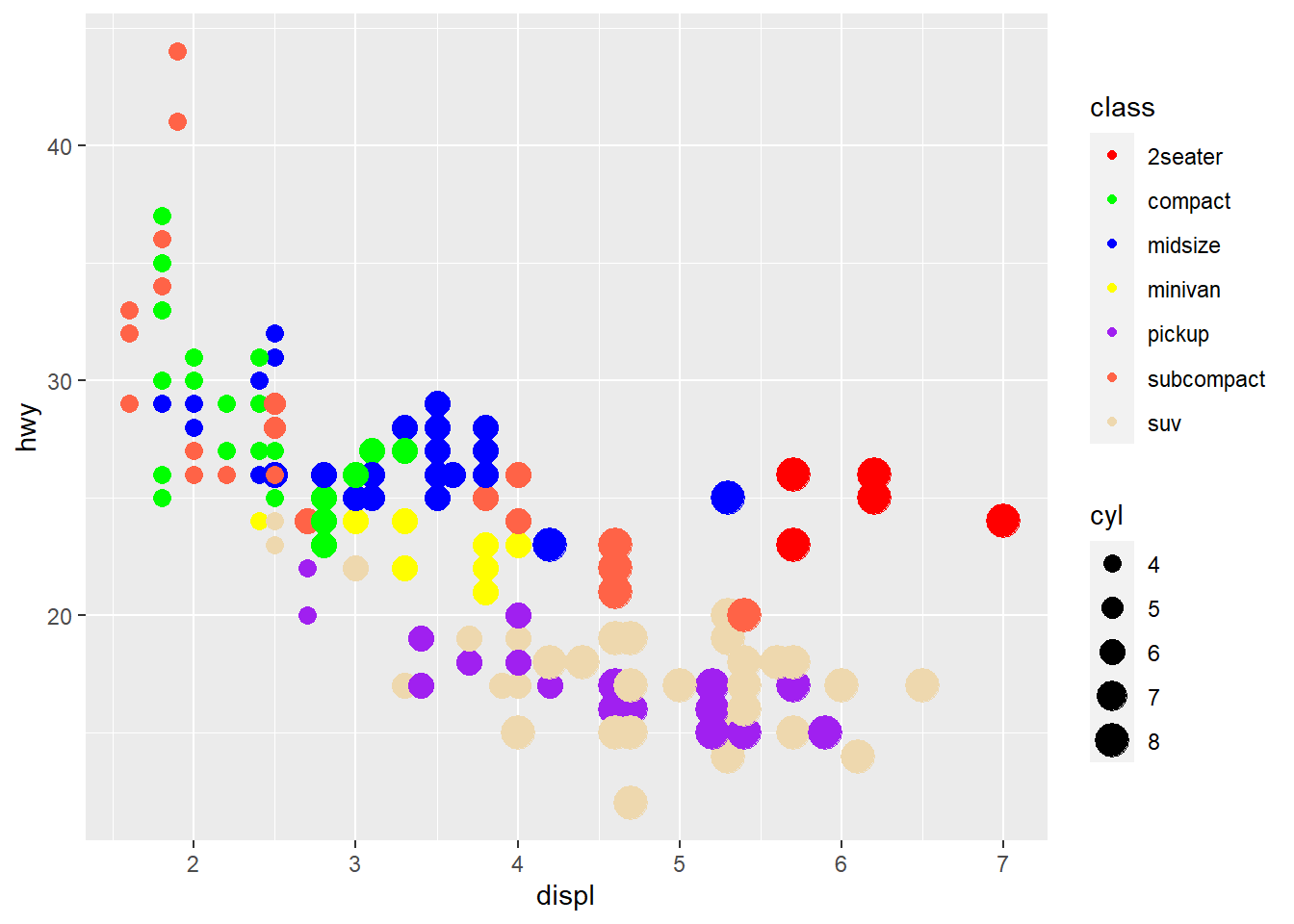
# Mudar os tamanhos
ggplot(mpg, aes(displ, hwy, color = class, size = cyl)) +
geom_point() +
scale_color_manual(values = cores) +
# scale_radius para fazer proprcional ao raio
scale_radius(range = c(3,6))
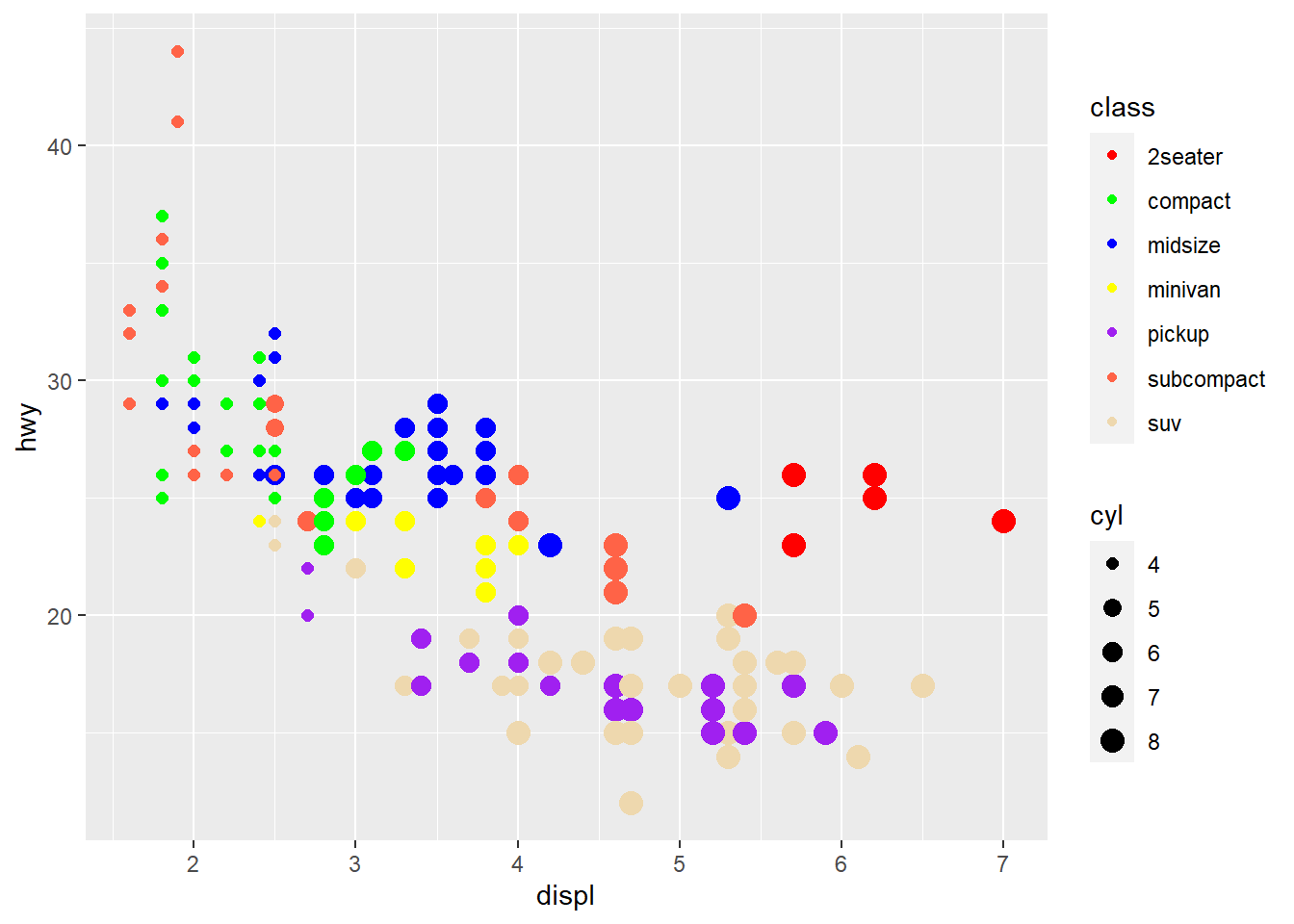
ggplot(mpg, aes(displ, hwy, color = class, size = cyl)) +
geom_point() +
scale_color_manual(values = cores) +
# scale_size para fazer proprcional a área
scale_size(range = c(2,4))
É possível aplicar transformações na variável diretamente na escala, mudar o número de breaks e especificar labels e alterar os limites do gráfico manualmente.
ggplot(mpg, aes(displ, hwy, color = class, size = cyl)) +
geom_point() +
scale_x_continuous(trans = "sqrt", name = "Peso") +
scale_y_continuous(
name = "Consumo (rodovia)",
limits = c(0, 50),
breaks = c(10, 20, 30, 40, 50),
labels = c("fogo no clima", "aquecimento global", "caldeira planetária", "deixa pra próxima geração", "desastre em câmera lenta"))
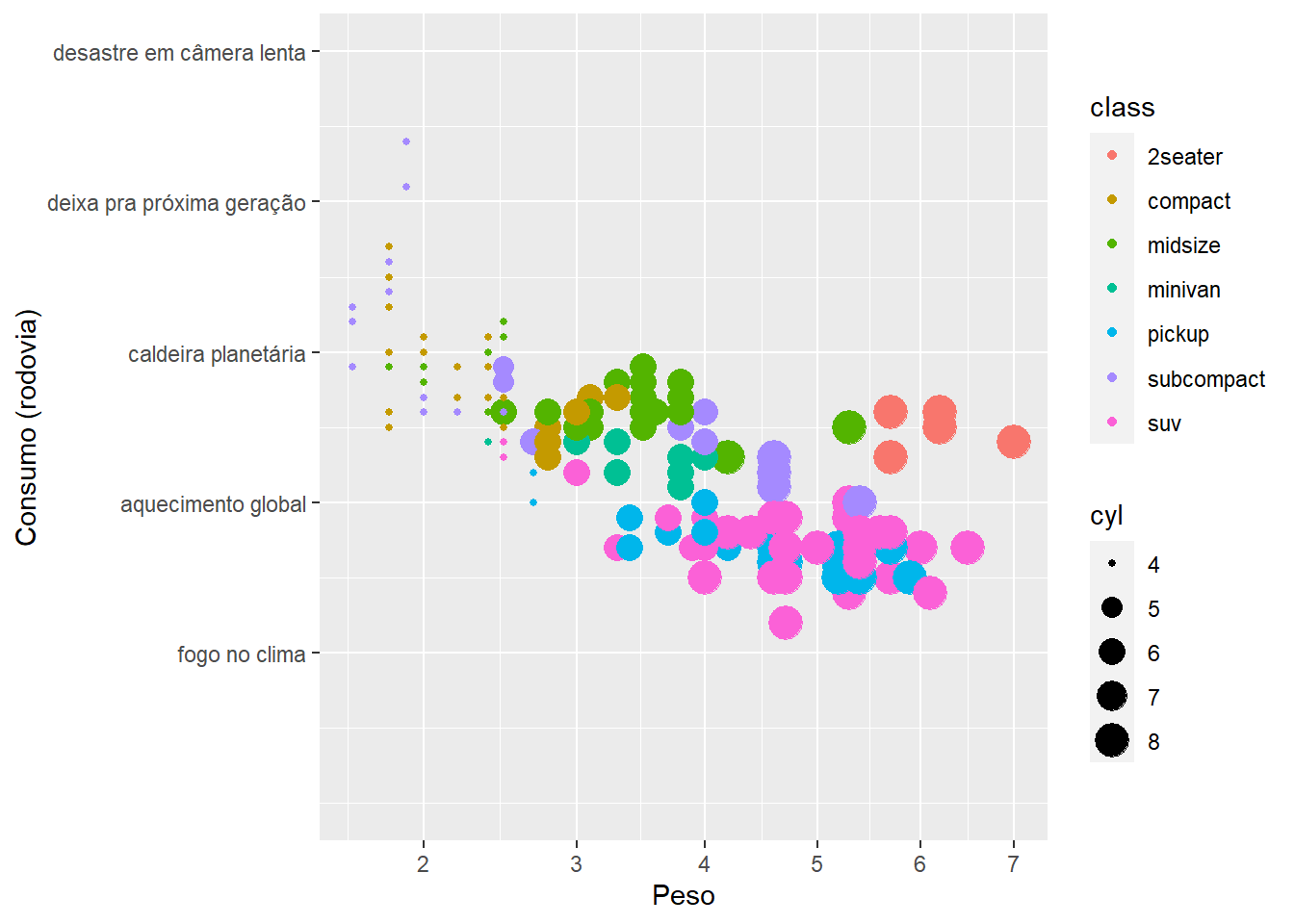
Cada escala vai ter argumentos específicos que fazem sentido em seu próprio contexto. Escalas contínuas tem argumentos para transformação estatística, escalas discretas não aceitam argumentos contínuos e etc.
Isto encerra nossa parte de ggplot2, que tal uns exercícios pra esquentar?
Exercícios
- O que tem de errado no código abaixo? Por que os pontos não ficaram azuis?
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = "blue"))
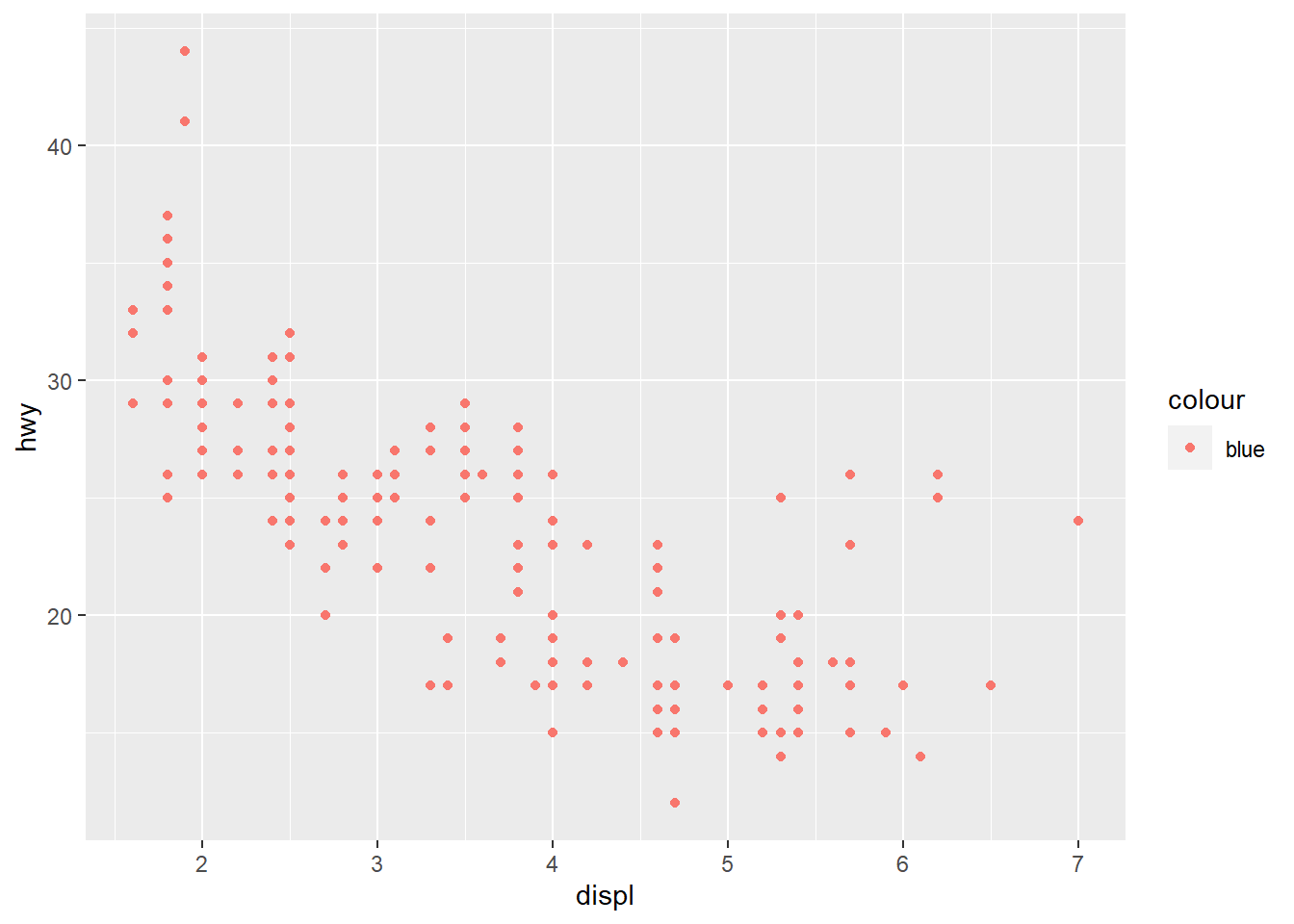
-
Utilizando o banco
mpg, faça o diagrama de dispersão dedisplporhwye mapeie a cor paraclass, o tamanho paracyle a forma paramanufacturer. Como esses atributos estéticos se comportam diferente para variáveis categóricas vs contínuas? -
Utilizando o
diamonds, crie um diagrama de dispersão que relacionecaratcomprice. Explore algumas outras variáveis utilizando escalas de cor para ver se você identifica algum padrão. Aplique transformações nas variáveis que você considerar justificadas. -
Ainda continuando o exemplo anterior, aplique um
geom_smoothutilizando várias opções demethodpara as variáveis originais ou transformadas. -
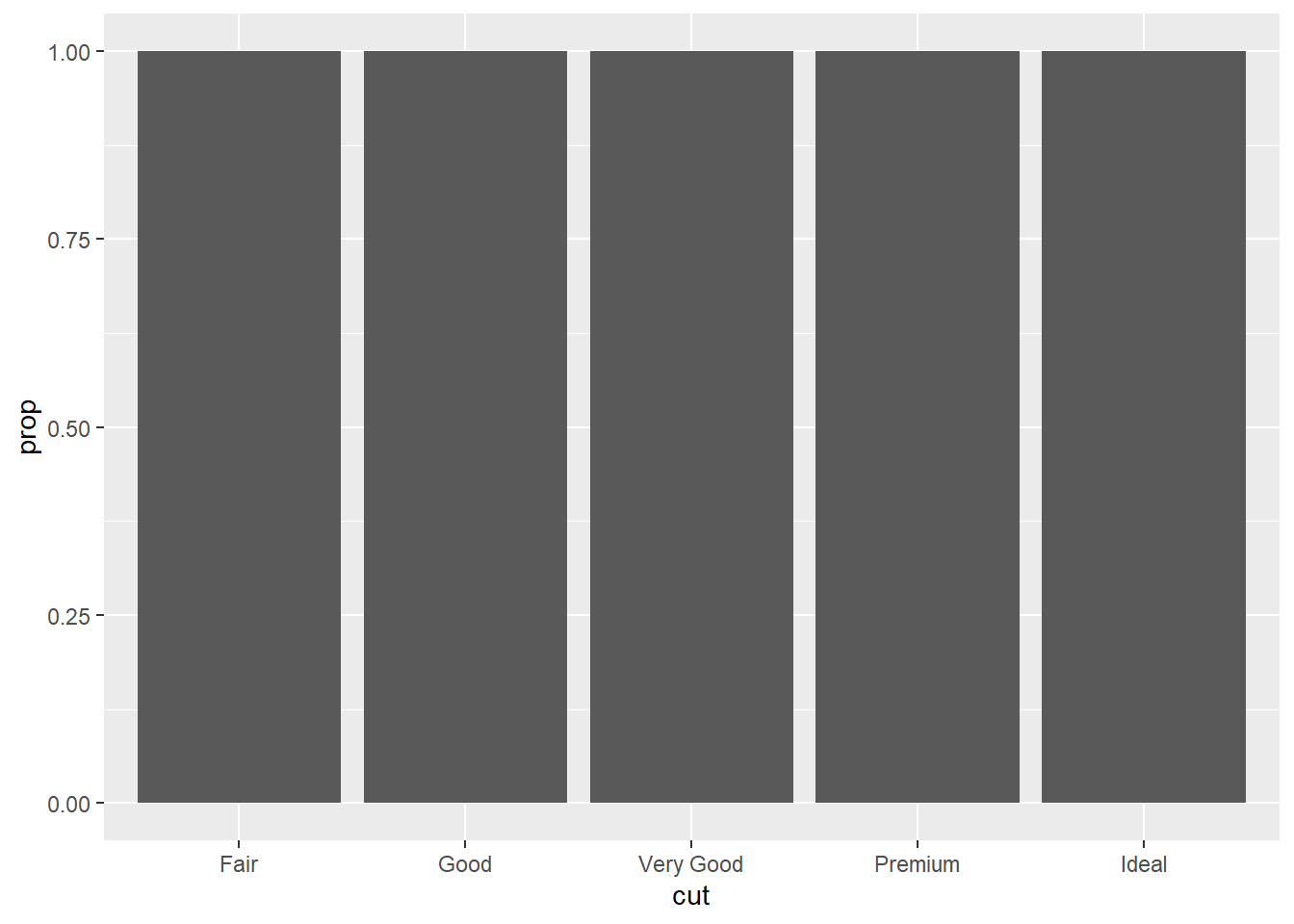
No nosso gráfico de barras usando
stat(prop)a gente precisou colocargroup = 1, porque? Qual é a diferença entre esses dois códigos?
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, y = after_stat(prop)))
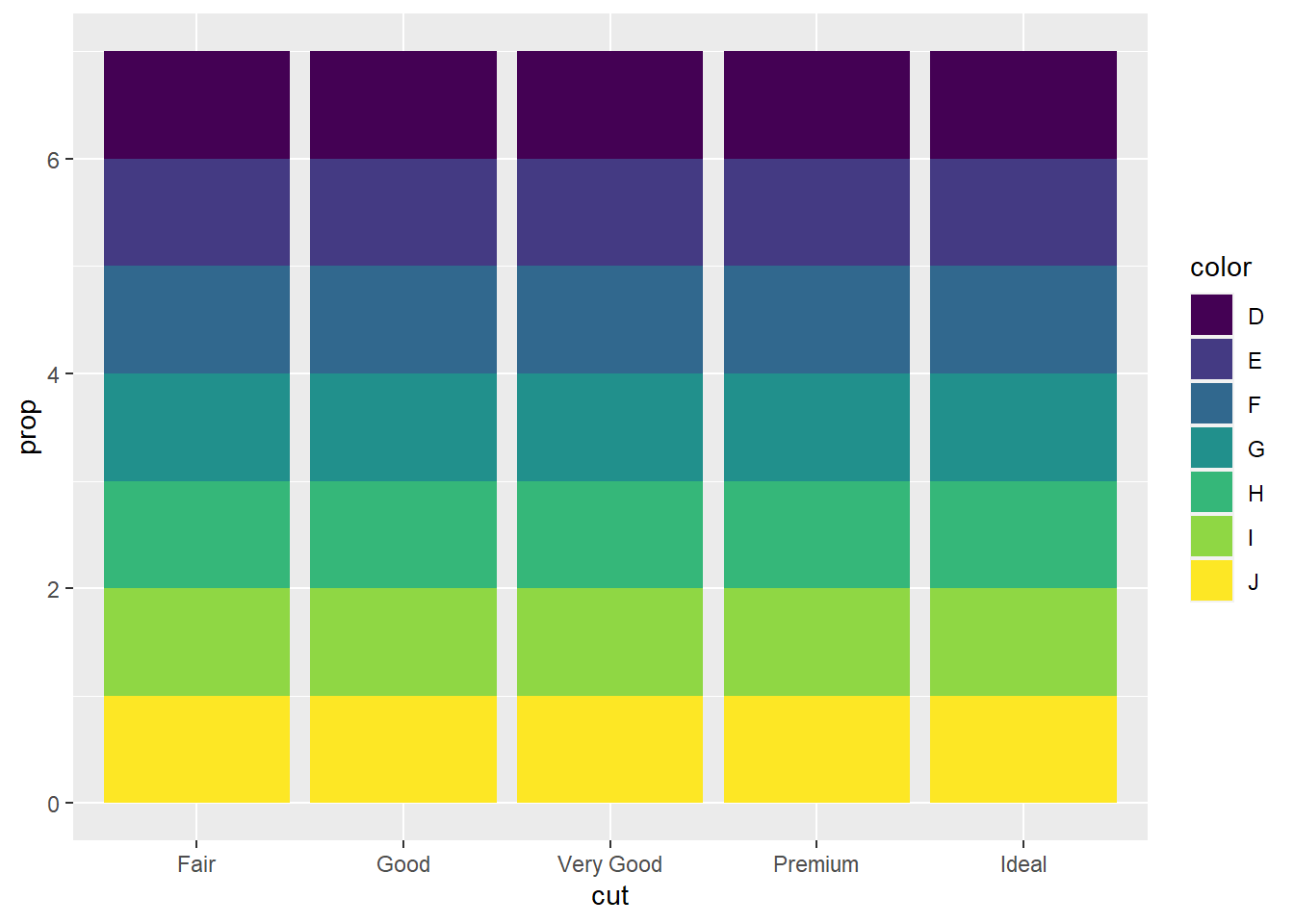
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = color, y = after_stat(prop)))
stat_smoothé muito parecido comgeom_smooth, mas há uma diferença sutil. Compare os códigos abaixo.
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_smooth()
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
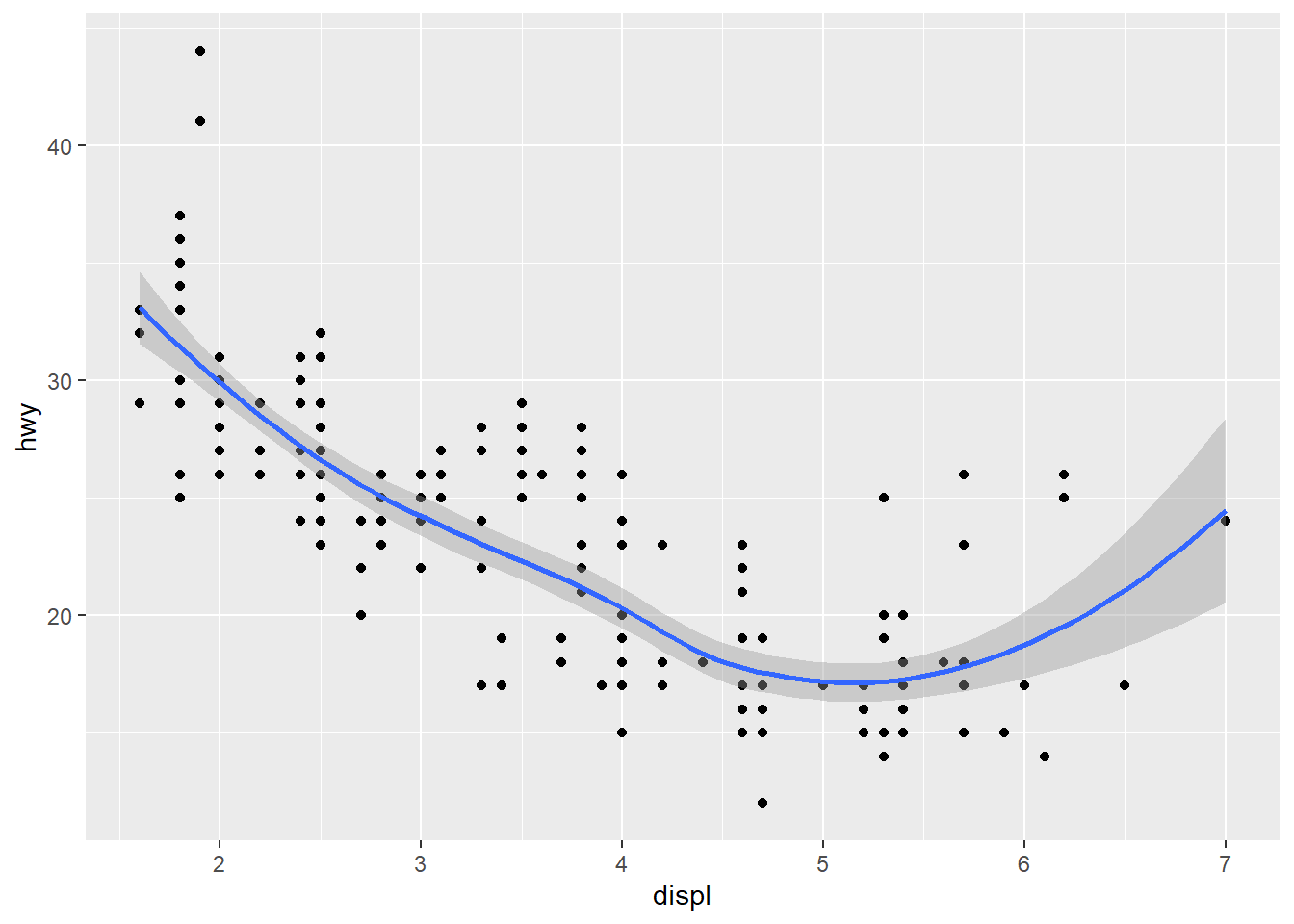
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
stat_smooth(geom = "step")
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
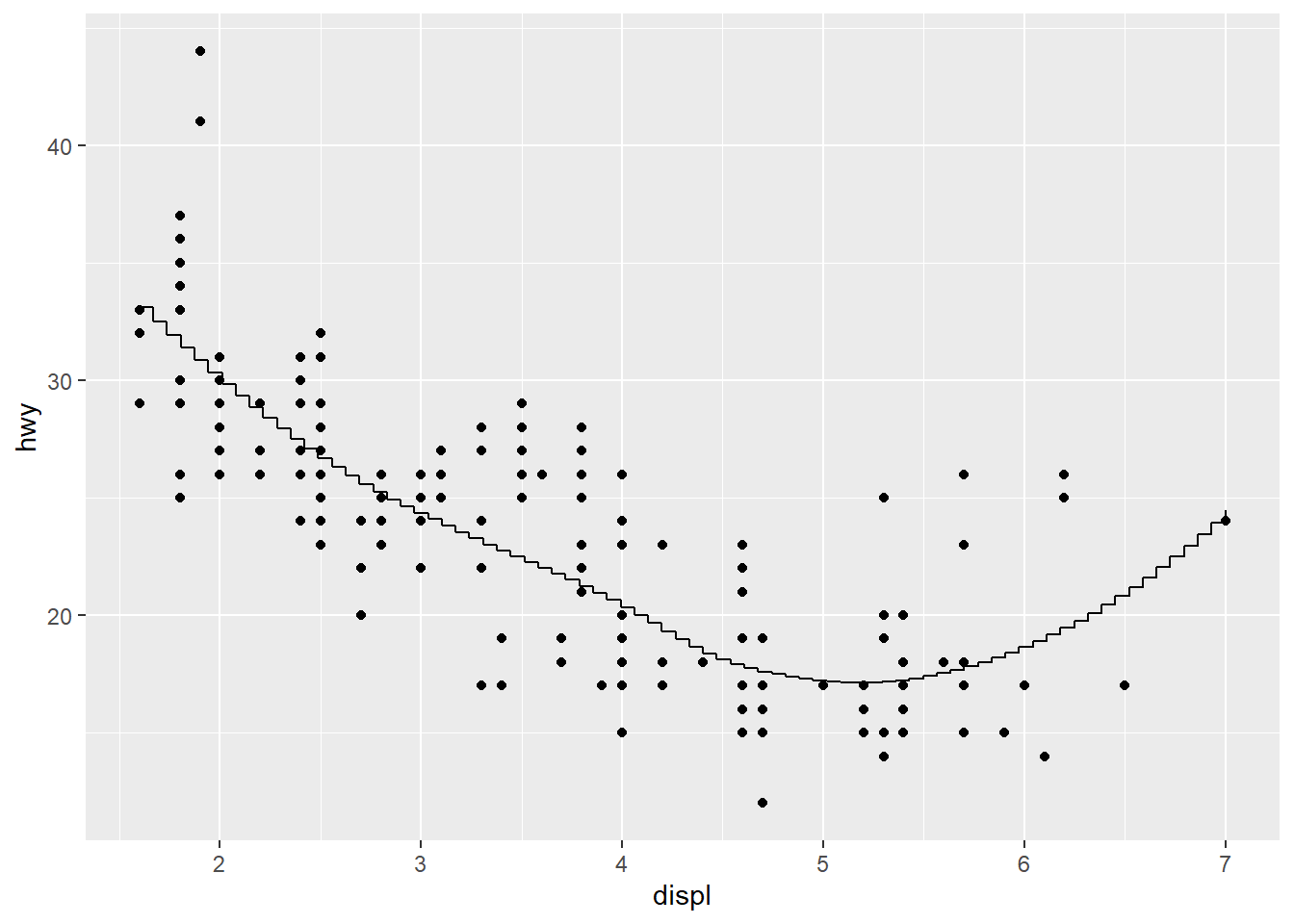
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
stat_smooth(geom = "linerange")
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
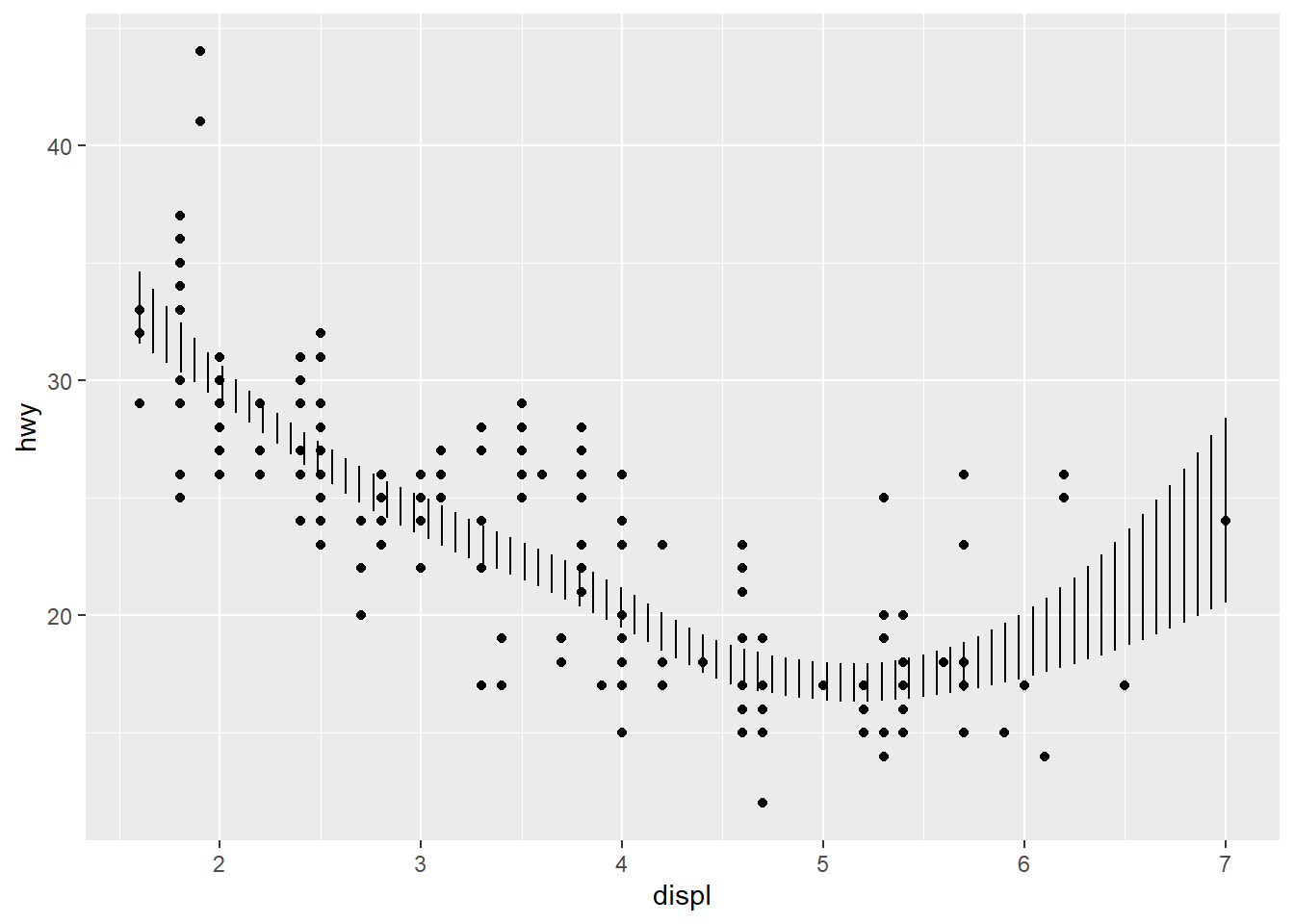
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
stat_smooth(geom = "errorbar")
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
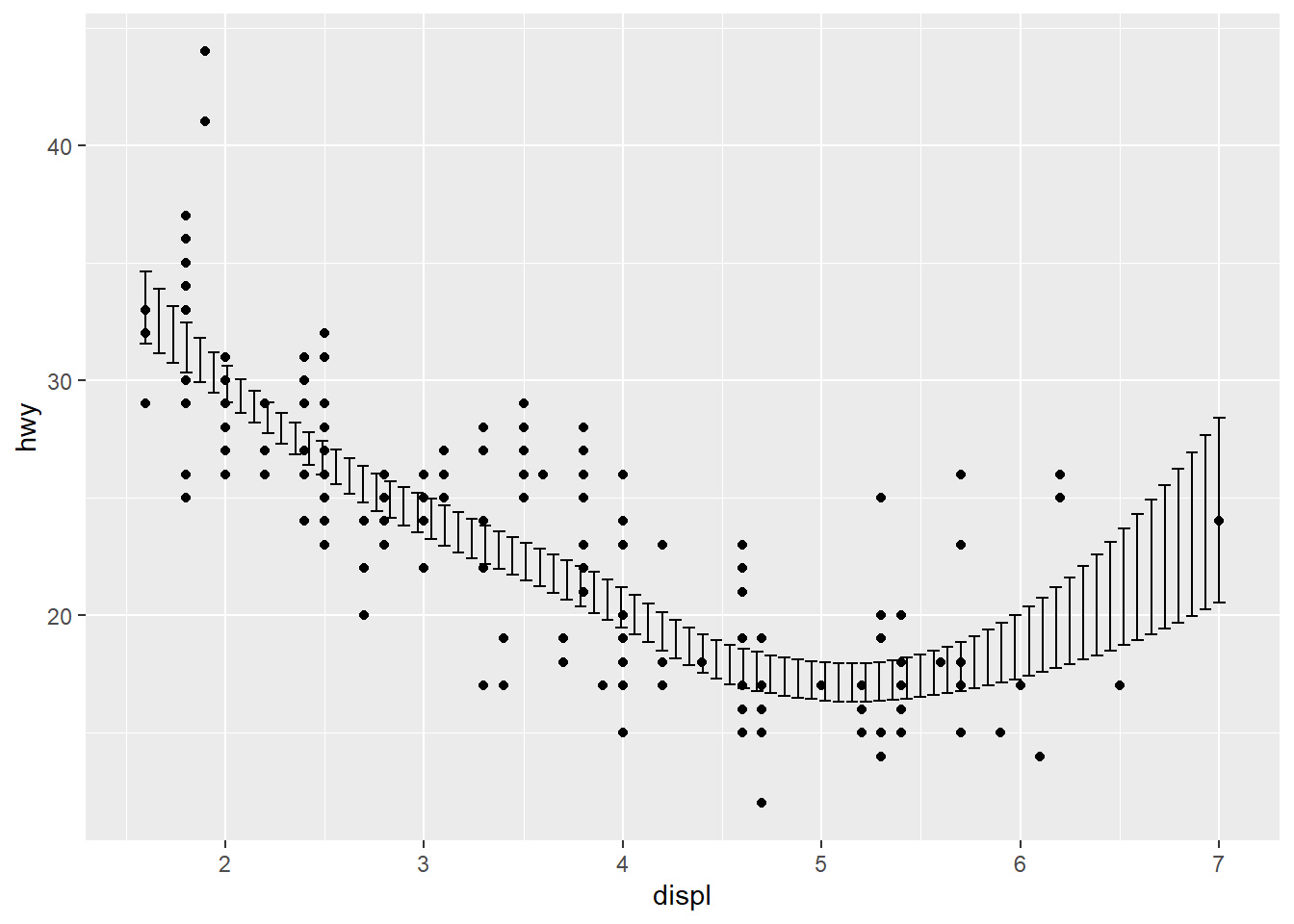
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
stat_smooth(geom = "crossbar")
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
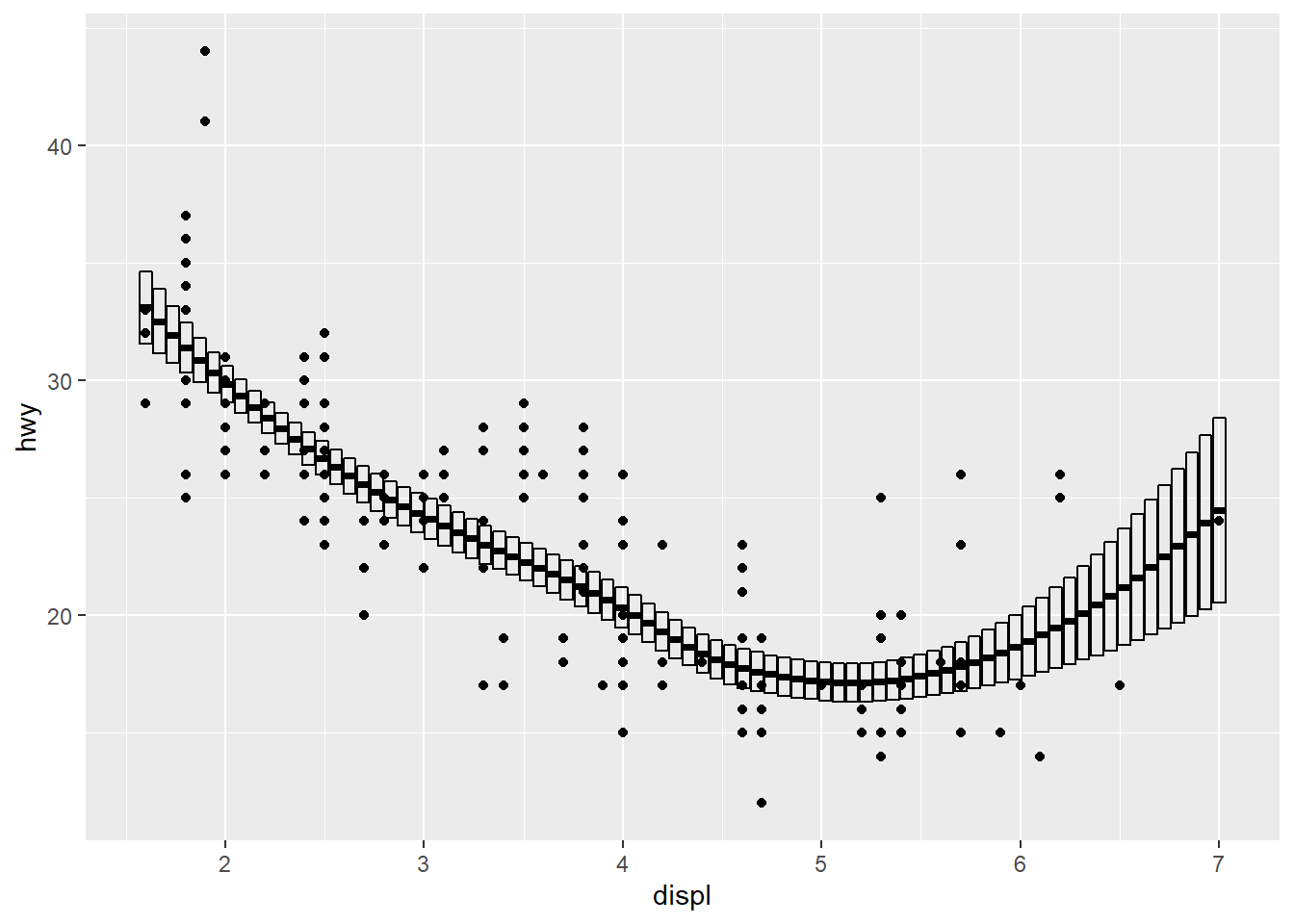
-
Usando o
mpgefacet_grid, crie um scatterplot que contenhadisplno eixo x,hwyno eixo y,classna cor,drvnas facetas-coluna ecylnas facetas linha. -
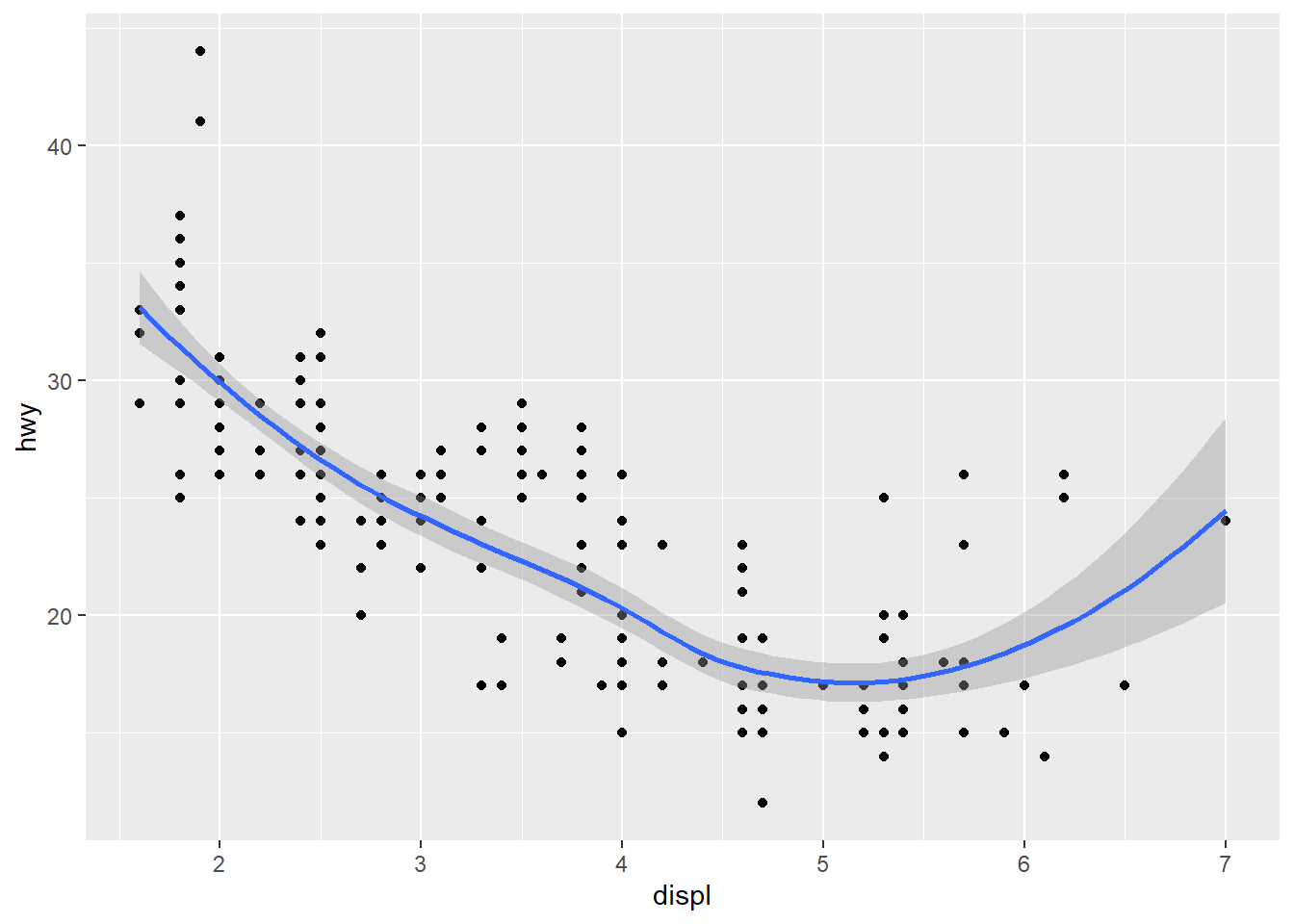
Você acha que os dois gráficos abaixo ficarão diferentes um do outro? Porque? Tente responder antes de rodar o código.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth()
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
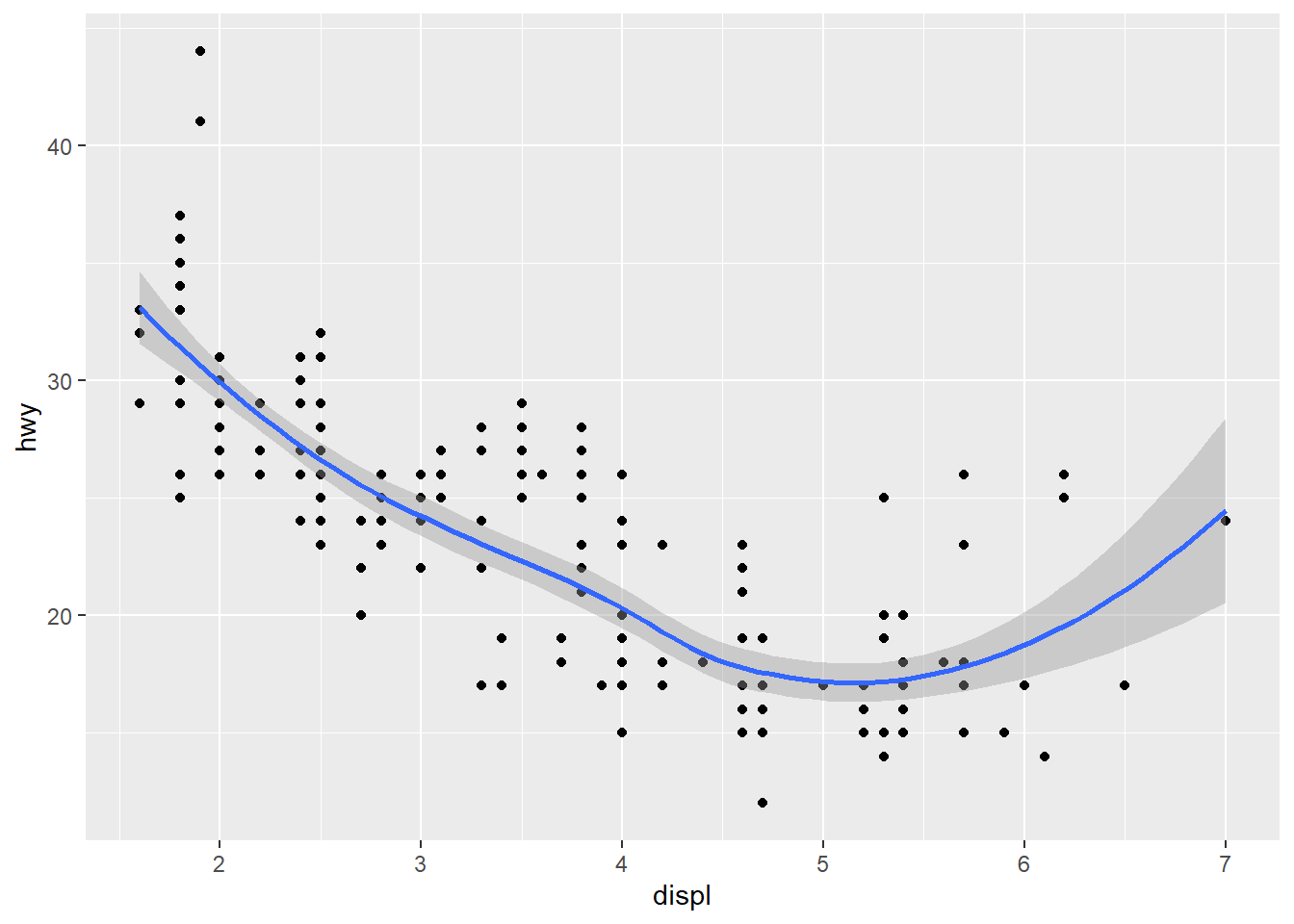
ggplot() +
geom_point(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_smooth(data = mpg, mapping = aes(x = displ, y = hwy))
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
- Tente recriar o seguinte gráfico
## `geom_smooth()` using formula 'y ~ x'
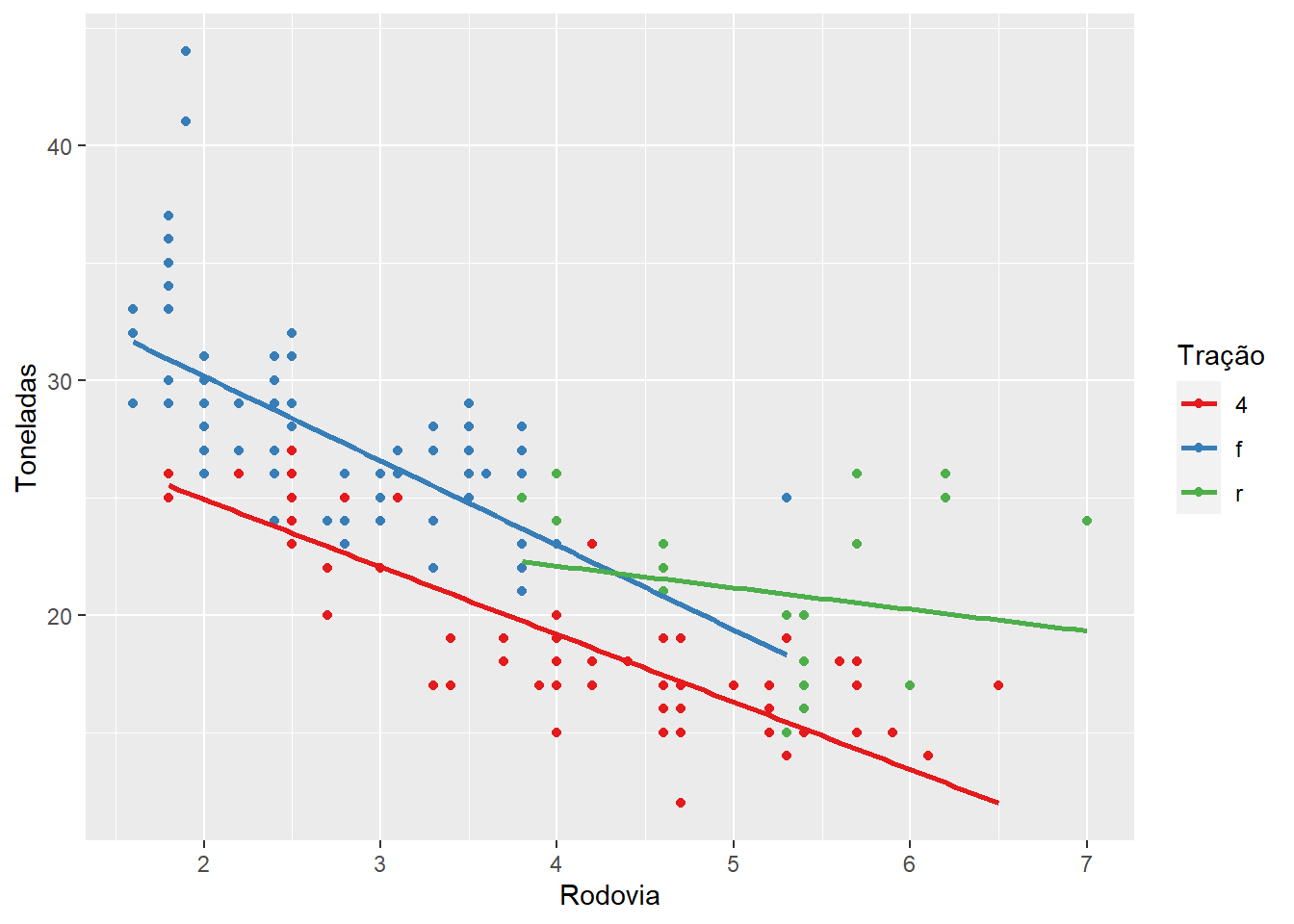
- Transforme o gráfico seguir em um gráfico de pizza usando
coord_polar.
ggplot(diamonds, aes(cut, fill = cut)) +
geom_bar()